 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perception
Mar 07, 2023



Semantic occupancy perception is essential for autonomous driving, as automated vehicles require a fine-grained perception of the 3D urban structures. However, existing relevant benchmarks lack diversity in urban scenes, and they only evaluate front-view predictions. Towards a comprehensive benchmarking of surrounding perception algorithms, we propose OpenOccupancy, which is the first surrounding semantic occupancy perception benchmark. In the OpenOccupancy benchmark, we extend the large-scale nuScenes dataset with dense semantic occupancy annotations. Previous annotations rely on LiDAR points superimposition, where some occupancy labels are missed due to sparse LiDAR channels. To mitigate the problem, we introduce the Augmenting And Purifying (AAP) pipeline to ~2x densify the annotations, where ~4000 human hours are involved in the labeling process. Besides, camera-based, LiDAR-based and multi-modal baselines are established for the OpenOccupancy benchmark. Furthermore, considering the complexity of surrounding occupancy perception lies in the computational burden of high-resolution 3D predictions, we propose the Cascade Occupancy Network (CONet) to refine the coarse prediction, which relatively enhances the performance by ~30% than the baseline. We hope the OpenOccupancy benchmark will boost the development of surrounding occupancy perception algorithms.
Fast Beam Alignment via Pure Exploration in Multi-armed Bandits
Oct 23, 2022The beam alignment (BA) problem consists in accurately aligning the transmitter and receiver beams to establish a reliable communication link in wireless communication systems. Existing BA methods search the entire beam space to identify the optimal transmit-receive beam pair. This incurs a significant latency when the number of antennas is large. In this work, we develop a bandit-based fast BA algorithm to reduce BA latency for millimeter-wave (mmWave) communications. Our algorithm is named Two-Phase Heteroscedastic Track-and-Stop (2PHT\&S). We first formulate the BA problem as a pure exploration problem in multi-armed bandits in which the objective is to minimize the required number of time steps given a certain fixed confidence level. By taking advantage of the correlation structure among beams that the information from nearby beams is similar and the heteroscedastic property that the variance of the reward of an arm (beam) is related to its mean, the proposed algorithm groups all beams into several beam sets such that the optimal beam set is first selected and the optimal beam is identified in this set after that. Theoretical analysis and simulation results on synthetic and semi-practical channel data demonstrate the clear superiority of the proposed algorithm vis-\`a-vis other baseline competitors.
Smart Explorer: Recognizing Objects in Dense Clutter via Interactive Exploration
Aug 06, 2022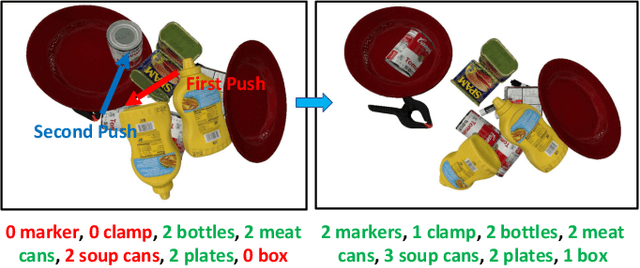
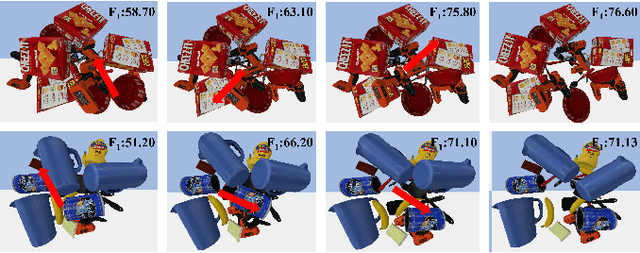
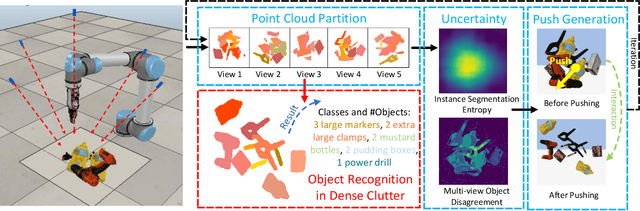
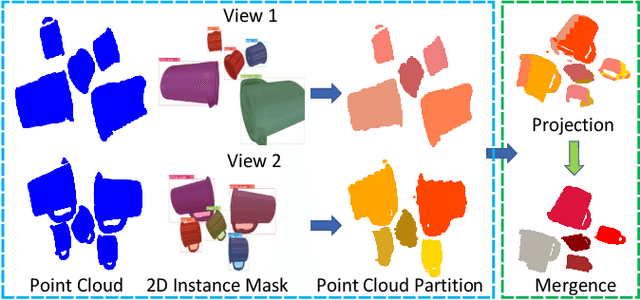
Recognizing objects in dense clutter accurately plays an important role to a wide variety of robotic manipulation tasks including grasping, packing, rearranging and many others. However, conventional visual recognition models usually miss objects because of the significant occlusion among instances and causes incorrect prediction due to the visual ambiguity with the high object crowdedness. In this paper, we propose an interactive exploration framework called Smart Explorer for recognizing all objects in dense clutters. Our Smart Explorer physically interacts with the clutter to maximize the recognition performance while minimize the number of motions, where the false positives and negatives can be alleviated effectively with the optimal accuracy-efficiency trade-offs. Specifically, we first collect the multi-view RGB-D images of the clutter and reconstruct the corresponding point cloud. By aggregating the instance segmentation of RGB images across views, we acquire the instance-wise point cloud partition of the clutter through which the existed classes and the number of objects for each class are predicted. The pushing actions for effective physical interaction are generated to sizably reduce the recognition uncertainty that consists of the instance segmentation entropy and multi-view object disagreement. Therefore, the optimal accuracy-efficiency trade-off of object recognition in dense clutter is achieved via iterative instance prediction and physical interaction. Extensive experiments demonstrate that our Smart Explorer acquires promising recognition accuracy with only a few actions, which also outperforms the random pushing by a large margin.
SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation
Apr 07, 2022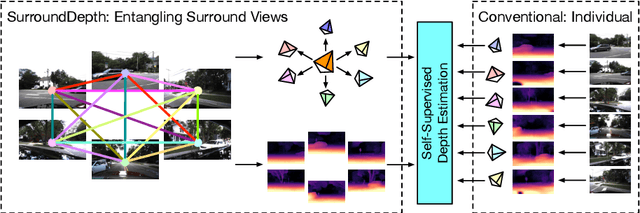
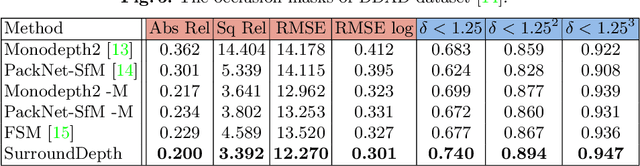
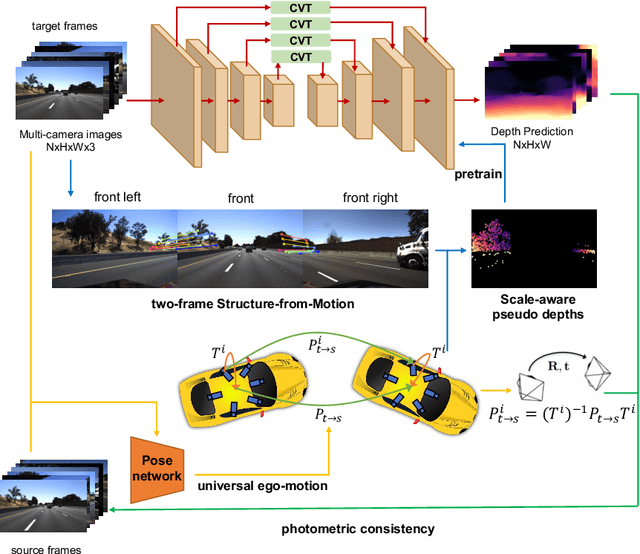

Depth estimation from images serves as the fundamental step of 3D perception for autonomous driving and is an economical alternative to expensive depth sensors like LiDAR. The temporal photometric consistency enables self-supervised depth estimation without labels, further facilitating its application. However, most existing methods predict the depth solely based on each monocular image and ignore the correlations among multiple surrounding cameras, which are typically available for modern self-driving vehicles. In this paper, we propose a SurroundDepth method to incorporate the information from multiple surrounding views to predict depth maps across cameras. Specifically, we employ a joint network to process all the surrounding views and propose a cross-view transformer to effectively fuse the information from multiple views. We apply cross-view self-attention to efficiently enable the global interactions between multi-camera feature maps. Different from self-supervised monocular depth estimation, we are able to predict real-world scales given multi-camera extrinsic matrices. To achieve this goal, we adopt structure-from-motion to extract scale-aware pseudo depths to pretrain the models. Further, instead of predicting the ego-motion of each individual camera, we estimate a universal ego-motion of the vehicle and transfer it to each view to achieve multi-view consistency. In experiments, our method achieves the state-of-the-art performance on the challenging multi-camera depth estimation datasets DDAD and nuScenes.
LiDAR Distillation: Bridging the Beam-Induced Domain Gap for 3D Object Detection
Mar 28, 2022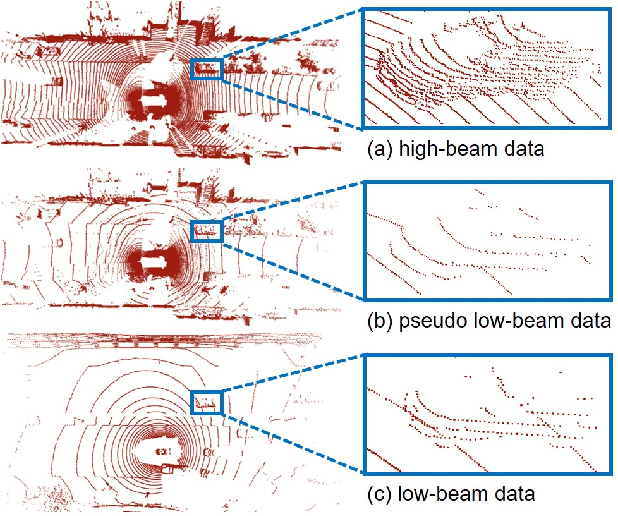
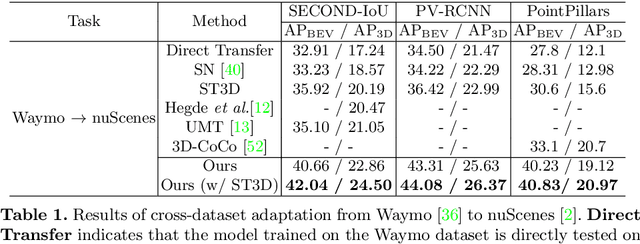
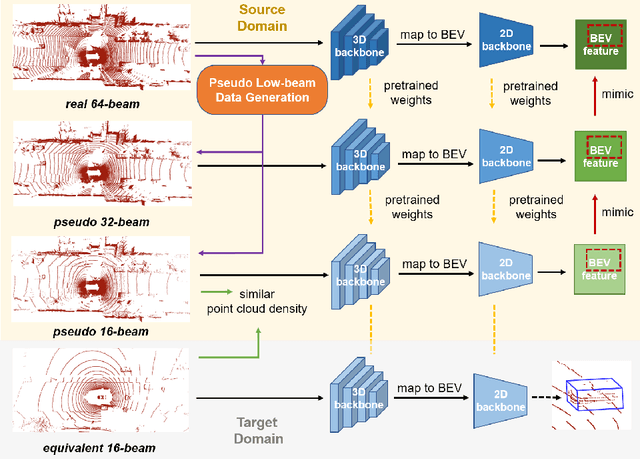

In this paper, we propose the LiDAR Distillation to bridge the domain gap induced by different LiDAR beams for 3D object detection. In many real-world applications, the LiDAR points used by mass-produced robots and vehicles usually have fewer beams than that in large-scale public datasets. Moreover, as the LiDARs are upgraded to other product models with different beam amount, it becomes challenging to utilize the labeled data captured by previous versions' high-resolution sensors. Despite the recent progress on domain adaptive 3D detection, most methods struggle to eliminate the beam-induced domain gap. We find that it is essential to align the point cloud density of the source domain with that of the target domain during the training process. Inspired by this discovery, we propose a progressive framework to mitigate the beam-induced domain shift. In each iteration, we first generate low-beam pseudo LiDAR by downsampling the high-beam point clouds. Then the teacher-student framework is employed to distill rich information from the data with more beams. Extensive experiments on Waymo, nuScenes and KITTI datasets with three different LiDAR-based detectors demonstrate the effectiveness of our LiDAR Distillation. Notably, our approach does not increase any additional computation cost for inference.
Channel Tracking and Prediction for IRS-aided Wireless Communications
Mar 11, 2022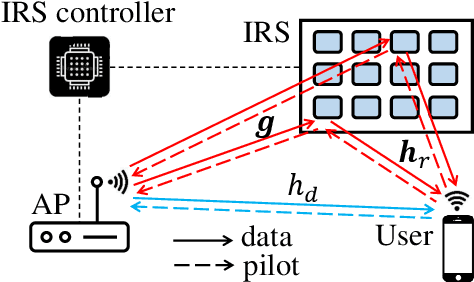
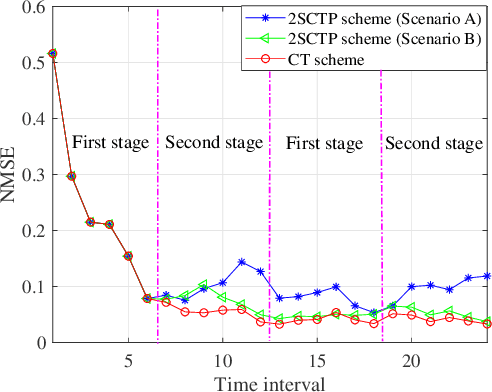
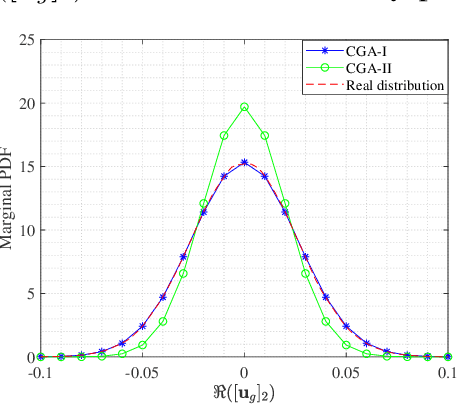
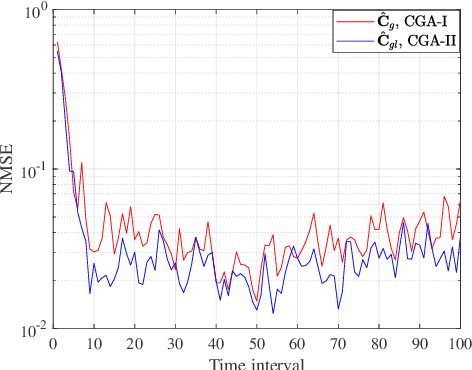
For intelligent reflecting surface (IRS)-aided wireless communications, channel estimation is essential and usually requires excessive channel training overhead when the number of IRS reflecting elements is large. The acquisition of accurate channel state information (CSI) becomes more challenging when the channel is not quasi-static due to the mobility of the transmitter and/or receiver. In this work, we study an IRS-aided wireless communication system with a time-varying channel model and propose an innovative two-stage transmission protocol. In the first stage, we send pilot symbols and track the direct/reflected channels based on the received signal, and then data signals are transmitted. In the second stage, instead of sending pilot symbols first, we directly predict the direct/reflected channels and all the time slots are used for data transmission. Based on the proposed transmission protocol, we propose a two-stage channel tracking and prediction (2SCTP) scheme to obtain the direct and reflected channels with low channel training overhead, which is achieved by exploiting the temporal correlation of the time-varying channels. Specifically, we first consider a special case where the IRS-access point (AP) channel is assumed to be static, for which a Kalman filter (KF)-based algorithm and a long short-term memory (LSTM)-based neural network are proposed for channel tracking and prediction, respectively. Then, for the more general case where the IRS-AP, user-IRS and user-AP channels are all assumed to be time-varying, we present a generalized KF (GKF)-based channel tracking algorithm, where proper approximations are employed to handle the underlying non-Gaussian random variables. Numerical simulations are provided to verify the effectiveness of our proposed transmission protocol and channel tracking/prediction algorithms as compared to existing ones.
A Confidence-based Iterative Solver of Depths and Surface Normals for Deep Multi-view Stereo
Jan 19, 2022
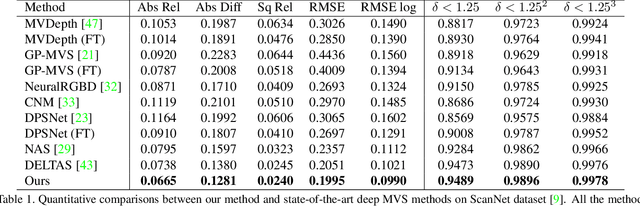
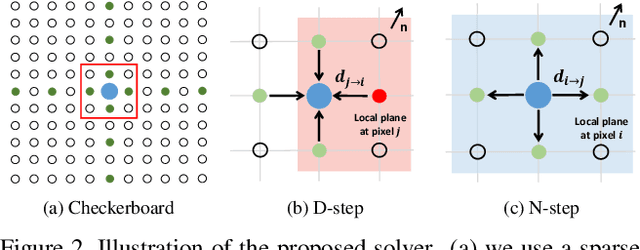
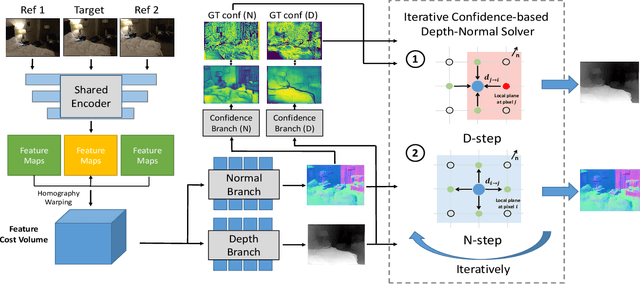
In this paper, we introduce a deep multi-view stereo (MVS) system that jointly predicts depths, surface normals and per-view confidence maps. The key to our approach is a novel solver that iteratively solves for per-view depth map and normal map by optimizing an energy potential based on the locally planar assumption. Specifically, the algorithm updates depth map by propagating from neighboring pixels with slanted planes, and updates normal map with local probabilistic plane fitting. Both two steps are monitored by a customized confidence map. This solver is not only effective as a post-processing tool for plane-based depth refinement and completion, but also differentiable such that it can be efficiently integrated into deep learning pipelines. Our multi-view stereo system employs multiple optimization steps of the solver over the initial prediction of depths and surface normals. The whole system can be trained end-to-end, decoupling the challenging problem of matching pixels within poorly textured regions from the cost-volume based neural network. Experimental results on ScanNet and RGB-D Scenes V2 demonstrate state-of-the-art performance of the proposed deep MVS system on multi-view depth estimation, with our proposed solver consistently improving the depth quality over both conventional and deep learning based MVS pipelines. Code is available at https://github.com/thuzhaowang/idn-solver.
Mind the Gap: Cross-Lingual Information Retrieval with Hierarchical Knowledge Enhancement
Dec 27, 2021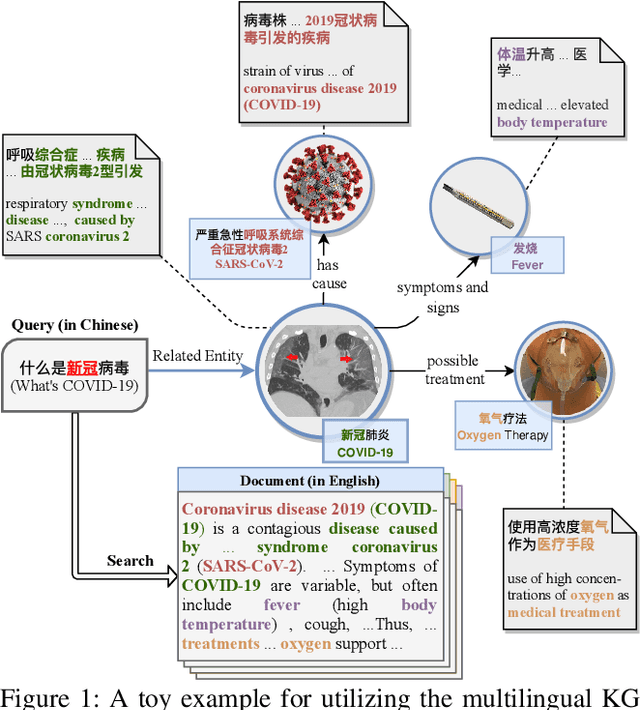
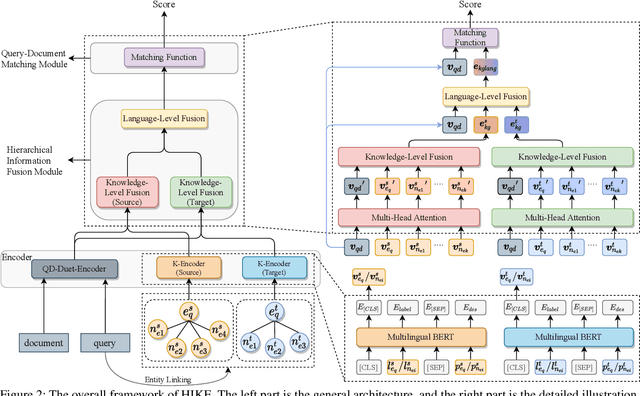
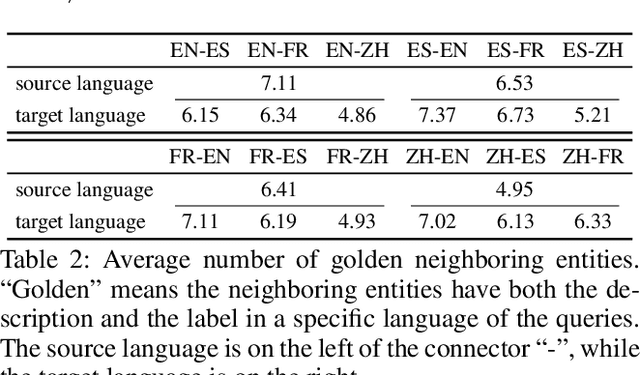
Cross-Lingual Information Retrieval (CLIR) aims to rank the documents written in a language different from the user's query. The intrinsic gap between different languages is an essential challenge for CLIR. In this paper, we introduce the multilingual knowledge graph (KG) to the CLIR task due to the sufficient information of entities in multiple languages. It is regarded as a "silver bullet" to simultaneously perform explicit alignment between queries and documents and also broaden the representations of queries. And we propose a model named CLIR with hierarchical knowledge enhancement (HIKE) for our task. The proposed model encodes the textual information in queries, documents and the KG with multilingual BERT, and incorporates the KG information in the query-document matching process with a hierarchical information fusion mechanism. Particularly, HIKE first integrates the entities and their neighborhood in KG into query representations with a knowledge-level fusion, then combines the knowledge from both source and target languages to further mitigate the linguistic gap with a language-level fusion. Finally, experimental results demonstrate that HIKE achieves substantial improvements over state-of-the-art competitors.
NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo
Sep 03, 2021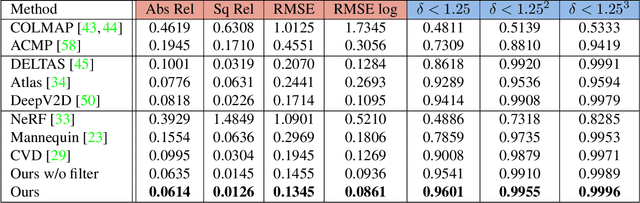
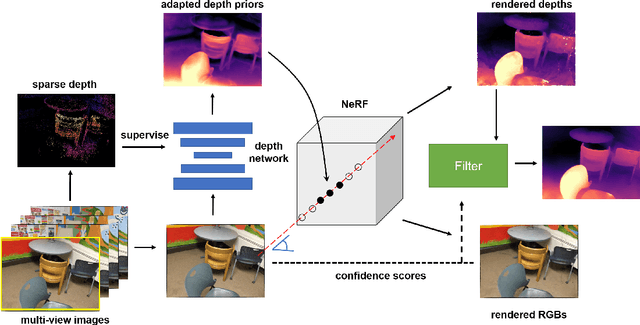
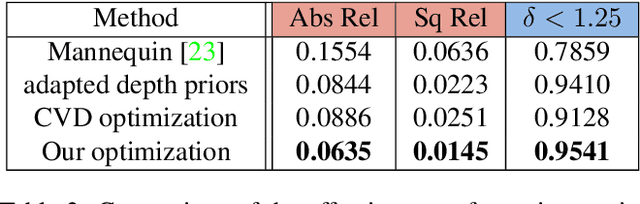
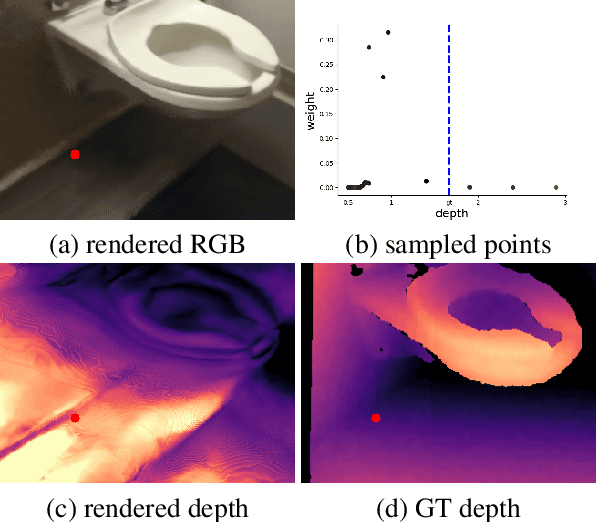
In this work, we present a new multi-view depth estimation method that utilizes both conventional SfM reconstruction and learning-based priors over the recently proposed neural radiance fields (NeRF). Unlike existing neural network based optimization method that relies on estimated correspondences, our method directly optimizes over implicit volumes, eliminating the challenging step of matching pixels in indoor scenes. The key to our approach is to utilize the learning-based priors to guide the optimization process of NeRF. Our system firstly adapts a monocular depth network over the target scene by finetuning on its sparse SfM reconstruction. Then, we show that the shape-radiance ambiguity of NeRF still exists in indoor environments and propose to address the issue by employing the adapted depth priors to monitor the sampling process of volume rendering. Finally, a per-pixel confidence map acquired by error computation on the rendered image can be used to further improve the depth quality. Experiments show that our proposed framework significantly outperforms state-of-the-art methods on indoor scenes, with surprising findings presented on the effectiveness of correspondence-based optimization and NeRF-based optimization over the adapted depth priors. In addition, we show that the guided optimization scheme does not sacrifice the original synthesis capability of neural radiance fields, improving the rendering quality on both seen and novel views. Code is available at https://github.com/weiyithu/NerfingMVS.
RandomRooms: Unsupervised Pre-training from Synthetic Shapes and Randomized Layouts for 3D Object Detection
Aug 17, 2021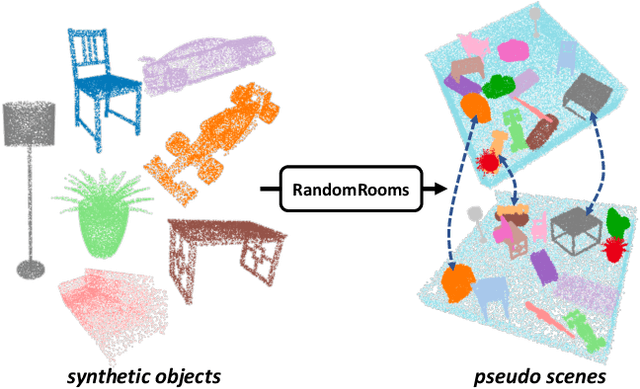

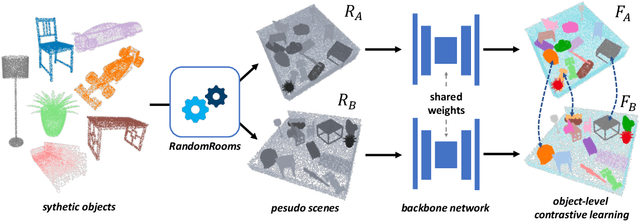
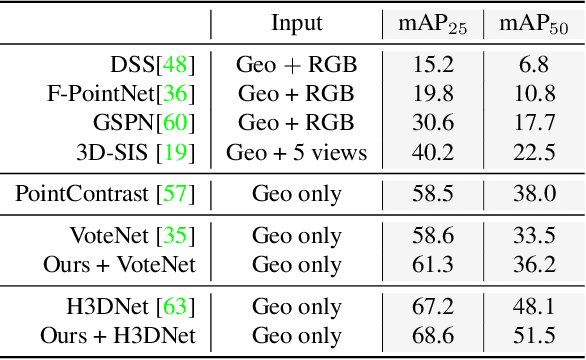
3D point cloud understanding has made great progress in recent years. However, one major bottleneck is the scarcity of annotated real datasets, especially compared to 2D object detection tasks, since a large amount of labor is involved in annotating the real scans of a scene. A promising solution to this problem is to make better use of the synthetic dataset, which consists of CAD object models, to boost the learning on real datasets. This can be achieved by the pre-training and fine-tuning procedure. However, recent work on 3D pre-training exhibits failure when transfer features learned on synthetic objects to other real-world applications. In this work, we put forward a new method called RandomRooms to accomplish this objective. In particular, we propose to generate random layouts of a scene by making use of the objects in the synthetic CAD dataset and learn the 3D scene representation by applying object-level contrastive learning on two random scenes generated from the same set of synthetic objects. The model pre-trained in this way can serve as a better initialization when later fine-tuning on the 3D object detection task. Empirically, we show consistent improvement in downstream 3D detection tasks on several base models, especially when less training data are used, which strongly demonstrates the effectiveness and generalization of our method. Benefiting from the rich semantic knowledge and diverse objects from synthetic data, our method establishes the new state-of-the-art on widely-used 3D detection benchmarks ScanNetV2 and SUN RGB-D. We expect our attempt to provide a new perspective for bridging object and scene-level 3D understanding.