 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEVAL: A Framework for Evaluating and Improving the Derivation Capability of Large Language Models
Nov 18, 2025Assessing the reasoning ability of Large Language Models (LLMs) over data remains an open and pressing research question. Compared with LLMs, human reasoning can derive corresponding modifications to the output based on certain kinds of changes to the input. This reasoning pattern, which relies on abstract rules that govern relationships between changes of data, has not been comprehensively described or evaluated in LLMs. In this paper, we formally define this reasoning pattern as the Derivation Relation (DR) and introduce the concept of Derivation Capability (DC), i.e. applying DR by making the corresponding modification to the output whenever the input takes certain changes. To assess DC, a systematically constructed evaluation framework named DEVAL is proposed and used to evaluate five popular LLMs and one Large Reasoning Model in seven mainstream tasks. The evaluation results show that mainstream LLMs, such as GPT-4o and Claude3.5, exhibit moderate DR recognition capabilities but reveal significant drop-offs on applying DR effectively in problem-solving scenarios. To improve this, we propose a novel prompt engineering approach called Derivation Prompting (DP). It achieves an average improvement of 15.2% in DC for all tested LLMs, outperforming commonly used prompt engineering techniques.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
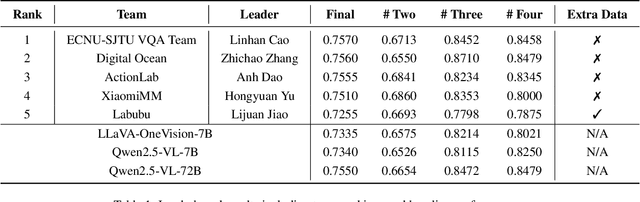
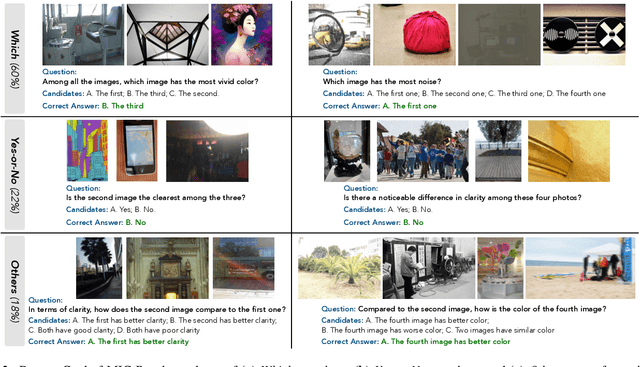
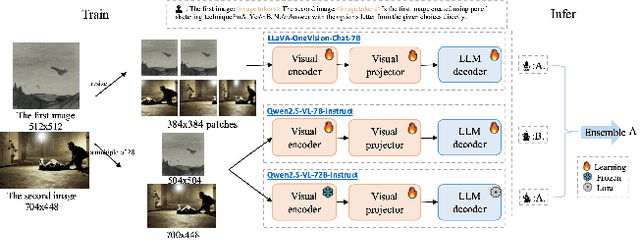
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Do LLMs Really Forget? Evaluating Unlearning with Knowledge Correlation and Confidence Awareness
Jun 06, 2025



Machine unlearning techniques aim to mitigate unintended memorization in large language models (LLMs). However, existing approaches predominantly focus on the explicit removal of isolated facts, often overlooking latent inferential dependencies and the non-deterministic nature of knowledge within LLMs. Consequently, facts presumed forgotten may persist implicitly through correlated information. To address these challenges, we propose a knowledge unlearning evaluation framework that more accurately captures the implicit structure of real-world knowledge by representing relevant factual contexts as knowledge graphs with associated confidence scores. We further develop an inference-based evaluation protocol leveraging powerful LLMs as judges; these judges reason over the extracted knowledge subgraph to determine unlearning success. Our LLM judges utilize carefully designed prompts and are calibrated against human evaluations to ensure their trustworthiness and stability. Extensive experiments on our newly constructed benchmark demonstrate that our framework provides a more realistic and rigorous assessment of unlearning performance. Moreover, our findings reveal that current evaluation strategies tend to overestimate unlearning effectiveness. Our code is publicly available at https://github.com/Graph-COM/Knowledge_Unlearning.git.
IndustryEQA: Pushing the Frontiers of Embodied Question Answering in Industrial Scenarios
May 27, 2025Existing Embodied Question Answering (EQA) benchmarks primarily focus on household environments, often overlooking safety-critical aspects and reasoning processes pertinent to industrial settings. This drawback limits the evaluation of agent readiness for real-world industrial applications. To bridge this, we introduce IndustryEQA, the first benchmark dedicated to evaluating embodied agent capabilities within safety-critical warehouse scenarios. Built upon the NVIDIA Isaac Sim platform, IndustryEQA provides high-fidelity episodic memory videos featuring diverse industrial assets, dynamic human agents, and carefully designed hazardous situations inspired by real-world safety guidelines. The benchmark includes rich annotations covering six categories: equipment safety, human safety, object recognition, attribute recognition, temporal understanding, and spatial understanding. Besides, it also provides extra reasoning evaluation based on these categories. Specifically, it comprises 971 question-answer pairs generated from small warehouse and 373 pairs from large ones, incorporating scenarios with and without human. We further propose a comprehensive evaluation framework, including various baseline models, to assess their general perception and reasoning abilities in industrial environments. IndustryEQA aims to steer EQA research towards developing more robust, safety-aware, and practically applicable embodied agents for complex industrial environments. Benchmark and codes are available.
FastCache: Fast Caching for Diffusion Transformer Through Learnable Linear Approximation
May 26, 2025Diffusion Transformers (DiT) are powerful generative models but remain computationally intensive due to their iterative structure and deep transformer stacks. To alleviate this inefficiency, we propose FastCache, a hidden-state-level caching and compression framework that accelerates DiT inference by exploiting redundancy within the model's internal representations. FastCache introduces a dual strategy: (1) a spatial-aware token selection mechanism that adaptively filters redundant tokens based on hidden state saliency, and (2) a transformer-level cache that reuses latent activations across timesteps when changes are statistically insignificant. These modules work jointly to reduce unnecessary computation while preserving generation fidelity through learnable linear approximation. Theoretical analysis shows that FastCache maintains bounded approximation error under a hypothesis-testing-based decision rule. Empirical evaluations across multiple DiT variants demonstrate substantial reductions in latency and memory usage, with best generation output quality compared to other cache methods, as measured by FID and t-FID. Code implementation of FastCache is available on GitHub at https://github.com/NoakLiu/FastCache-xDiT.
LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges
May 24, 2025Text-to-SQL is a fundamental task in natural language processing that seeks to translate natural language questions into meaningful and executable SQL queries. While existing datasets are extensive and primarily focus on business scenarios and operational logic, they frequently lack coverage of domain-specific knowledge and complex mathematical reasoning. To address this gap, we present a novel dataset tailored for complex reasoning and chain-of-thought analysis in SQL inference, encompassing physical, arithmetic, commonsense, and hypothetical reasoning. The dataset consists of 4,038 English questions, each paired with a unique SQL query and accompanied by 12,114 step-by-step reasoning annotations, spanning 45 databases across diverse domains. Experimental results demonstrate that LogicCat substantially increases the difficulty for state-of-the-art models, with the highest execution accuracy reaching only 14.96%. Incorporating our chain-of-thought annotations boosts performance to 33.96%. Benchmarking leading public methods on Spider and BIRD further underscores the unique challenges presented by LogicCat, highlighting the significant opportunities for advancing research in robust, reasoning-driven text-to-SQL systems. We have released our dataset code at https://github.com/Ffunkytao/LogicCat.
A Deep Learning-Driven Inhalation Injury Grading Assistant Using Bronchoscopy Images
May 15, 2025Inhalation injuries present a challenge in clinical diagnosis and grading due to Conventional grading methods such as the Abbreviated Injury Score (AIS) being subjective and lacking robust correlation with clinical parameters like mechanical ventilation duration and patient mortality. This study introduces a novel deep learning-based diagnosis assistant tool for grading inhalation injuries using bronchoscopy images to overcome subjective variability and enhance consistency in severity assessment. Our approach leverages data augmentation techniques, including graphic transformations, Contrastive Unpaired Translation (CUT), and CycleGAN, to address the scarcity of medical imaging data. We evaluate the classification performance of two deep learning models, GoogLeNet and Vision Transformer (ViT), across a dataset significantly expanded through these augmentation methods. The results demonstrate GoogLeNet combined with CUT as the most effective configuration for grading inhalation injuries through bronchoscopy images and achieves a classification accuracy of 97.8%. The histograms and frequency analysis evaluations reveal variations caused by the augmentation CUT with distribution changes in the histogram and texture details of the frequency spectrum. PCA visualizations underscore the CUT substantially enhances class separability in the feature space. Moreover, Grad-CAM analyses provide insight into the decision-making process; mean intensity for CUT heatmaps is 119.6, which significantly exceeds 98.8 of the original datasets. Our proposed tool leverages mechanical ventilation periods as a novel grading standard, providing comprehensive diagnostic support.
A portable diagnosis model for Keratoconus using a smartphone
May 15, 2025Keratoconus (KC) is a corneal disorder that results in blurry and distorted vision. Traditional diagnostic tools, while effective, are often bulky, costly, and require professional operation. In this paper, we present a portable and innovative methodology for diagnosing. Our proposed approach first captures the image reflected on the eye's cornea when a smartphone screen-generated Placido disc sheds its light on an eye, then utilizes a two-stage diagnosis for identifying the KC cornea and pinpointing the location of the KC on the cornea. The first stage estimates the height and width of the Placido disc extracted from the captured image to identify whether it has KC. In this KC identification, k-means clustering is implemented to discern statistical characteristics, such as height and width values of extracted Placido discs, from non-KC (control) and KC-affected groups. The second stage involves the creation of a distance matrix, providing a precise localization of KC on the cornea, which is critical for efficient treatment planning. The analysis of these distance matrices, paired with a logistic regression model and robust statistical analysis, reveals a clear distinction between control and KC groups. The logistic regression model, which classifies small areas on the cornea as either control or KC-affected based on the corresponding inter-disc distances in the distance matrix, reported a classification accuracy of 96.94%, which indicates that we can effectively pinpoint the protrusion caused by KC. This comprehensive, smartphone-based method is expected to detect KC and streamline timely treatment.
Are We Merely Justifying Results ex Post Facto? Quantifying Explanatory Inversion in Post-Hoc Model Explanations
Apr 11, 2025Post-hoc explanation methods provide interpretation by attributing predictions to input features. Natural explanations are expected to interpret how the inputs lead to the predictions. Thus, a fundamental question arises: Do these explanations unintentionally reverse the natural relationship between inputs and outputs? Specifically, are the explanations rationalizing predictions from the output rather than reflecting the true decision process? To investigate such explanatory inversion, we propose Inversion Quantification (IQ), a framework that quantifies the degree to which explanations rely on outputs and deviate from faithful input-output relationships. Using the framework, we demonstrate on synthetic datasets that widely used methods such as LIME and SHAP are prone to such inversion, particularly in the presence of spurious correlations, across tabular, image, and text domains. Finally, we propose Reproduce-by-Poking (RBP), a simple and model-agnostic enhancement to post-hoc explanation methods that integrates forward perturbation checks. We further show that under the IQ framework, RBP theoretically guarantees the mitigation of explanatory inversion. Empirically, for example, on the synthesized data, RBP can reduce the inversion by 1.8% on average across iconic post-hoc explanation approaches and domains.