 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstro: Activation-guided Structured Regularization for Outlier-Robust LLM Post-Training Quantization
Feb 07, 2026Weight-only post-training quantization (PTQ) is crucial for efficient Large Language Model (LLM) deployment but suffers from accuracy degradation caused by weight and activation outliers. Existing mitigation strategies often face critical limitations: they either yield insufficient outlier suppression or incur significant deployment inefficiencies, such as inference latency, heavy preprocessing, or reliance on complex operator fusion. To resolve these limitations, we leverage a key insight: over-parameterized LLMs often converge to Flat Minima, implying a vast equivalent solution space where weights can be adjusted without compromising accuracy. Building on this, we propose Astro, an Activation-guided Structured Regularization framework designed to suppress the negative effects of outliers in a hardware-friendly and efficient manner. Leveraging the activation-guided regularization objective, Astro actively reconstructs intrinsically robust weights, aggressively suppressing weight outliers corresponding to high-magnitude activations without sacrificing model accuracy. Crucially, Astro introduces zero inference latency and is orthogonal to mainstream quantization methods like GPTQ. Extensive experiments show that Astro achieves highly competitive performance; notably, on LLaMA-2-7B, it achieves better performance than complex learning-based rotation methods with almost 1/3 of the quantization time.
ICON: Invariant Counterfactual Optimization with Neuro-Symbolic Priors for Text-Based Person Search
Jan 22, 2026Text-Based Person Search (TBPS) holds unique value in real-world surveillance bridging visual perception and language understanding, yet current paradigms utilizing pre-training models often fail to transfer effectively to complex open-world scenarios. The reliance on "Passive Observation" leads to multifaceted spurious correlations and spatial semantic misalignment, causing a lack of robustness against distribution shifts. To fundamentally resolve these defects, this paper proposes ICON (Invariant Counterfactual Optimization with Neuro-symbolic priors), a framework integrating causal and topological priors. First, we introduce Rule-Guided Spatial Intervention to strictly penalize sensitivity to bounding box noise, forcibly severing location shortcuts to achieve geometric invariance. Second, Counterfactual Context Disentanglement is implemented via semantic-driven background transplantation, compelling the model to ignore background interference for environmental independence. Then, we employ Saliency-Driven Semantic Regularization with adaptive masking to resolve local saliency bias and guarantee holistic completeness. Finally, Neuro-Symbolic Topological Alignment utilizes neuro-symbolic priors to constrain feature matching, ensuring activated regions are topologically consistent with human structural logic. Experimental results demonstrate that ICON not only maintains leading performance on standard benchmarks but also exhibits exceptional robustness against occlusion, background interference, and localization noise. This approach effectively advances the field by shifting from fitting statistical co-occurrences to learning causal invariance.
Diffusion Large Language Models for Black-Box Optimization
Jan 20, 2026Offline black-box optimization (BBO) aims to find optimal designs based solely on an offline dataset of designs and their labels. Such scenarios frequently arise in domains like DNA sequence design and robotics, where only a few labeled data points are available. Traditional methods typically rely on task-specific proxy or generative models, overlooking the in-context learning capabilities of pre-trained large language models (LLMs). Recent efforts have adapted autoregressive LLMs to BBO by framing task descriptions and offline datasets as natural language prompts, enabling direct design generation. However, these designs often contain bidirectional dependencies, which left-to-right models struggle to capture. In this paper, we explore diffusion LLMs for BBO, leveraging their bidirectional modeling and iterative refinement capabilities. This motivates our in-context denoising module: we condition the diffusion LLM on the task description and the offline dataset, both formatted in natural language, and prompt it to denoise masked designs into improved candidates. To guide the generation toward high-performing designs, we introduce masked diffusion tree search, which casts the denoising process as a step-wise Monte Carlo Tree Search that dynamically balances exploration and exploitation. Each node represents a partially masked design, each denoising step is an action, and candidates are evaluated via expected improvement under a Gaussian Process trained on the offline dataset. Our method, dLLM, achieves state-of-the-art results in few-shot settings on design-bench.
Optimizing User Profiles via Contextual Bandits for Retrieval-Augmented LLM Personalization
Jan 17, 2026Large Language Models (LLMs) excel at general-purpose tasks, yet adapting their responses to individual users remains challenging. Retrieval augmentation provides a lightweight alternative to fine-tuning by conditioning LLMs on user history records, and existing approaches typically select these records based on semantic relevance. We argue that relevance serves as an unreliable proxy for utility: a record may be semantically similar to a query yet fail to improve generation quality or even degrade it due to redundancy or conflicting information. To bridge this gap, we propose PURPLE, a contextual bandit framework that oPtimizes UseR Profiles for Llm pErsonalization. In contrast to a greedy selection of the most relevant records, PURPLE treats profile construction as a set generation process and utilizes a Plackett-Luce ranking model to capture complex inter-record dependencies. By training with dense feedback provided by the likelihood of the reference response, our method aligns retrieval directly with generation quality. Extensive experiments on nine personalization tasks demonstrate that PURPLE consistently outperforms strong heuristic and retrieval-augmented baselines in both effectiveness and efficiency, establishing a principled and scalable solution for optimizing user profiles.
A Novel Graph-Sequence Learning Model for Inductive Text Classification
Dec 23, 2025Text classification plays an important role in various downstream text-related tasks, such as sentiment analysis, fake news detection, and public opinion analysis. Recently, text classification based on Graph Neural Networks (GNNs) has made significant progress due to their strong capabilities of structural relationship learning. However, these approaches still face two major limitations. First, these approaches fail to fully consider the diverse structural information across word pairs, e.g., co-occurrence, syntax, and semantics. Furthermore, they neglect sequence information in the text graph structure information learning module and can not classify texts with new words and relations. In this paper, we propose a Novel Graph-Sequence Learning Model for Inductive Text Classification (TextGSL) to address the previously mentioned issues. More specifically, we construct a single text-level graph for all words in each text and establish different edge types based on the diverse relationships between word pairs. Building upon this, we design an adaptive multi-edge message-passing paradigm to aggregate diverse structural information between word pairs. Additionally, sequential information among text data can be captured by the proposed TextGSL through the incorporation of Transformer layers. Therefore, TextGSL can learn more discriminative text representations. TextGSL has been comprehensively compared with several strong baselines. The experimental results on diverse benchmarking datasets demonstrate that TextGSL outperforms these baselines in terms of accuracy.
Jensen-Shannon Divergence Message-Passing for Rich-Text Graph Representation Learning
Dec 23, 2025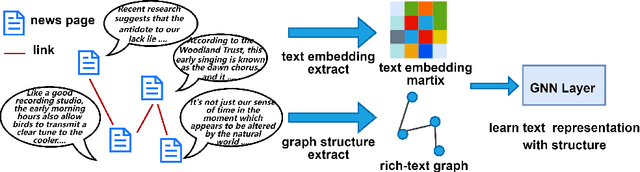
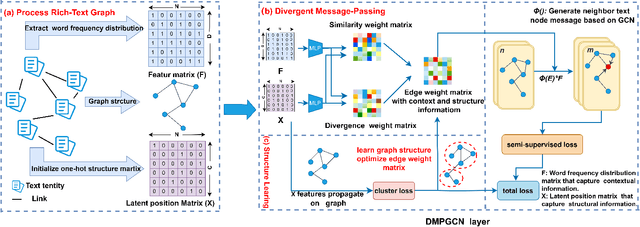
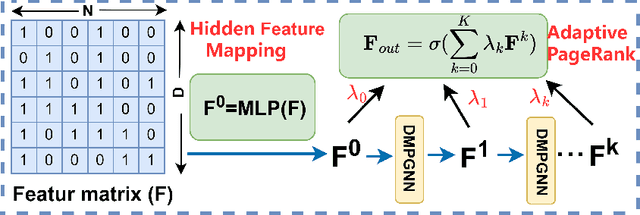
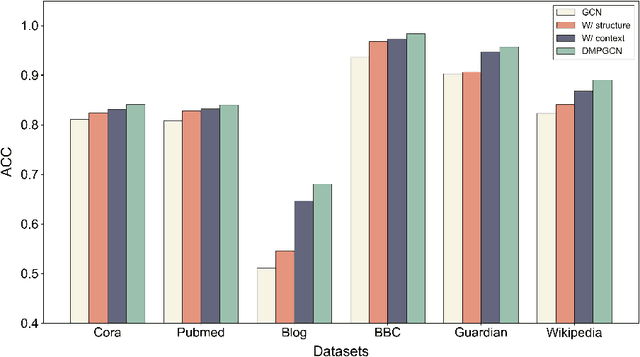
In this paper, we investigate how the widely existing contextual and structural divergence may influence the representation learning in rich-text graphs. To this end, we propose Jensen-Shannon Divergence Message-Passing (JSDMP), a new learning paradigm for rich-text graph representation learning. Besides considering similarity regarding structure and text, JSDMP further captures their corresponding dissimilarity by Jensen-Shannon divergence. Similarity and dissimilarity are then jointly used to compute new message weights among text nodes, thus enabling representations to learn with contextual and structural information from truly correlated text nodes. With JSDMP, we propose two novel graph neural networks, namely Divergent message-passing graph convolutional network (DMPGCN) and Divergent message-passing Page-Rank graph neural networks (DMPPRG), for learning representations in rich-text graphs. DMPGCN and DMPPRG have been extensively texted on well-established rich-text datasets and compared with several state-of-the-art baselines. The experimental results show that DMPGCN and DMPPRG can outperform other baselines, demonstrating the effectiveness of the proposed Jensen-Shannon Divergence Message-Passing paradigm
Modular Layout Synthesis (MLS): Front-end Code via Structure Normalization and Constrained Generation
Dec 22, 2025Automated front-end engineering drastically reduces development cycles and minimizes manual coding overhead. While Generative AI has shown promise in translating designs to code, current solutions often produce monolithic scripts, failing to natively support modern ecosystems like React, Vue, or Angular. Furthermore, the generated code frequently suffers from poor modularity, making it difficult to maintain. To bridge this gap, we introduce Modular Layout Synthesis (MLS), a hierarchical framework that merges visual understanding with structural normalization. Initially, a visual-semantic encoder maps the screen capture into a serialized tree topology, capturing the essential layout hierarchy. Instead of simple parsing, we apply heuristic deduplication and pattern recognition to isolate reusable blocks, creating a framework-agnostic schema. Finally, a constraint-based generation protocol guides the LLM to synthesize production-ready code with strict typing and component props. Evaluations show that MLS significantly outperforms existing baselines, ensuring superior code reusability and structural integrity across multiple frameworks
A Multi-scale Fused Graph Neural Network with Inter-view Contrastive Learning for Spatial Transcriptomics Data Clustering
Dec 18, 2025



Spatial transcriptomics enables genome-wide expression analysis within native tissue context, yet identifying spatial domains remains challenging due to complex gene-spatial interactions. Existing methods typically process spatial and feature views separately, fusing only at output level - an "encode-separately, fuse-late" paradigm that limits multi-scale semantic capture and cross-view interaction. Accordingly, stMFG is proposed, a multi-scale interactive fusion graph network that introduces layer-wise cross-view attention to dynamically integrate spatial and gene features after each convolution. The model combines cross-view contrastive learning with spatial constraints to enhance discriminability while maintaining spatial continuity. On DLPFC and breast cancer datasets, stMFG outperforms state-of-the-art methods, achieving up to 14% ARI improvement on certain slices.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Dec 16, 2025



Recent progress in humanoid robots has unlocked agile locomotion skills, including backflipping, running, and crawling. Yet it remains challenging for a humanoid robot to perform forceful manipulation tasks such as moving objects, wiping, and pushing a cart. We propose adaptive Compliance Humanoid control through hIsight Perturbation (CHIP), a plug-and-play module that enables controllable end-effector stiffness while preserving agile tracking of dynamic reference motions. CHIP is easy to implement and requires neither data augmentation nor additional reward tuning. We show that a generalist motion-tracking controller trained with CHIP can perform a diverse set of forceful manipulation tasks that require different end-effector compliance, such as multi-robot collaboration, wiping, box delivery, and door opening.
CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
Dec 12, 2025Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.