 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Syntactic Multi-Modality in Non-Autoregressive Machine Translation
Jul 09, 2022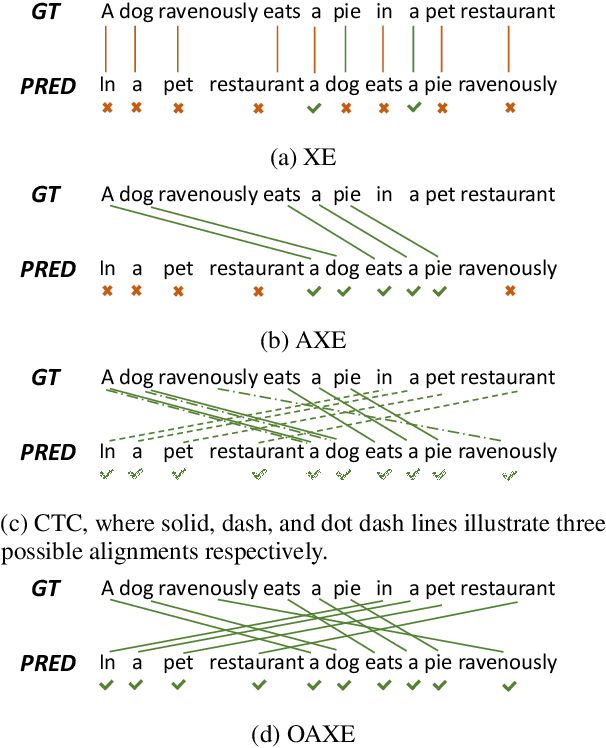
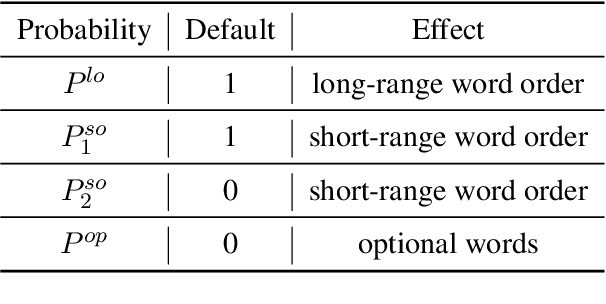
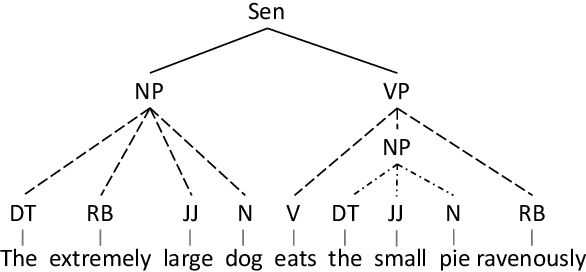
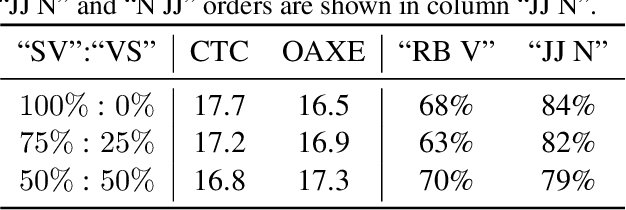
It is difficult for non-autoregressive translation (NAT) models to capture the multi-modal distribution of target translations due to their conditional independence assumption, which is known as the "multi-modality problem", including the lexical multi-modality and the syntactic multi-modality. While the first one has been well studied, the syntactic multi-modality brings severe challenge to the standard cross entropy (XE) loss in NAT and is under studied. In this paper, we conduct a systematic study on the syntactic multi-modality problem. Specifically, we decompose it into short- and long-range syntactic multi-modalities and evaluate several recent NAT algorithms with advanced loss functions on both carefully designed synthesized datasets and real datasets. We find that the Connectionist Temporal Classification (CTC) loss and the Order-Agnostic Cross Entropy (OAXE) loss can better handle short- and long-range syntactic multi-modalities respectively. Furthermore, we take the best of both and design a new loss function to better handle the complicated syntactic multi-modality in real-world datasets. To facilitate practical usage, we provide a guide to use different loss functions for different kinds of syntactic multi-modality.
Approximating Discontinuous Nash Equilibrial Values of Two-Player General-Sum Differential Games
Jul 05, 2022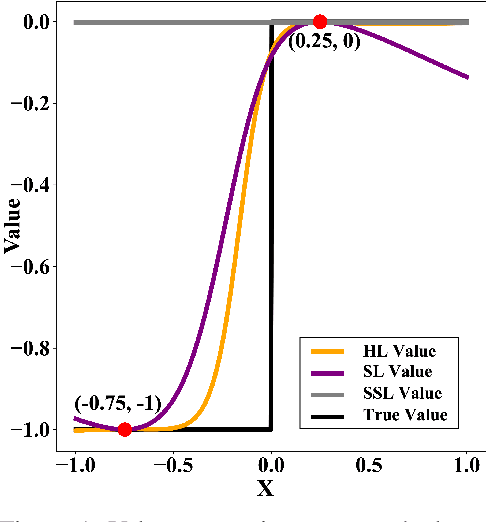
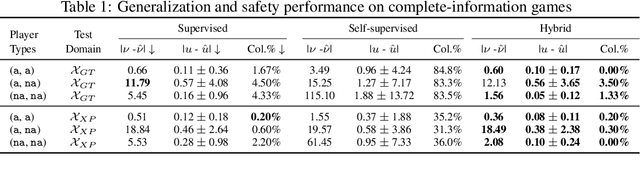
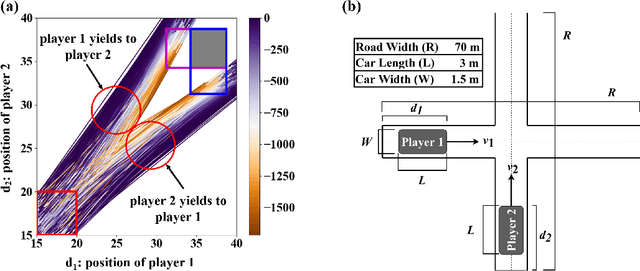

Finding Nash equilibrial policies for two-player differential games requires solving Hamilton-Jacobi-Isaacs PDEs. Recent studies achieved success in circumventing the curse of dimensionality in solving such PDEs with underlying applications to human-robot interactions (HRI), by adopting self-supervised (physics-informed) neural networks as universal value approximators. This paper extends from previous SOTA on zero-sum games with continuous values to general-sum games with discontinuous values, where the discontinuity is caused by that of the players' losses. We show that due to its lack of convergence proof and generalization analysis on discontinuous losses, the existing self-supervised learning technique fails to generalize and raises safety concerns in an autonomous driving application. Our solution is to first pre-train the value network on supervised Nash equilibria, and then refine it by minimizing a loss that combines the supervised data with the PDE and boundary conditions. Importantly, the demonstrated advantage of the proposed learning method against purely supervised and self-supervised approaches requires careful choice of the neural activation function: Among $\texttt{relu}$, $\texttt{sin}$, and $\texttt{tanh}$, we show that $\texttt{tanh}$ is the only choice that achieves optimal generalization and safety performance. Our conjecture is that $\texttt{tanh}$ (similar to $\texttt{sin}$) allows continuity of value and its gradient, which is sufficient for the convergence of learning, and at the same time is expressive enough (similar to $\texttt{relu}$) at approximating discontinuous value landscapes. Lastly, we apply our method to approximating control policies for an incomplete-information interaction and demonstrate its contribution to safe interactions.
Dict-TTS: Learning to Pronounce with Prior Dictionary Knowledge for Text-to-Speech
Jun 05, 2022

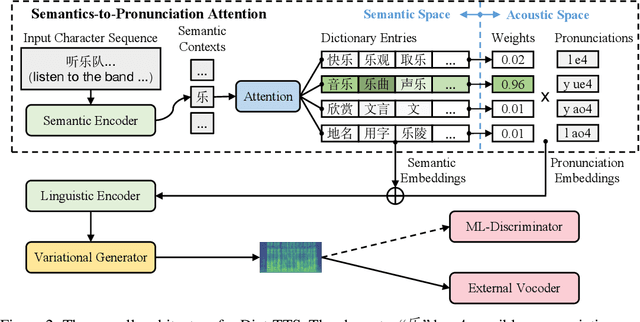
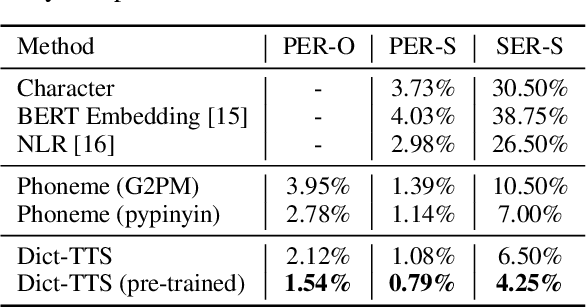
Polyphone disambiguation aims to capture accurate pronunciation knowledge from natural text sequences for reliable Text-to-speech (TTS) systems. However, previous approaches require substantial annotated training data and additional efforts from language experts, making it difficult to extend high-quality neural TTS systems to out-of-domain daily conversations and countless languages worldwide. This paper tackles the polyphone disambiguation problem from a concise and novel perspective: we propose Dict-TTS, a semantic-aware generative text-to-speech model with an online website dictionary (the existing prior information in the natural language). Specifically, we design a semantics-to-pronunciation attention (S2PA) module to match the semantic patterns between the input text sequence and the prior semantics in the dictionary and obtain the corresponding pronunciations; The S2PA module can be easily trained with the end-to-end TTS model without any annotated phoneme labels. Experimental results in three languages show that our model outperforms several strong baseline models in terms of pronunciation accuracy and improves the prosody modeling of TTS systems. Further extensive analyses with different linguistic encoders demonstrate that each design in Dict-TTS is effective. Audio samples are available at \url{https://dicttts.github.io/DictTTS-Demo/}.
Improving Item Cold-start Recommendation via Model-agnostic Conditional Variational Autoencoder
May 27, 2022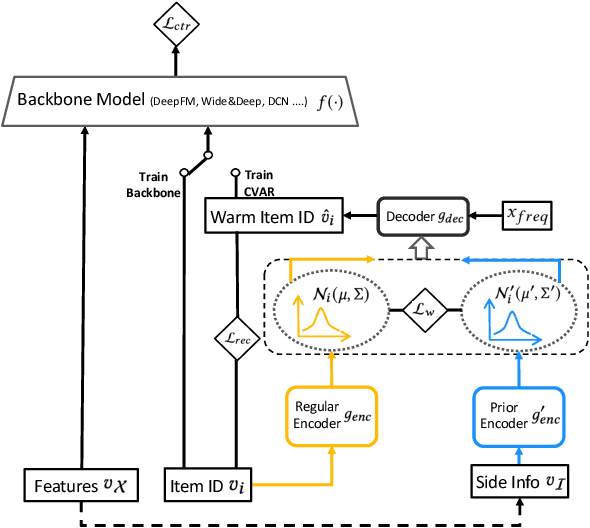
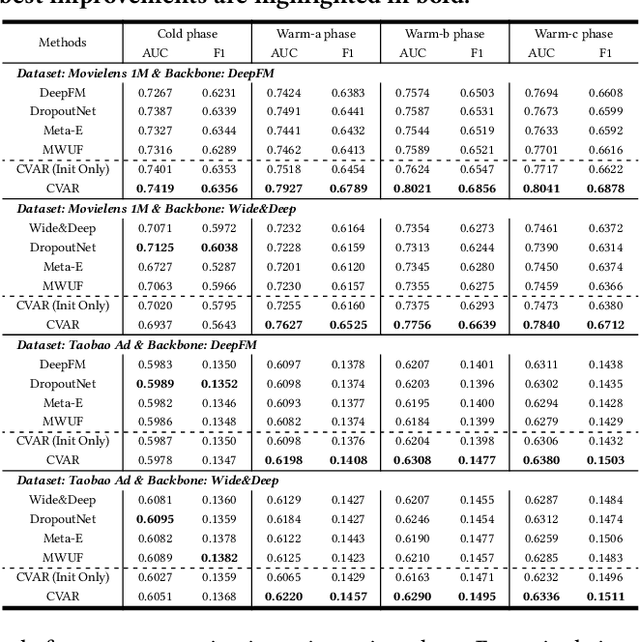
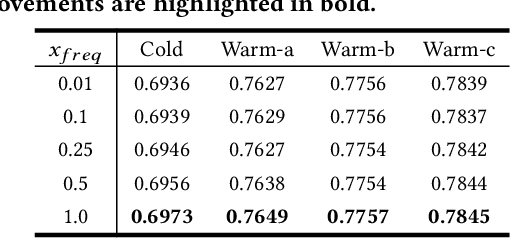
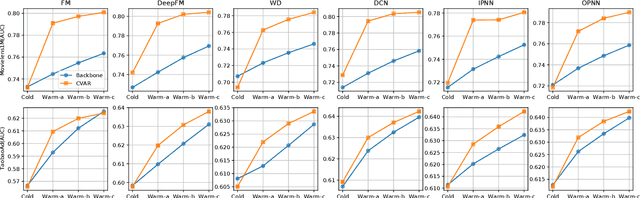
Embedding & MLP has become a paradigm for modern large-scale recommendation system. However, this paradigm suffers from the cold-start problem which will seriously compromise the ecological health of recommendation systems. This paper attempts to tackle the item cold-start problem by generating enhanced warmed-up ID embeddings for cold items with historical data and limited interaction records. From the aspect of industrial practice, we mainly focus on the following three points of item cold-start: 1) How to conduct cold-start without additional data requirements and make strategy easy to be deployed in online recommendation scenarios. 2) How to leverage both historical records and constantly emerging interaction data of new items. 3) How to model the relationship between item ID and side information stably from interaction data. To address these problems, we propose a model-agnostic Conditional Variational Autoencoder based Recommendation(CVAR) framework with some advantages including compatibility on various backbones, no extra requirements for data, utilization of both historical data and recent emerging interactions. CVAR uses latent variables to learn a distribution over item side information and generates desirable item ID embeddings using a conditional decoder. The proposed method is evaluated by extensive offline experiments on public datasets and online A/B tests on Tencent News recommendation platform, which further illustrate the advantages and robustness of CVAR.
TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation
May 25, 2022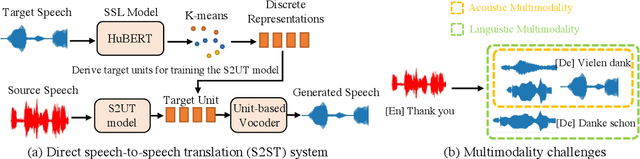
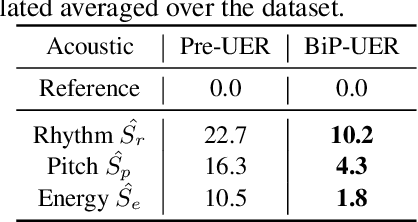
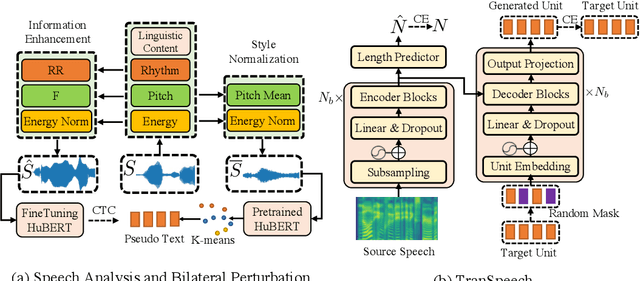
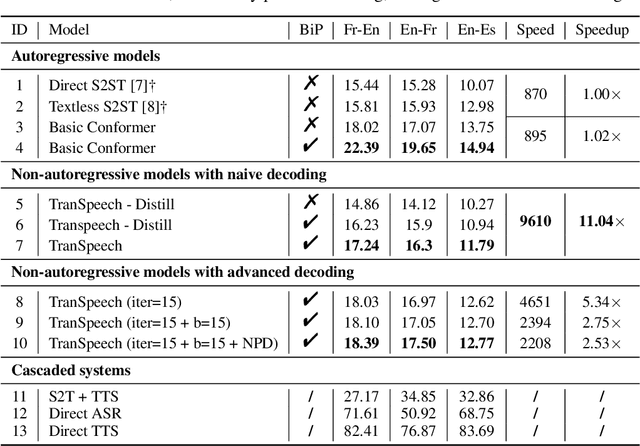
Direct speech-to-speech translation (S2ST) systems leverage recent progress in speech representation learning, where a sequence of discrete representations (units) derived in a self-supervised manner, are predicted from the model and passed to a vocoder for speech synthesis, still facing the following challenges: 1) Acoustic multimodality: the discrete units derived from speech with same content could be indeterministic due to the acoustic property (e.g., rhythm, pitch, and energy), which causes deterioration of translation accuracy; 2) high latency: current S2ST systems utilize autoregressive models which predict each unit conditioned on the sequence previously generated, failing to take full advantage of parallelism. In this work, we propose TranSpeech, a speech-to-speech translation model with bilateral perturbation. To alleviate the acoustic multimodal problem, we propose bilateral perturbation, which consists of the style normalization and information enhancement stages, to learn only the linguistic information from speech samples and generate more deterministic representations. With reduced multimodality, we step forward and become the first to establish a non-autoregressive S2ST technique, which repeatedly masks and predicts unit choices and produces high-accuracy results in just a few cycles. Experimental results on three language pairs demonstrate the state-of-the-art results by up to 2.5 BLEU points over the best publicly-available textless S2ST baseline. Moreover, TranSpeech shows a significant improvement in inference latency, enabling speedup up to 21.4x than autoregressive technique. Audio samples are available at \url{https://TranSpeech.github.io/}
GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech Synthesis
May 15, 2022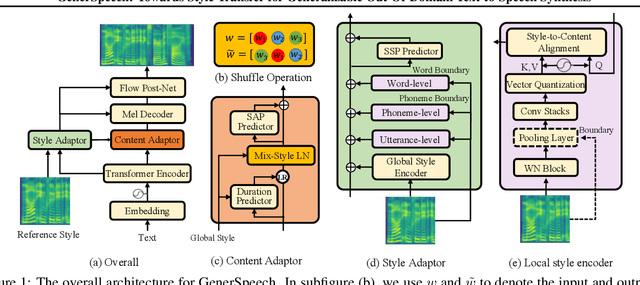
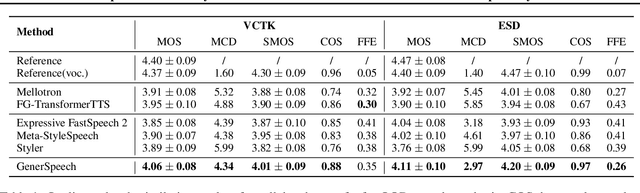
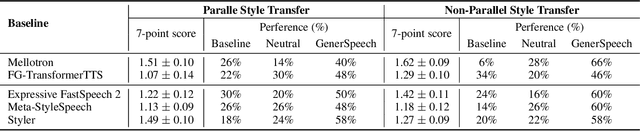
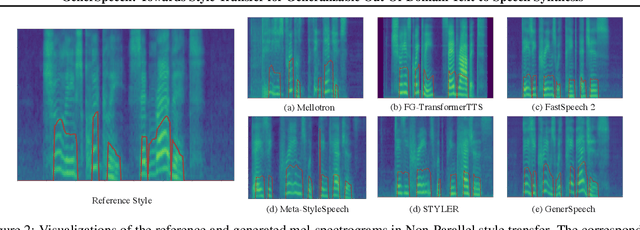
Style transfer for out-of-domain (OOD) speech synthesis aims to generate speech samples with unseen style (e.g., speaker identity, emotion, and prosody) derived from an acoustic reference, while facing the following challenges: 1) The highly dynamic style features in expressive voice are difficult to model and transfer; and 2) the TTS models should be robust enough to handle diverse OOD conditions that differ from the source data. This paper proposes GenerSpeech, a text-to-speech model towards high-fidelity zero-shot style transfer of OOD custom voice. GenerSpeech decomposes the speech variation into the style-agnostic and style-specific parts by introducing two components: 1) a multi-level style adaptor to efficiently model a large range of style conditions, including global speaker and emotion characteristics, and the local (utterance, phoneme, and word-level) fine-grained prosodic representations; and 2) a generalizable content adaptor with Mix-Style Layer Normalization to eliminate style information in the linguistic content representation and thus improve model generalization. Our evaluations on zero-shot style transfer demonstrate that GenerSpeech surpasses the state-of-the-art models in terms of audio quality and style similarity. The extension studies to adaptive style transfer further show that GenerSpeech performs robustly in the few-shot data setting. Audio samples are available at \url{https://GenerSpeech.github.io/}
SSR-GNNs: Stroke-based Sketch Representation with Graph Neural Networks
Apr 27, 2022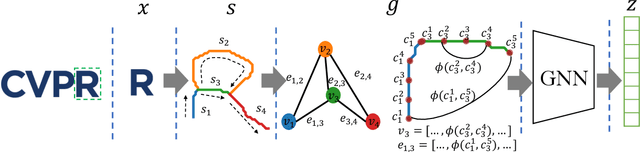
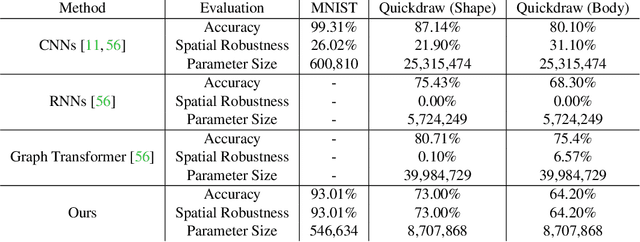
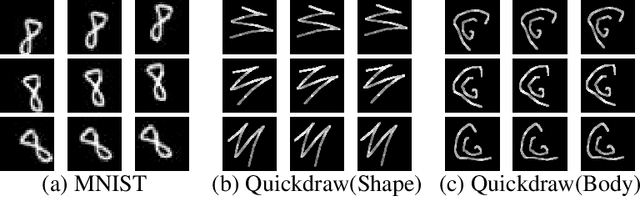
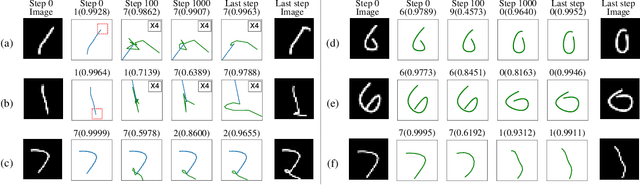
This paper follows cognitive studies to investigate a graph representation for sketches, where the information of strokes, i.e., parts of a sketch, are encoded on vertices and information of inter-stroke on edges. The resultant graph representation facilitates the training of a Graph Neural Networks for classification tasks, and achieves accuracy and robustness comparable to the state-of-the-art against translation and rotation attacks, as well as stronger attacks on graph vertices and topologies, i.e., modifications and addition of strokes, all without resorting to adversarial training. Prior studies on sketches, e.g., graph transformers, encode control points of stroke on vertices, which are not invariant to spatial transformations. In contrary, we encode vertices and edges using pairwise distances among control points to achieve invariance. Compared with existing generative sketch model for one-shot classification, our method does not rely on run-time statistical inference. Lastly, the proposed representation enables generation of novel sketches that are structurally similar to while separable from the existing dataset.
SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech
Apr 25, 2022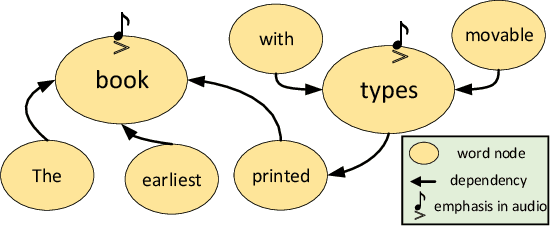
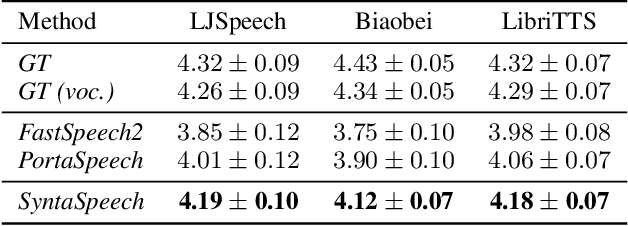
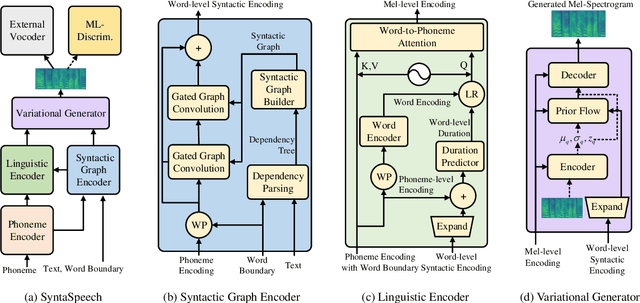
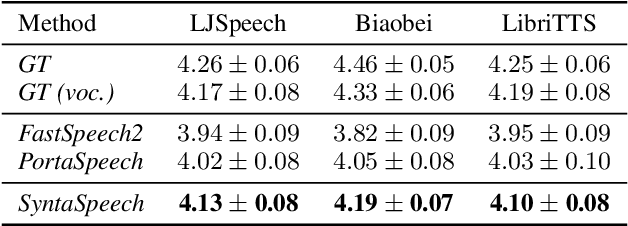
The recent progress in non-autoregressive text-to-speech (NAR-TTS) has made fast and high-quality speech synthesis possible. However, current NAR-TTS models usually use phoneme sequence as input and thus cannot understand the tree-structured syntactic information of the input sequence, which hurts the prosody modeling. To this end, we propose SyntaSpeech, a syntax-aware and light-weight NAR-TTS model, which integrates tree-structured syntactic information into the prosody modeling modules in PortaSpeech \cite{ren2021portaspeech}. Specifically, 1) We build a syntactic graph based on the dependency tree of the input sentence, then process the text encoding with a syntactic graph encoder to extract the syntactic information. 2) We incorporate the extracted syntactic encoding with PortaSpeech to improve the prosody prediction. 3) We introduce a multi-length discriminator to replace the flow-based post-net in PortaSpeech, which simplifies the training pipeline and improves the inference speed, while keeping the naturalness of the generated audio. Experiments on three datasets not only show that the tree-structured syntactic information grants SyntaSpeech the ability to synthesize better audio with expressive prosody, but also demonstrate the generalization ability of SyntaSpeech to adapt to multiple languages and multi-speaker text-to-speech. Ablation studies demonstrate the necessity of each component in SyntaSpeech. Source code and audio samples are available at https://syntaspeech.github.io
FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis
Apr 21, 2022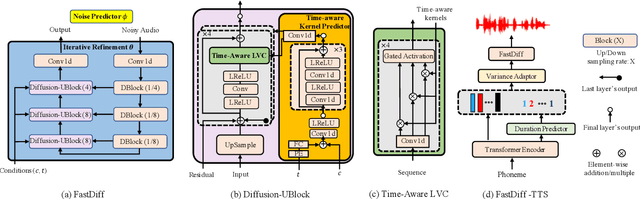
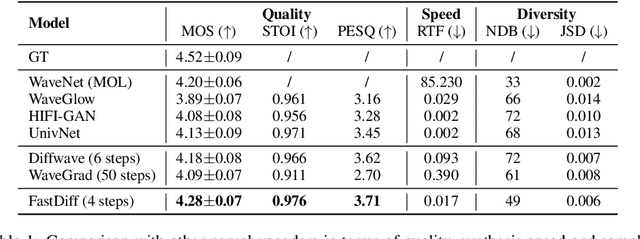
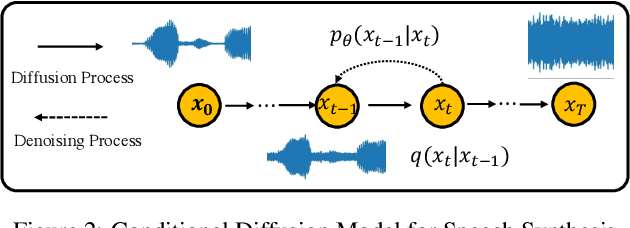

Denoising diffusion probabilistic models (DDPMs) have recently achieved leading performances in many generative tasks. However, the inherited iterative sampling process costs hindered their applications to speech synthesis. This paper proposes FastDiff, a fast conditional diffusion model for high-quality speech synthesis. FastDiff employs a stack of time-aware location-variable convolutions of diverse receptive field patterns to efficiently model long-term time dependencies with adaptive conditions. A noise schedule predictor is also adopted to reduce the sampling steps without sacrificing the generation quality. Based on FastDiff, we design an end-to-end text-to-speech synthesizer, FastDiff-TTS, which generates high-fidelity speech waveforms without any intermediate feature (e.g., Mel-spectrogram). Our evaluation of FastDiff demonstrates the state-of-the-art results with higher-quality (MOS 4.28) speech samples. Also, FastDiff enables a sampling speed of 58x faster than real-time on a V100 GPU, making diffusion models practically applicable to speech synthesis deployment for the first time. We further show that FastDiff generalized well to the mel-spectrogram inversion of unseen speakers, and FastDiff-TTS outperformed other competing methods in end-to-end text-to-speech synthesis. Audio samples are available at \url{https://FastDiff.github.io/}.
Configuration-Aware Safe Control for Mobile Robotic Arm with Control Barrier Functions
Apr 18, 2022
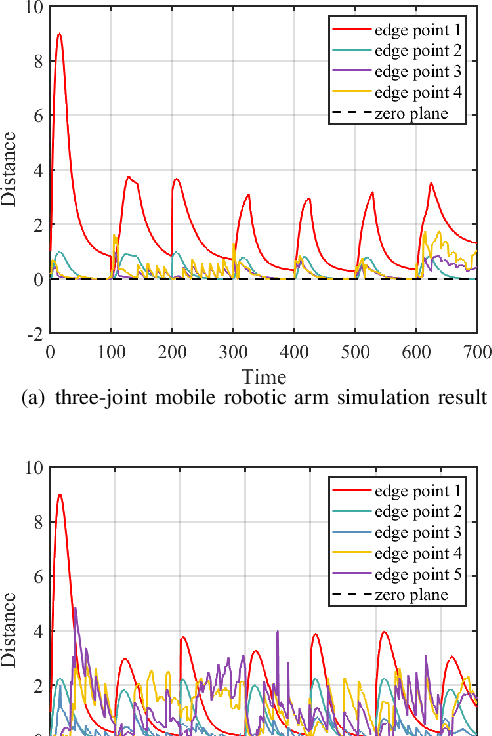
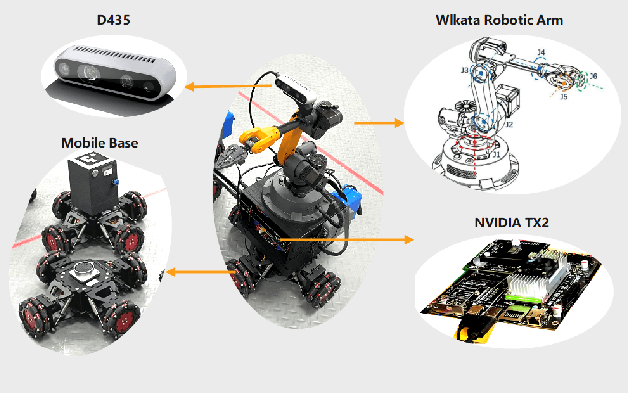
Collision avoidance is a widely investigated topic in robotic applications. When applying collision avoidance techniques to a mobile robot, how to deal with the spatial structure of the robot still remains a challenge. In this paper, we design a configuration-aware safe control law by solving a Quadratic Programming (QP) with designed Control Barrier Functions (CBFs) constraints, which can safely navigate a mobile robotic arm to a desired region while avoiding collision with environmental obstacles. The advantage of our approach is that it correctly and in an elegant way incorporates the spatial structure of the mobile robotic arm. This is achieved by merging geometric restrictions among mobile robotic arm links into CBFs constraints. Simulations on a rigid rod and the modeled mobile robotic arm are performed to verify the feasibility and time-efficiency of proposed method. Numerical results about the time consuming for different degrees of freedom illustrate that our method scales well with dimension.