 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Evaluating the Fairness of Discriminative Foundation Models in Computer Vision
Oct 18, 2023We propose a novel taxonomy for bias evaluation of discriminative foundation models, such as Contrastive Language-Pretraining (CLIP), that are used for labeling tasks. We then systematically evaluate existing methods for mitigating bias in these models with respect to our taxonomy. Specifically, we evaluate OpenAI's CLIP and OpenCLIP models for key applications, such as zero-shot classification, image retrieval and image captioning. We categorize desired behaviors based around three axes: (i) if the task concerns humans; (ii) how subjective the task is (i.e., how likely it is that people from a diverse range of backgrounds would agree on a labeling); and (iii) the intended purpose of the task and if fairness is better served by impartiality (i.e., making decisions independent of the protected attributes) or representation (i.e., making decisions to maximize diversity). Finally, we provide quantitative fairness evaluations for both binary-valued and multi-valued protected attributes over ten diverse datasets. We find that fair PCA, a post-processing method for fair representations, works very well for debiasing in most of the aforementioned tasks while incurring only minor loss of performance. However, different debiasing approaches vary in their effectiveness depending on the task. Hence, one should choose the debiasing approach depending on the specific use case.
Leveraging sparse and shared feature activations for disentangled representation learning
Apr 27, 2023



Recovering the latent factors of variation of high dimensional data has so far focused on simple synthetic settings. Mostly building on unsupervised and weakly-supervised objectives, prior work missed out on the positive implications for representation learning on real world data. In this work, we propose to leverage knowledge extracted from a diversified set of supervised tasks to learn a common disentangled representation. Assuming each supervised task only depends on an unknown subset of the factors of variation, we disentangle the feature space of a supervised multi-task model, with features activating sparsely across different tasks and information being shared as appropriate. Importantly, we never directly observe the factors of variations but establish that access to multiple tasks is sufficient for identifiability under sufficiency and minimality assumptions. We validate our approach on six real world distribution shift benchmarks, and different data modalities (images, text), demonstrating how disentangled representations can be transferred to real settings.
A data augmentation perspective on diffusion models and retrieval
Apr 20, 2023Diffusion models excel at generating photorealistic images from text-queries. Naturally, many approaches have been proposed to use these generative abilities to augment training datasets for downstream tasks, such as classification. However, diffusion models are themselves trained on large noisily supervised, but nonetheless, annotated datasets. It is an open question whether the generalization capabilities of diffusion models beyond using the additional data of the pre-training process for augmentation lead to improved downstream performance. We perform a systematic evaluation of existing methods to generate images from diffusion models and study new extensions to assess their benefit for data augmentation. While we find that personalizing diffusion models towards the target data outperforms simpler prompting strategies, we also show that using the training data of the diffusion model alone, via a simple nearest neighbor retrieval procedure, leads to even stronger downstream performance. Overall, our study probes the limitations of diffusion models for data augmentation but also highlights its potential in generating new training data to improve performance on simple downstream vision tasks.
Multi-Symmetry Ensembles: Improving Diversity and Generalization via Opposing Symmetries
Mar 04, 2023



Deep ensembles (DE) have been successful in improving model performance by learning diverse members via the stochasticity of random initialization. While recent works have attempted to promote further diversity in DE via hyperparameters or regularizing loss functions, these methods primarily still rely on a stochastic approach to explore the hypothesis space. In this work, we present Multi-Symmetry Ensembles (MSE), a framework for constructing diverse ensembles by capturing the multiplicity of hypotheses along symmetry axes, which explore the hypothesis space beyond stochastic perturbations of model weights and hyperparameters. We leverage recent advances in contrastive representation learning to create models that separately capture opposing hypotheses of invariant and equivariant symmetries and present a simple ensembling approach to efficiently combine appropriate hypotheses for a given task. We show that MSE effectively captures the multiplicity of conflicting hypotheses that is often required in large, diverse datasets like ImageNet. As a result of their inherent diversity, MSE improves classification performance, uncertainty quantification, and generalization across a series of transfer tasks.
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022



Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022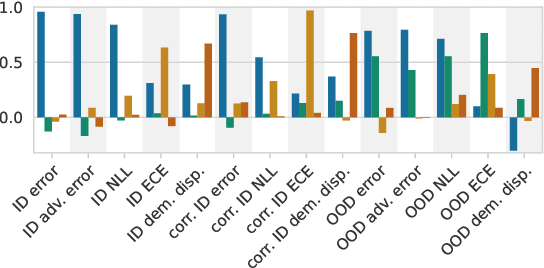
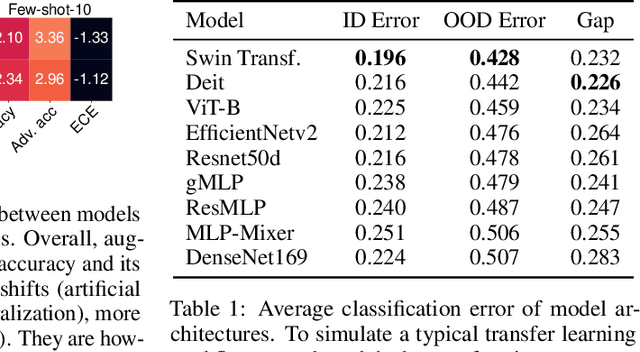
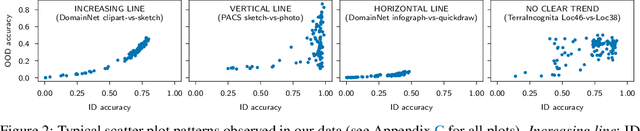
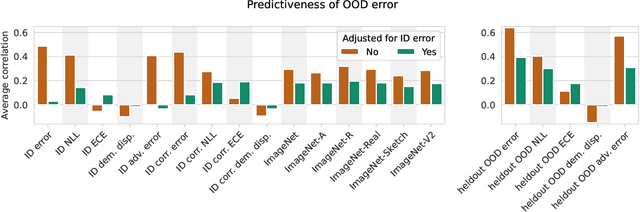
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
Sparse MoEs meet Efficient Ensembles
Oct 07, 2021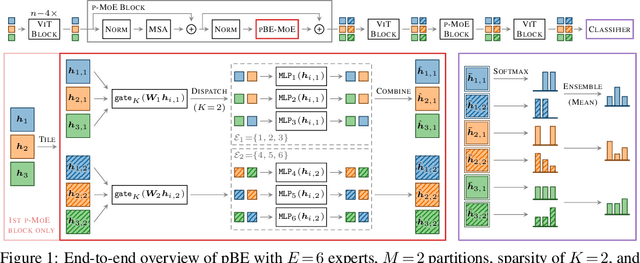

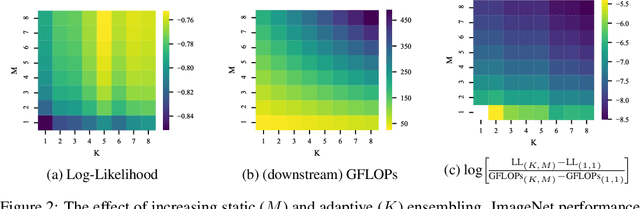
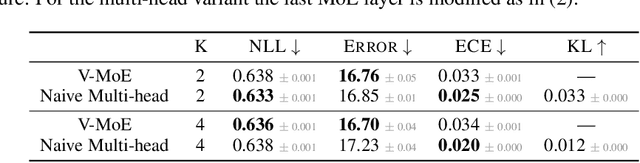
Machine learning models based on the aggregated outputs of submodels, either at the activation or prediction levels, lead to strong performance. We study the interplay of two popular classes of such models: ensembles of neural networks and sparse mixture of experts (sparse MoEs). First, we show that these two approaches have complementary features whose combination is beneficial. Then, we present partitioned batch ensembles, an efficient ensemble of sparse MoEs that takes the best of both classes of models. Extensive experiments on fine-tuned vision transformers demonstrate the accuracy, log-likelihood, few-shot learning, robustness, and uncertainty calibration improvements of our approach over several challenging baselines. Partitioned batch ensembles not only scale to models with up to 2.7B parameters, but also provide larger performance gains for larger models.
Deep Classifiers with Label Noise Modeling and Distance Awareness
Oct 06, 2021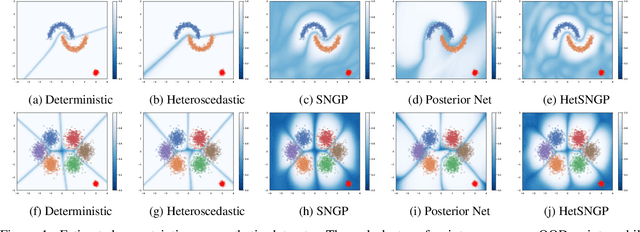



Uncertainty estimation in deep learning has recently emerged as a crucial area of interest to advance reliability and robustness in safety-critical applications. While there have been many proposed methods that either focus on distance-aware model uncertainties for out-of-distribution detection or on input-dependent label uncertainties for in-distribution calibration, both of these types of uncertainty are often necessary. In this work, we propose the HetSNGP method for jointly modeling the model and data uncertainty. We show that our proposed model affords a favorable combination between these two complementary types of uncertainty and thus outperforms the baseline methods on some challenging out-of-distribution datasets, including CIFAR-100C, Imagenet-C, and Imagenet-A. Moreover, we propose HetSNGP Ensemble, an ensembled version of our method which adds an additional type of uncertainty and also outperforms other ensemble baselines.
On Stein Variational Neural Network Ensembles
Jun 22, 2021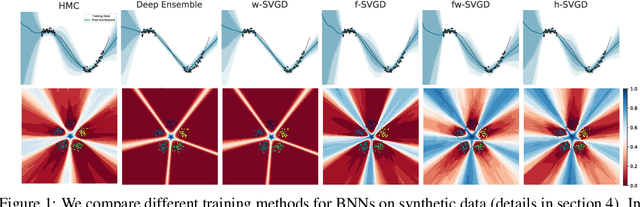
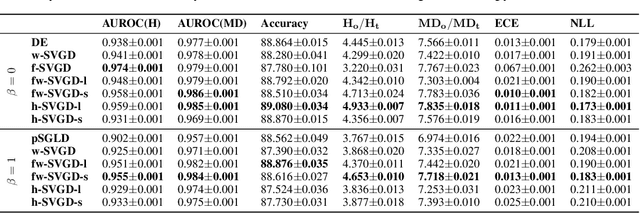
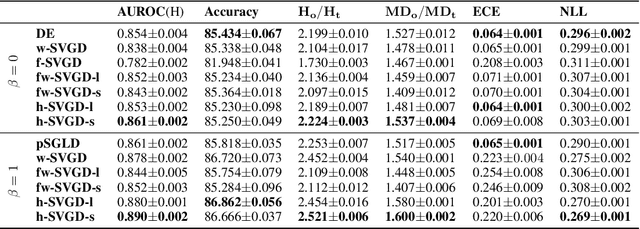
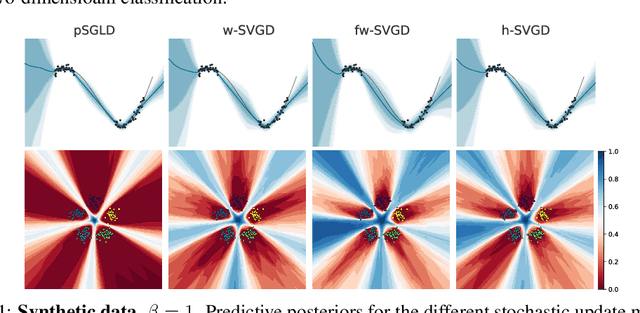
Ensembles of deep neural networks have achieved great success recently, but they do not offer a proper Bayesian justification. Moreover, while they allow for averaging of predictions over several hypotheses, they do not provide any guarantees for their diversity, leading to redundant solutions in function space. In contrast, particle-based inference methods, such as Stein variational gradient descent (SVGD), offer a Bayesian framework, but rely on the choice of a kernel to measure the similarity between ensemble members. In this work, we study different SVGD methods operating in the weight space, function space, and in a hybrid setting. We compare the SVGD approaches to other ensembling-based methods in terms of their theoretical properties and assess their empirical performance on synthetic and real-world tasks. We find that SVGD using functional and hybrid kernels can overcome the limitations of deep ensembles. It improves on functional diversity and uncertainty estimation and approaches the true Bayesian posterior more closely. Moreover, we show that using stochastic SVGD updates, as opposed to the standard deterministic ones, can further improve the performance.