 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Remote Sensing Change Detection with Neural Memory
Feb 11, 2026Remote sensing change detection is essential for environmental monitoring, urban planning, and related applications. However, current methods often struggle to capture long-range dependencies while maintaining computational efficiency. Although Transformers can effectively model global context, their quadratic complexity poses scalability challenges, and existing linear attention approaches frequently fail to capture intricate spatiotemporal relationships. Drawing inspiration from the recent success of Titans in language tasks, we present ChangeTitans, the Titans-based framework for remote sensing change detection. Specifically, we propose VTitans, the first Titans-based vision backbone that integrates neural memory with segmented local attention, thereby capturing long-range dependencies while mitigating computational overhead. Next, we present a hierarchical VTitans-Adapter to refine multi-scale features across different network layers. Finally, we introduce TS-CBAM, a two-stream fusion module leveraging cross-temporal attention to suppress pseudo-changes and enhance detection accuracy. Experimental evaluations on four benchmark datasets (LEVIR-CD, WHU-CD, LEVIR-CD+, and SYSU-CD) demonstrate that ChangeTitans achieves state-of-the-art results, attaining \textbf{84.36\%} IoU and \textbf{91.52\%} F1-score on LEVIR-CD, while remaining computationally competitive.
Astro: Activation-guided Structured Regularization for Outlier-Robust LLM Post-Training Quantization
Feb 07, 2026Weight-only post-training quantization (PTQ) is crucial for efficient Large Language Model (LLM) deployment but suffers from accuracy degradation caused by weight and activation outliers. Existing mitigation strategies often face critical limitations: they either yield insufficient outlier suppression or incur significant deployment inefficiencies, such as inference latency, heavy preprocessing, or reliance on complex operator fusion. To resolve these limitations, we leverage a key insight: over-parameterized LLMs often converge to Flat Minima, implying a vast equivalent solution space where weights can be adjusted without compromising accuracy. Building on this, we propose Astro, an Activation-guided Structured Regularization framework designed to suppress the negative effects of outliers in a hardware-friendly and efficient manner. Leveraging the activation-guided regularization objective, Astro actively reconstructs intrinsically robust weights, aggressively suppressing weight outliers corresponding to high-magnitude activations without sacrificing model accuracy. Crucially, Astro introduces zero inference latency and is orthogonal to mainstream quantization methods like GPTQ. Extensive experiments show that Astro achieves highly competitive performance; notably, on LLaMA-2-7B, it achieves better performance than complex learning-based rotation methods with almost 1/3 of the quantization time.
Learn More with Less: Uncertainty Consistency Guided Query Selection for RLVR
Jan 30, 2026Large Language Models (LLMs) have recently improved mathematical reasoning through Reinforcement Learning with Verifiable Reward (RLVR). However, existing RLVR algorithms require large query budgets, making annotation costly. We investigate whether fewer but more informative queries can yield similar or superior performance, introducing active learning (AL) into RLVR. We identify that classic AL sampling strategies fail to outperform random selection in this setting, due to ignoring objective uncertainty when only selecting by subjective uncertainty. This work proposes an uncertainty consistency metric to evaluate how well subjective uncertainty aligns with objective uncertainty. In the offline setting, this alignment is measured using the Point-Biserial Correlation Coefficient (PBC). For online training, because of limited sampling and dynamically shifting output distributions, PBC estimation is difficult. Therefore, we introduce a new online variant, computed from normalized advantage and subjective uncertainty. Theoretically, we prove that the online variant is strictly negatively correlated with offline PBC and supports better sample selection. Experiments show our method consistently outperforms random and classic AL baselines, achieving full-dataset performance while training on only 30% of the data, effectively reducing the cost of RLVR for reasoning tasks.
SchoenbAt: Rethinking Attention with Polynomial basis
May 18, 2025Kernelized attention extends the attention mechanism by modeling sequence correlations through kernel functions, making significant progresses in optimizing attention. Under the guarantee of harmonic analysis theory, kernel functions can be expanded with basis functions, inspiring random feature-based approaches to enhance the efficiency of kernelized attention while maintaining predictive performance. However, current random feature-based works are limited to the Fourier basis expansions under Bochner's theorem. We propose Schoenberg's theorem-based attention (SchoenbAt), which approximates dot-product kernelized attention with the polynomial basis under Schoenberg's theorem via random Maclaurin features and applies a two-stage regularization to constrain the input space and restore the output scale, acting as a drop-in replacement of dot-product kernelized attention. Our theoretical proof of the unbiasedness and concentration error bound of SchoenbAt supports its efficiency and accuracy as a kernelized attention approximation, which is also empirically validated under various random feature dimensions. Evaluations on real-world datasets demonstrate that SchoenbAt significantly enhances computational speed while preserving competitive performance in terms of precision, outperforming several efficient attention methods.
Unveiling and Causalizing CoT: A Causal Pespective
Feb 25, 2025Although Chain-of-Thought (CoT) has achieved remarkable success in enhancing the reasoning ability of large language models (LLMs), the mechanism of CoT remains a ``black box''. Even if the correct answers can frequently be obtained, existing CoTs struggle to make the reasoning understandable to human. In this paper, we unveil and causalize CoT from a causal perspective to ensure both correctness and understandability of all reasoning steps (to the best of our knowledge, the first such). We model causality of CoT via structural causal models (SCM) to unveil the reasoning mechanism of CoT. To measure the causality of CoT, we define the CoT Average Causal Effect (CACE) to test the causal relations between steps. For those steps without causality (wrong or unintelligible steps), we design a role-playing causal query algorithm to causalize these steps, resulting a causalized CoT with all steps correct and understandable. Experimental results on both open-source and closed-source LLMs demonstrate that the causal errors commonly in steps are effectively corrected and the reasoning ability of LLMs is significantly improved.
Macformer: Transformer with Random Maclaurin Feature Attention
Aug 21, 2024



Random feature attention (RFA) adopts random fourier feature (RFF) methods to approximate the softmax function, resulting in a linear time and space attention mechanism that enables the construction of an efficient Transformer. Inspired by RFA, we propose Macformer, a Transformer architecture that employs random Maclaurin features (RMF) to approximate various dot-product kernels, thereby accelerating attention computations for long sequence. Macformer consists of Random Maclaurin Feature Attention (RMFA) and pre-post Scaling Batch Normalization (ppSBN), the former is an unbiased approximation for dot-product kernelized attention and the later is a two-stage regularization mechanism guaranteeing the error of RMFA. We conducted toy experiments to demonstrate the efficiency of RMFA and ppSBN, and experiments on long range arena (LRA) benchmark to validate the acceleration and accuracy of Macformer with different dot-product kernels. Experiment results of Macformer are consistent with our theoretical analysis.
Self-supervised Smoothing Graph Neural Networks
Sep 02, 2020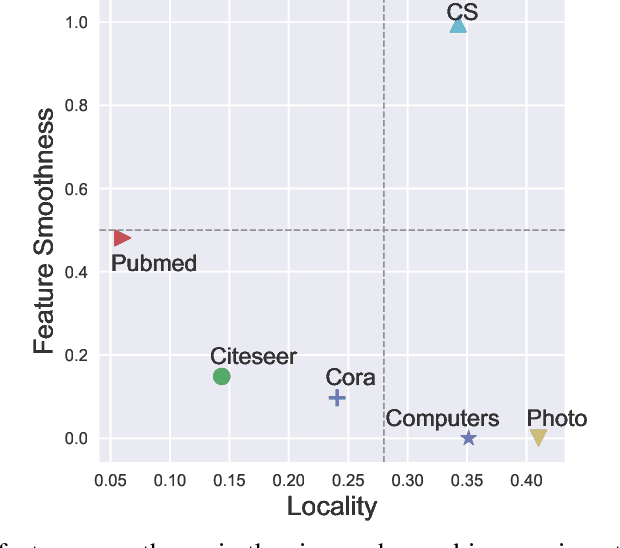
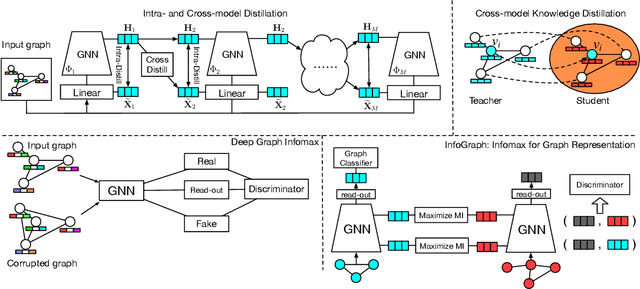
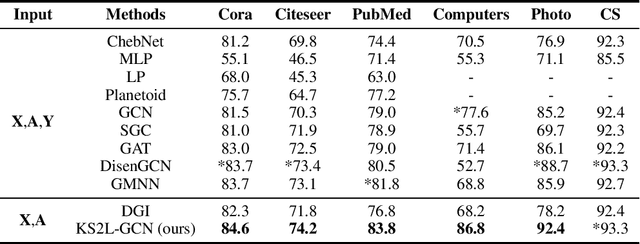
This paper studies learning node representations with GNNs for unsupervised scenarios. We make a theoretical understanding and empirical demonstration about the non-steady performance of GNNs over different graph datasets, when the supervision signals are not appropriately defined. The performance of GNNs depends on both the node feature smoothness and the graph locality. To smooth the discrepancy of node proximity measured by graph topology and node feature, we proposed KS2L - a novel graph \underline{K}nowledge distillation regularized \underline{S}elf-\underline{S}upervised \underline{L}earning framework, with two complementary regularization modules, for intra-and cross-model graph knowledge distillation. We demonstrate the competitive performance of KS2L on a variety of benchmarks. Even with a single GCN layer, KS2L has consistently competitive or even better performance on various benchmark datasets.
Theoretical Analysis of Divide-and-Conquer ERM: Beyond Square Loss and RKHS
Mar 17, 2020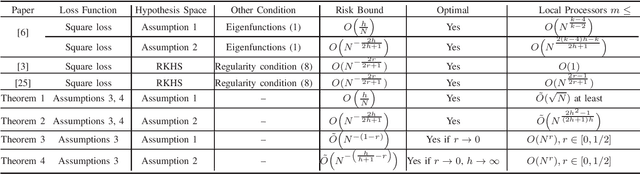
Theoretical analysis of the divide-and-conquer based distributed learning with least square loss in the reproducing kernel Hilbert space (RKHS) have recently been explored within the framework of learning theory. However, the studies on learning theory for general loss functions and hypothesis spaces remain limited. To fill the gap, we study the risk performance of distributed empirical risk minimization (ERM) for general loss functions and hypothesis spaces. The main contributions are two-fold. First, we derive two tight risk bounds under certain basic assumptions on the hypothesis space, as well as the smoothness, Lipschitz continuity, strong convexity of the loss function. Second, we further develop a more general risk bound for distributed ERM without the restriction of strong convexity.
Nearly Optimal Risk Bounds for Kernel K-Means
Mar 09, 2020In this paper, we study the statistical properties of the kernel $k$-means and obtain a nearly optimal excess risk bound, substantially improving the state-of-art bounds in the existing clustering risk analyses. We further analyze the statistical effect of computational approximations of the Nystr\"{o}m kernel $k$-means, and demonstrate that it achieves the same statistical accuracy as the exact kernel $k$-means considering only $\sqrt{nk}$ Nystr\"{o}m landmark points. To the best of our knowledge, such sharp excess risk bounds for kernel (or approximate kernel) $k$-means have never been seen before.
Differentially Private ERM Based on Data Perturbation
Feb 20, 2020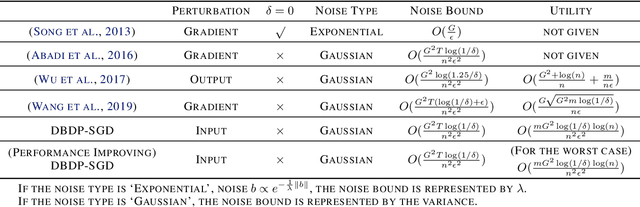
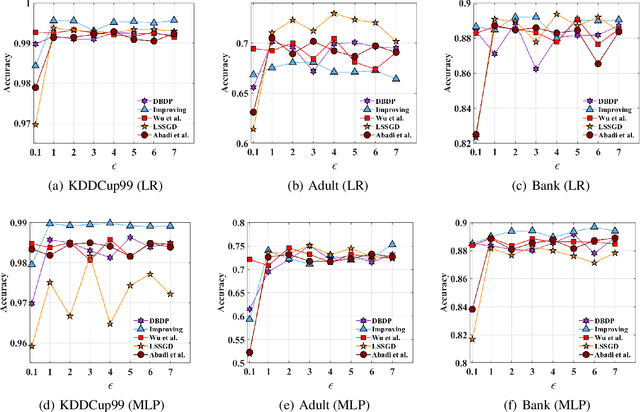
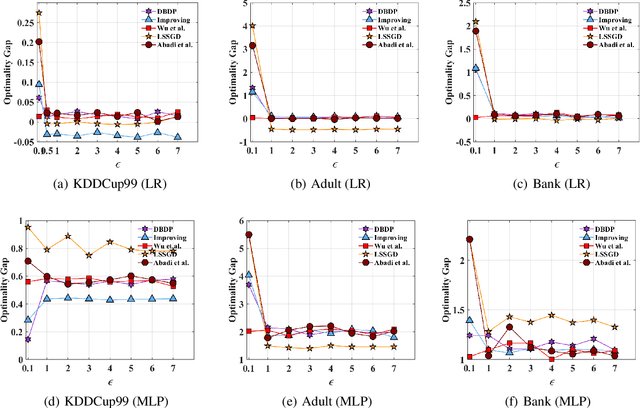
In this paper, after observing that different training data instances affect the machine learning model to different extents, we attempt to improve the performance of differentially private empirical risk minimization (DP-ERM) from a new perspective. Specifically, we measure the contributions of various training data instances on the final machine learning model, and select some of them to add random noise. Considering that the key of our method is to measure each data instance separately, we propose a new `Data perturbation' based (DB) paradigm for DP-ERM: adding random noise to the original training data and achieving ($\epsilon,\delta$)-differential privacy on the final machine learning model, along with the preservation on the original data. By introducing the Influence Function (IF), we quantitatively measure the impact of the training data on the final model. Theoretical and experimental results show that our proposed DBDP-ERM paradigm enhances the model performance significantly.