 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025



A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
User-Friendly Customized Generation with Multi-Modal Prompts
May 26, 2024



Text-to-image generation models have seen considerable advancement, catering to the increasing interest in personalized image creation. Current customization techniques often necessitate users to provide multiple images (typically 3-5) for each customized object, along with the classification of these objects and descriptive textual prompts for scenes. This paper questions whether the process can be made more user-friendly and the customization more intricate. We propose a method where users need only provide images along with text for each customization topic, and necessitates only a single image per visual concept. We introduce the concept of a ``multi-modal prompt'', a novel integration of text and images tailored to each customization concept, which simplifies user interaction and facilitates precise customization of both objects and scenes. Our proposed paradigm for customized text-to-image generation surpasses existing finetune-based methods in user-friendliness and the ability to customize complex objects with user-friendly inputs. Our code is available at $\href{https://github.com/zhongzero/Multi-Modal-Prompt}{https://github.com/zhongzero/Multi-Modal-Prompt}$.
MarkLLM: An Open-Source Toolkit for LLM Watermarking
May 16, 2024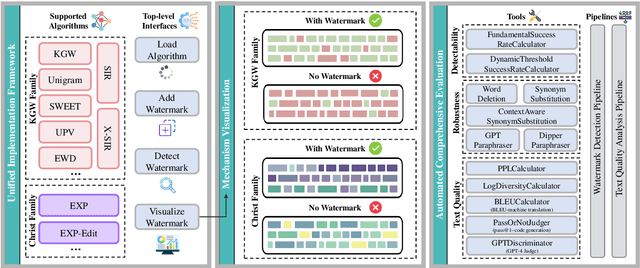
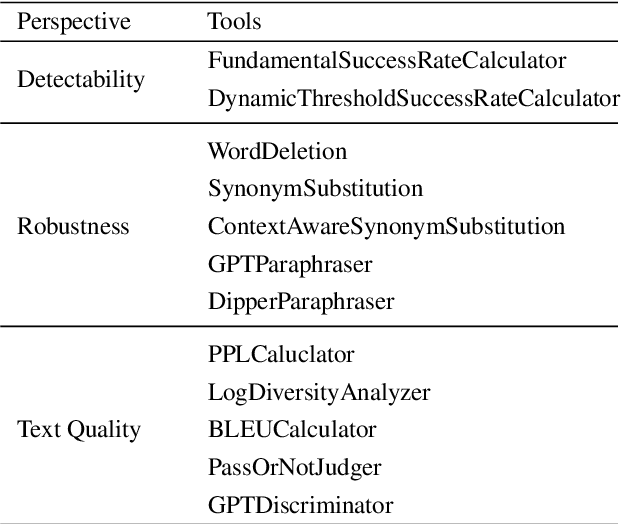
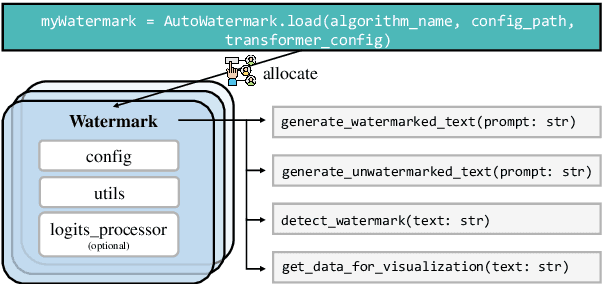
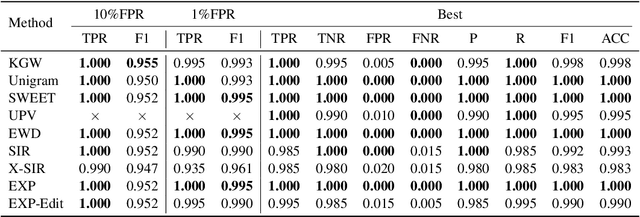
LLM watermarking, which embeds imperceptible yet algorithmically detectable signals in model outputs to identify LLM-generated text, has become crucial in mitigating the potential misuse of large language models. However, the abundance of LLM watermarking algorithms, their intricate mechanisms, and the complex evaluation procedures and perspectives pose challenges for researchers and the community to easily experiment with, understand, and assess the latest advancements. To address these issues, we introduce MarkLLM, an open-source toolkit for LLM watermarking. MarkLLM offers a unified and extensible framework for implementing LLM watermarking algorithms, while providing user-friendly interfaces to ensure ease of access. Furthermore, it enhances understanding by supporting automatic visualization of the underlying mechanisms of these algorithms. For evaluation, MarkLLM offers a comprehensive suite of 12 tools spanning three perspectives, along with two types of automated evaluation pipelines. Through MarkLLM, we aim to support researchers while improving the comprehension and involvement of the general public in LLM watermarking technology, fostering consensus and driving further advancements in research and application. Our code is available at https://github.com/THU-BPM/MarkLLM.
Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models
Feb 21, 2024



Text watermarking technology aims to tag and identify content produced by large language models (LLMs) to prevent misuse. In this study, we introduce the concept of ''cross-lingual consistency'' in text watermarking, which assesses the ability of text watermarks to maintain their effectiveness after being translated into other languages. Preliminary empirical results from two LLMs and three watermarking methods reveal that current text watermarking technologies lack consistency when texts are translated into various languages. Based on this observation, we propose a Cross-lingual Watermark Removal Attack (CWRA) to bypass watermarking by first obtaining a response from an LLM in a pivot language, which is then translated into the target language. CWRA can effectively remove watermarks by reducing the Area Under the Curve (AUC) from 0.95 to 0.67 without performance loss. Furthermore, we analyze two key factors that contribute to the cross-lingual consistency in text watermarking and propose a defense method that increases the AUC from 0.67 to 0.88 under CWRA.
Improve Cross-Architecture Generalization on Dataset Distillation
Feb 20, 2024



Dataset distillation, a pragmatic approach in machine learning, aims to create a smaller synthetic dataset from a larger existing dataset. However, existing distillation methods primarily adopt a model-based paradigm, where the synthetic dataset inherits model-specific biases, limiting its generalizability to alternative models. In response to this constraint, we propose a novel methodology termed "model pool". This approach involves selecting models from a diverse model pool based on a specific probability distribution during the data distillation process. Additionally, we integrate our model pool with the established knowledge distillation approach and apply knowledge distillation to the test process of the distilled dataset. Our experimental results validate the effectiveness of the model pool approach across a range of existing models while testing, demonstrating superior performance compared to existing methodologies.
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
Jan 18, 2024



Large language models (LLMs) have exhibited great potential in autonomously completing tasks across real-world applications. Despite this, these LLM agents introduce unexpected safety risks when operating in interactive environments. Instead of centering on LLM-generated content safety in most prior studies, this work addresses the imperative need for benchmarking the behavioral safety of LLM agents within diverse environments. We introduce R-Judge, a benchmark crafted to evaluate the proficiency of LLMs in judging safety risks given agent interaction records. R-Judge comprises 162 agent interaction records, encompassing 27 key risk scenarios among 7 application categories and 10 risk types. It incorporates human consensus on safety with annotated safety risk labels and high-quality risk descriptions. Utilizing R-Judge, we conduct a comprehensive evaluation of 8 prominent LLMs commonly employed as the backbone for agents. The best-performing model, GPT-4, achieves 72.29% in contrast to the human score of 89.38%, showing considerable room for enhancing the risk awareness of LLMs. Notably, leveraging risk descriptions as environment feedback significantly improves model performance, revealing the importance of salient safety risk feedback. Furthermore, we design an effective chain of safety analysis technique to help the judgment of safety risks and conduct an in-depth case study to facilitate future research. R-Judge is publicly available at https://github.com/Lordog/R-Judge.