 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Uncertainty Sets for Control Dynamics via Set Membership: A Non-Asymptotic Analysis
Sep 26, 2023



Set-membership estimation is commonly used in adaptive/learning-based control algorithms that require robustness over the model uncertainty sets, e.g., online robustly stabilizing control and robust adaptive model predictive control. Despite having broad applications, non-asymptotic estimation error bounds in the stochastic setting are limited. This paper provides such a non-asymptotic bound on the diameter of the uncertainty sets generated by set membership estimation on linear dynamical systems under bounded, i.i.d. disturbances. Further, this result is applied to robust adaptive model predictive control with uncertainty sets updated by set membership. We numerically demonstrate the performance of the robust adaptive controller, which rapidly approaches the performance of the offline optimal model predictive controller, in comparison with the control design based on least square estimation's confidence regions.
Non-asymptotic System Identification for Linear Systems with Nonlinear Policies
Jun 17, 2023

This paper considers a single-trajectory system identification problem for linear systems under general nonlinear and/or time-varying policies with i.i.d. random excitation noises. The problem is motivated by safe learning-based control for constrained linear systems, where the safe policies during the learning process are usually nonlinear and time-varying for satisfying the state and input constraints. In this paper, we provide a non-asymptotic error bound for least square estimation when the data trajectory is generated by any nonlinear and/or time-varying policies as long as the generated state and action trajectories are bounded. This significantly generalizes the existing non-asymptotic guarantees for linear system identification, which usually consider i.i.d. random inputs or linear policies. Interestingly, our error bound is consistent with that for linear policies with respect to the dependence on the trajectory length, system dimensions, and excitation levels. Lastly, we demonstrate the applications of our results by safe learning with robust model predictive control and provide numerical analysis.
Online Hyperparameter Optimization for Class-Incremental Learning
Jan 11, 2023



Class-incremental learning (CIL) aims to train a classification model while the number of classes increases phase-by-phase. An inherent challenge of CIL is the stability-plasticity tradeoff, i.e., CIL models should keep stable to retain old knowledge and keep plastic to absorb new knowledge. However, none of the existing CIL models can achieve the optimal tradeoff in different data-receiving settings--where typically the training-from-half (TFH) setting needs more stability, but the training-from-scratch (TFS) needs more plasticity. To this end, we design an online learning method that can adaptively optimize the tradeoff without knowing the setting as a priori. Specifically, we first introduce the key hyperparameters that influence the trade-off, e.g., knowledge distillation (KD) loss weights, learning rates, and classifier types. Then, we formulate the hyperparameter optimization process as an online Markov Decision Process (MDP) problem and propose a specific algorithm to solve it. We apply local estimated rewards and a classic bandit algorithm Exp3 [4] to address the issues when applying online MDP methods to the CIL protocol. Our method consistently improves top-performing CIL methods in both TFH and TFS settings, e.g., boosting the average accuracy of TFH and TFS by 2.2 percentage points on ImageNet-Full, compared to the state-of-the-art [23].
Mining the Factor Zoo: Estimation of Latent Factor Models with Sufficient Proxies
Jan 03, 2023Latent factor model estimation typically relies on either using domain knowledge to manually pick several observed covariates as factor proxies, or purely conducting multivariate analysis such as principal component analysis. However, the former approach may suffer from the bias while the latter can not incorporate additional information. We propose to bridge these two approaches while allowing the number of factor proxies to diverge, and hence make the latent factor model estimation robust, flexible, and statistically more accurate. As a bonus, the number of factors is also allowed to grow. At the heart of our method is a penalized reduced rank regression to combine information. To further deal with heavy-tailed data, a computationally attractive penalized robust reduced rank regression method is proposed. We establish faster rates of convergence compared with the benchmark. Extensive simulations and real examples are used to illustrate the advantages.
Tele-Knowledge Pre-training for Fault Analysis
Oct 20, 2022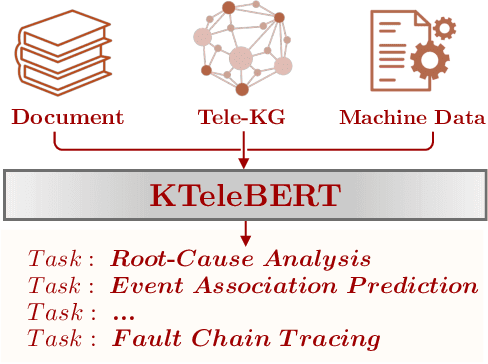
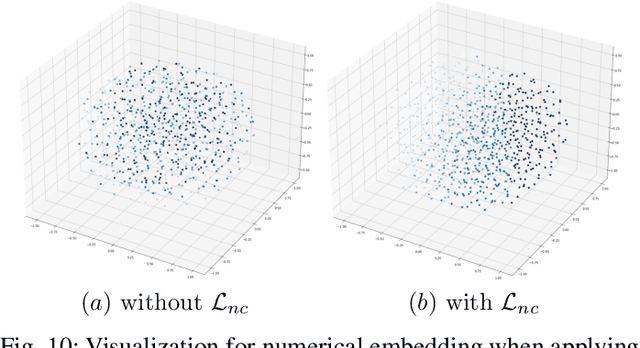
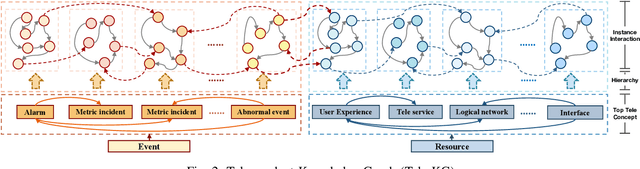

In this work, we share our experience on tele-knowledge pre-training for fault analysis. Fault analysis is a vital task for tele-application, which should be timely and properly handled. Fault analysis is also a complex task, that has many sub-tasks. Solving each task requires diverse tele-knowledge. Machine log data and product documents contain part of the tele-knowledge. We create a Tele-KG to organize other tele-knowledge from experts uniformly. With these valuable tele-knowledge data, in this work, we propose a tele-domain pre-training model KTeleBERT and its knowledge-enhanced version KTeleBERT, which includes effective prompt hints, adaptive numerical data encoding, and two knowledge injection paradigms. We train our model in two stages: pre-training TeleBERT on 20 million telecommunication corpora and re-training TeleBERT on 1 million causal and machine corpora to get the KTeleBERT. Then, we apply our models for three tasks of fault analysis, including root-cause analysis, event association prediction, and fault chain tracing. The results show that with KTeleBERT, the performance of task models has been boosted, demonstrating the effectiveness of pre-trained KTeleBERT as a model containing diverse tele-knowledge.
SoccerNet 2022 Challenges Results
Oct 05, 2022
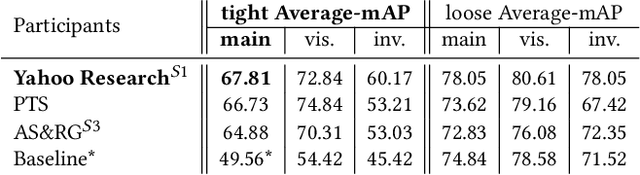
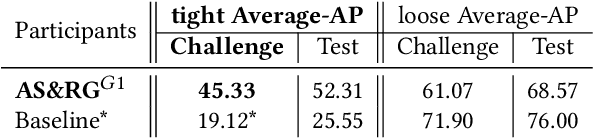
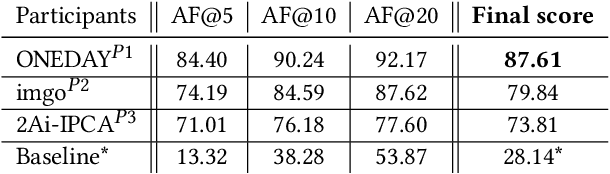
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Rope3D: TheRoadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task
Mar 25, 2022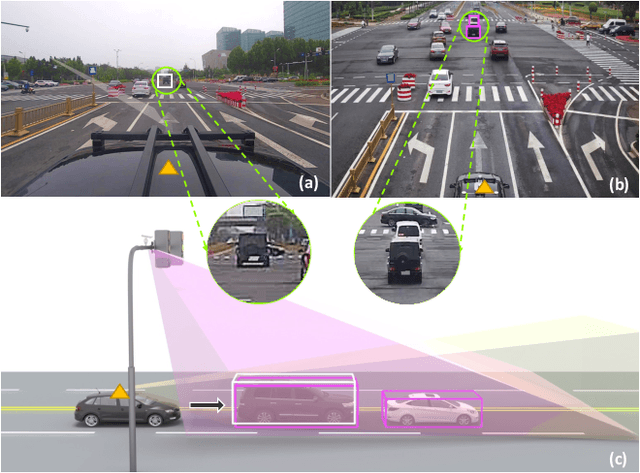
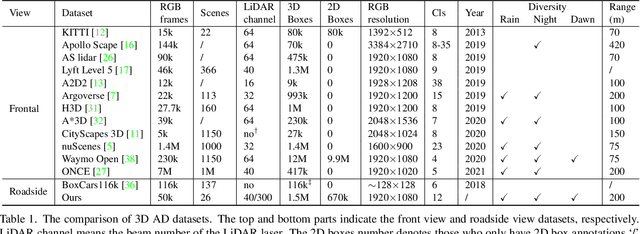

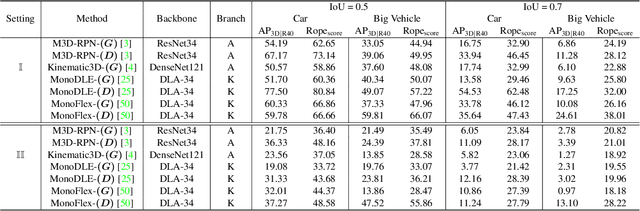
Concurrent perception datasets for autonomous driving are mainly limited to frontal view with sensors mounted on the vehicle. None of them is designed for the overlooked roadside perception tasks. On the other hand, the data captured from roadside cameras have strengths over frontal-view data, which is believed to facilitate a safer and more intelligent autonomous driving system. To accelerate the progress of roadside perception, we present the first high-diversity challenging Roadside Perception 3D dataset- Rope3D from a novel view. The dataset consists of 50k images and over 1.5M 3D objects in various scenes, which are captured under different settings including various cameras with ambiguous mounting positions, camera specifications, viewpoints, and different environmental conditions. We conduct strict 2D-3D joint annotation and comprehensive data analysis, as well as set up a new 3D roadside perception benchmark with metrics and evaluation devkit. Furthermore, we tailor the existing frontal-view monocular 3D object detection approaches and propose to leverage the geometry constraint to solve the inherent ambiguities caused by various sensors, viewpoints. Our dataset is available on https://thudair.baai.ac.cn/rope.
Statistical Learning for Individualized Asset Allocation
Jan 20, 2022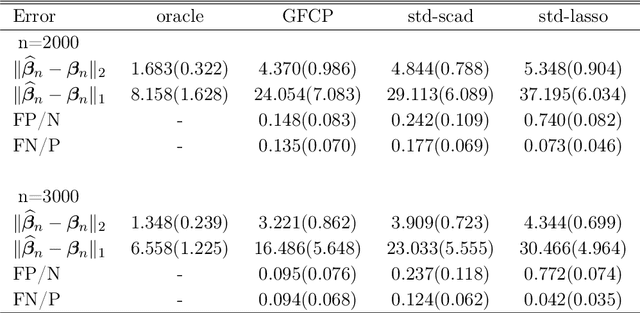
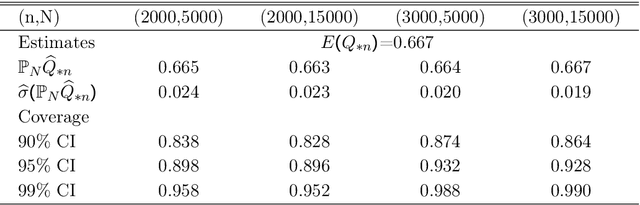
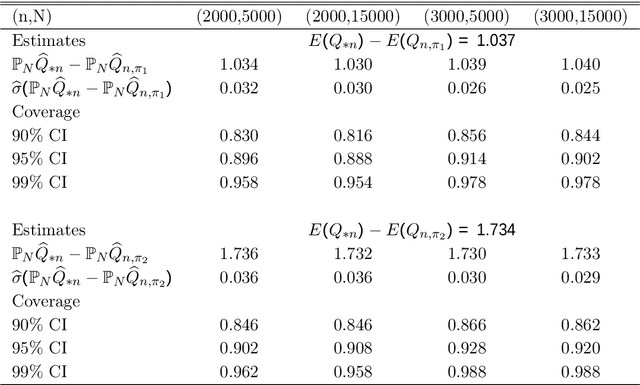
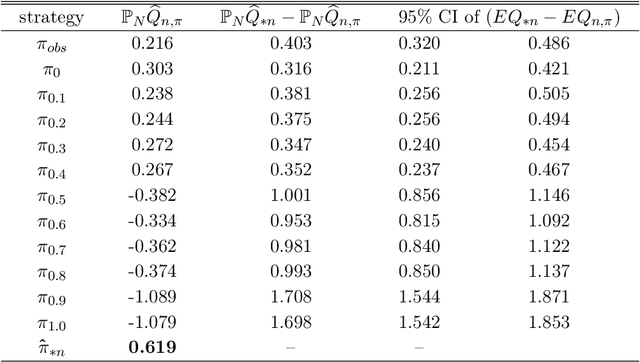
We establish a high-dimensional statistical learning framework for individualized asset allocation. Our proposed methodology addresses continuous-action decision-making with a large number of characteristics. We develop a discretization approach to model the effect from continuous actions and allow the discretization level to be large and diverge with the number of observations. The value function of continuous-action is estimated using penalized regression with generalized penalties that are imposed on linear transformations of the model coefficients. We show that our estimators using generalized folded concave penalties enjoy desirable theoretical properties and allow for statistical inference of the optimal value associated with optimal decision-making. Empirically, the proposed framework is exercised with the Health and Retirement Study data in finding individualized optimal asset allocation. The results show that our individualized optimal strategy improves individual financial well-being and surpasses benchmark strategies.
Safe Adaptive Learning-based Control for Constrained Linear Quadratic Regulators with Regret Guarantees
Oct 31, 2021
We study the adaptive control of an unknown linear system with a quadratic cost function subject to safety constraints on both the states and actions. The challenges of this problem arise from the tension among safety, exploration, performance, and computation. To address these challenges, we propose a polynomial-time algorithm that guarantees feasibility and constraint satisfaction with high probability under proper conditions. Our algorithm is implemented on a single trajectory and does not require system restarts. Further, we analyze the regret of our learning algorithm compared to the optimal safe linear controller with known model information. The proposed algorithm can achieve a $\tilde O(T^{2/3})$ regret, where $T$ is the number of stages and $\tilde O(\cdot)$ absorbs some logarithmic terms of $T$.
Weakly-Supervised Spatio-Temporal Anomaly Detection in Surveillance Video
Aug 09, 2021
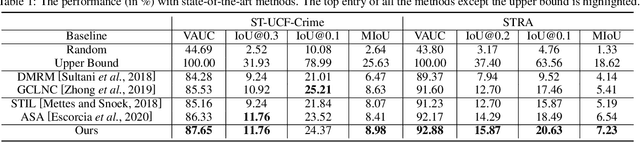
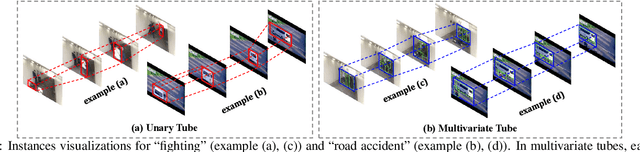
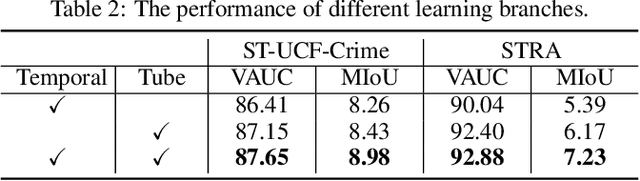
In this paper, we introduce a novel task, referred to as Weakly-Supervised Spatio-Temporal Anomaly Detection (WSSTAD) in surveillance video. Specifically, given an untrimmed video, WSSTAD aims to localize a spatio-temporal tube (i.e., a sequence of bounding boxes at consecutive times) that encloses the abnormal event, with only coarse video-level annotations as supervision during training. To address this challenging task, we propose a dual-branch network which takes as input the proposals with multi-granularities in both spatial-temporal domains. Each branch employs a relationship reasoning module to capture the correlation between tubes/videolets, which can provide rich contextual information and complex entity relationships for the concept learning of abnormal behaviors. Mutually-guided Progressive Refinement framework is set up to employ dual-path mutual guidance in a recurrent manner, iteratively sharing auxiliary supervision information across branches. It impels the learned concepts of each branch to serve as a guide for its counterpart, which progressively refines the corresponding branch and the whole framework. Furthermore, we contribute two datasets, i.e., ST-UCF-Crime and STRA, consisting of videos containing spatio-temporal abnormal annotations to serve as the benchmarks for WSSTAD. We conduct extensive qualitative and quantitative evaluations to demonstrate the effectiveness of the proposed approach and analyze the key factors that contribute more to handle this task.