 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFM: Building Geospatial Foundation Models via Continual Pretraining
Feb 09, 2023Geospatial technologies are becoming increasingly essential in our world for a large range of tasks, such as earth monitoring and natural disaster response. To help improve the applicability and performance of deep learning models on these geospatial tasks, various works have pursued the idea of a geospatial foundation model, i.e., training networks from scratch on a large corpus of remote sensing imagery. However, this approach often requires a significant amount of data and training time to achieve suitable performance, especially when employing large state-of-the-art transformer models. In light of these challenges, we investigate a sustainable approach to building geospatial foundation models. In our investigations, we discover two important factors in the process. First, we find that the selection of pretraining data matters, even within the geospatial domain. We therefore gather a concise yet effective dataset for pretraining. Second, we find that available pretrained models on diverse datasets like ImageNet-22k should not be ignored when building geospatial foundation models, as their representations are still surprisingly effective. Rather, by leveraging their representations, we can build strong models for geospatial applications in a sustainable manner. To this end, we formulate a multi-objective continual pretraining approach for training sustainable geospatial foundation models. We experiment on a wide variety of downstream datasets and tasks, achieving strong performance across the board in comparison to ImageNet baselines and state-of-the-art geospatial pretrained models.
SimCon Loss with Multiple Views for Text Supervised Semantic Segmentation
Feb 07, 2023



Learning to segment images purely by relying on the image-text alignment from web data can lead to sub-optimal performance due to noise in the data. The noise comes from the samples where the associated text does not correlate with the image's visual content. Instead of purely relying on the alignment from the noisy data, this paper proposes a novel loss function termed SimCon, which accounts for intra-modal similarities to determine the appropriate set of positive samples to align. Further, using multiple views of the image (created synthetically) for training and combining the SimCon loss with it makes the training more robust. This version of the loss is termed MV-SimCon. The empirical results demonstrate that using the proposed loss function leads to consistent improvements on zero-shot, text supervised semantic segmentation and outperforms state-of-the-art by $+3.0\%$, $+3.3\%$ and $+6.9\%$ on PASCAL VOC, PASCAL Context and MSCOCO, respectively. With test time augmentations, we set a new record by improving these results further to $58.7\%$, $26.6\%$, and $33.3\%$ on PASCAL VOC, PASCAL Context, and MSCOCO, respectively. In addition, using the proposed loss function leads to robust training and faster convergence.
AIM: Adapting Image Models for Efficient Video Action Recognition
Feb 06, 2023



Recent vision transformer based video models mostly follow the ``image pre-training then finetuning" paradigm and have achieved great success on multiple video benchmarks. However, full finetuning such a video model could be computationally expensive and unnecessary, given the pre-trained image transformer models have demonstrated exceptional transferability. In this work, we propose a novel method to Adapt pre-trained Image Models (AIM) for efficient video understanding. By freezing the pre-trained image model and adding a few lightweight Adapters, we introduce spatial adaptation, temporal adaptation and joint adaptation to gradually equip an image model with spatiotemporal reasoning capability. We show that our proposed AIM can achieve competitive or even better performance than prior arts with substantially fewer tunable parameters on four video action recognition benchmarks. Thanks to its simplicity, our method is also generally applicable to different image pre-trained models, which has the potential to leverage more powerful image foundation models in the future. The project webpage is \url{https://adapt-image-models.github.io/}.
SuperScaler: Supporting Flexible DNN Parallelization via a Unified Abstraction
Jan 21, 2023



With the growing model size, deep neural networks (DNN) are increasingly trained over massive GPU accelerators, which demands a proper parallelization plan that transforms a DNN model into fine-grained tasks and then schedules them to GPUs for execution. Due to the large search space, the contemporary parallelization plan generators often rely on empirical rules that couple transformation and scheduling, and fall short in exploring more flexible schedules that yield better memory usage and compute efficiency. This tension can be exacerbated by the emerging models with increasing complexity in their structure and model size. SuperScaler is a system that facilitates the design and generation of highly flexible parallelization plans. It formulates the plan design and generation into three sequential phases explicitly: model transformation, space-time scheduling, and data dependency preserving. Such a principled approach decouples multiple seemingly intertwined factors and enables the composition of highly flexible parallelization plans. As a result, SuperScaler can not only generate empirical parallelization plans, but also construct new plans that achieve up to 3.5X speedup compared to state-of-the-art solutions like DeepSpeed, Megatron and Alpa, for emerging DNN models like Swin-Transformer and AlphaFold2, as well as well-optimized models like GPT-3.
SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
Dec 21, 2022



Pre-trained large language models can efficiently interpolate human-written prompts in a natural way. Multitask prompted learning can help generalization through a diverse set of tasks at once, thus enhancing the potential for more effective downstream fine-tuning. To perform efficient multitask-inference in the same batch, parameter-efficient fine-tuning methods such as prompt tuning have been proposed. However, the existing prompt tuning methods may lack generalization. We propose SPT, a semi-parametric prompt tuning method for multitask prompted learning. The novel component of SPT is a memory bank from where memory prompts are retrieved based on discrete prompts. Extensive experiments, such as (i) fine-tuning a full language model with SPT on 31 different tasks from 8 different domains and evaluating zero-shot generalization on 9 heldout datasets under 5 NLP task categories and (ii) pretraining SPT on the GLUE datasets and evaluating fine-tuning on the SuperGLUE datasets, demonstrate effectiveness of SPT.
What Makes for Good Tokenizers in Vision Transformer?
Dec 21, 2022



The architecture of transformers, which recently witness booming applications in vision tasks, has pivoted against the widespread convolutional paradigm. Relying on the tokenization process that splits inputs into multiple tokens, transformers are capable of extracting their pairwise relationships using self-attention. While being the stemming building block of transformers, what makes for a good tokenizer has not been well understood in computer vision. In this work, we investigate this uncharted problem from an information trade-off perspective. In addition to unifying and understanding existing structural modifications, our derivation leads to better design strategies for vision tokenizers. The proposed Modulation across Tokens (MoTo) incorporates inter-token modeling capability through normalization. Furthermore, a regularization objective TokenProp is embraced in the standard training regime. Through extensive experiments on various transformer architectures, we observe both improved performance and intriguing properties of these two plug-and-play designs with negligible computational overhead. These observations further indicate the importance of the commonly-omitted designs of tokenizers in vision transformer.
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022



Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.
CoupAlign: Coupling Word-Pixel with Sentence-Mask Alignments for Referring Image Segmentation
Dec 04, 2022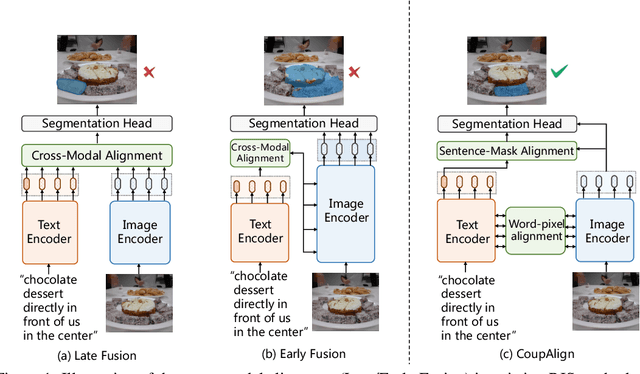
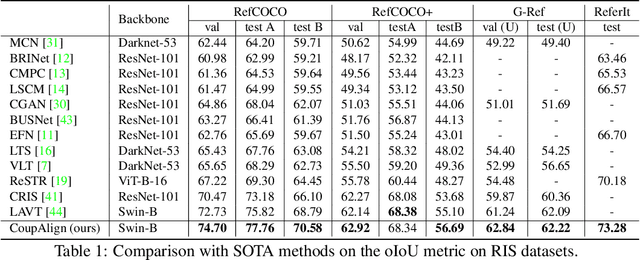
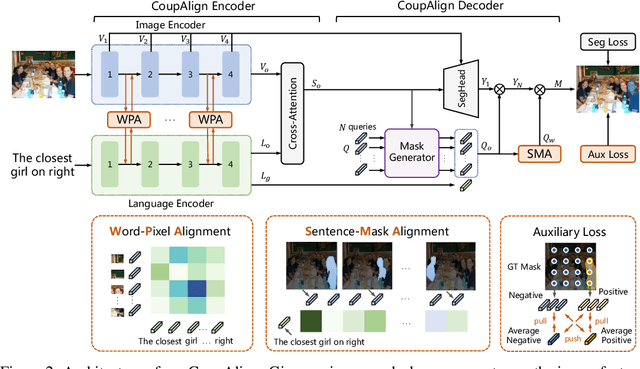

Referring image segmentation aims at localizing all pixels of the visual objects described by a natural language sentence. Previous works learn to straightforwardly align the sentence embedding and pixel-level embedding for highlighting the referred objects, but ignore the semantic consistency of pixels within the same object, leading to incomplete masks and localization errors in predictions. To tackle this problem, we propose CoupAlign, a simple yet effective multi-level visual-semantic alignment method, to couple sentence-mask alignment with word-pixel alignment to enforce object mask constraint for achieving more accurate localization and segmentation. Specifically, the Word-Pixel Alignment (WPA) module performs early fusion of linguistic and pixel-level features in intermediate layers of the vision and language encoders. Based on the word-pixel aligned embedding, a set of mask proposals are generated to hypothesize possible objects. Then in the Sentence-Mask Alignment (SMA) module, the masks are weighted by the sentence embedding to localize the referred object, and finally projected back to aggregate the pixels for the target. To further enhance the learning of the two alignment modules, an auxiliary loss is designed to contrast the foreground and background pixels. By hierarchically aligning pixels and masks with linguistic features, our CoupAlign captures the pixel coherence at both visual and semantic levels, thus generating more accurate predictions. Extensive experiments on popular datasets (e.g., RefCOCO and G-Ref) show that our method achieves consistent improvements over state-of-the-art methods, e.g., about 2% oIoU increase on the validation and testing set of RefCOCO. Especially, CoupAlign has remarkable ability in distinguishing the target from multiple objects of the same class.
Edge Deep Learning Enabled Freezing of Gait Detection in Parkinson's Patients
Nov 27, 2022


This paper presents the design of a wireless sensor network for detecting and alerting the freezing of gait (FoG) symptoms in patients with Parkinson's disease. Three sensor nodes, each integrating a 3-axis accelerometer, can be placed on a patient at ankle, thigh, and truck. Each sensor node can independently detect FoG using an on-device deep learning (DL) model, featuring a squeeze and excitation convolutional neural network (CNN). In a validation using a public dataset, the prototype developed achieved a FoG detection sensitivity of 88.8% and an F1 score of 85.34%, using less than 20 k trainable parameters per sensor node. Once FoG is detected, an auditory signal will be generated to alert users, and the alarm signal will also be sent to mobile phones for further actions if needed. The sensor node can be easily recharged wirelessly by inductive coupling. The system is self-contained and processes all user data locally without streaming data to external devices or the cloud, thus eliminating the cybersecurity risks and power penalty associated with wireless data transmission. The developed methodology can be used in a wide range of applications.
P$^3$OVD: Fine-grained Visual-Text Prompt-Driven Self-Training for Open-Vocabulary Object Detection
Nov 02, 2022Inspired by the success of visual-language methods (VLMs) in zero-shot classification, recent works attempt to extend this line of work into object detection by leveraging the localization ability of pre-trained VLMs and generating pseudo labels for unseen classes in a self-training manner. However, since the current VLMs are usually pre-trained with aligning sentence embedding with global image embedding, the direct use of them lacks fine-grained alignment for object instances, which is the core of detection. In this paper, we propose a simple but effective Pretrain-adaPt-Pseudo labeling paradigm for Open-Vocabulary Detection (P$^3$OVD) that introduces a fine-grained visual-text prompt adapting stage to enhance the current self-training paradigm with a more powerful fine-grained alignment. During the adapting stage, we enable VLM to obtain fine-grained alignment by using learnable text prompts to resolve an auxiliary dense pixel-wise prediction task. Furthermore, we propose a visual prompt module to provide the prior task information (i.e., the categories need to be predicted) for the vision branch to better adapt the pretrained VLM to the downstream tasks. Experiments show that our method achieves the state-of-the-art performance for open-vocabulary object detection, e.g., 31.5% mAP on unseen classes of COCO.