 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
AGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
Mar 20, 2026Recent advances in reinforcement learning (RL) have enabled impressive humanoid behaviors in simulation, yet transferring these results to new robots remains challenging. In many real deployments, the primary bottleneck is no longer simulation throughput or algorithm design, but the absence of systematic infrastructure that links environment verification, training, evaluation, and deployment in a coherent loop. To address this gap, we present AGILE, an end-to-end workflow for humanoid RL that standardizes the policy-development lifecycle to mitigate common sim-to-real failure modes. AGILE comprises four stages: (1) interactive environment verification, (2) reproducible training, (3) unified evaluation, and (4) descriptor-driven deployment via robot/task configuration descriptors. For evaluation stage, AGILE supports both scenario-based tests and randomized rollouts under a shared suite of motion-quality diagnostics, enabling automated regression testing and principled robustness assessment. AGILE also incorporates a set of training stabilizations and algorithmic enhancements in training stage to improve optimization stability and sim-to-real transfer. With this pipeline in place, we validate AGILE across five representative humanoid skills spanning locomotion, recovery, motion imitation, and loco-manipulation on two hardware platforms (Unitree G1 and Booster T1), achieving consistent sim-to-real transfer. Overall, AGILE shows that a standardized, end-to-end workflow can substantially improve the reliability and reproducibility of humanoid RL development.
CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
Dec 12, 2025Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
COMPASS: Cross-embodiment Mobility Policy via Residual RL and Skill Synthesis
Feb 22, 2025



As robots are increasingly deployed in diverse application domains, generalizable cross-embodiment mobility policies are increasingly essential. While classical mobility stacks have proven effective on specific robot platforms, they pose significant challenges when scaling to new embodiments. Learning-based methods, such as imitation learning (IL) and reinforcement learning (RL), offer alternative solutions but suffer from covariate shift, sparse sampling in large environments, and embodiment-specific constraints. This paper introduces COMPASS, a novel workflow for developing cross-embodiment mobility policies by integrating IL, residual RL, and policy distillation. We begin with IL on a mobile robot, leveraging easily accessible teacher policies to train a foundational model that combines a world model with a mobility policy. Building on this base, we employ residual RL to fine-tune embodiment-specific policies, exploiting pre-trained representations to improve sampling efficiency in handling various physical constraints and sensor modalities. Finally, policy distillation merges these embodiment-specialist policies into a single robust cross-embodiment policy. We empirically demonstrate that COMPASS scales effectively across diverse robot platforms while maintaining adaptability to various environment configurations, achieving a generalist policy with a success rate approximately 5X higher than the pre-trained IL policy. The resulting framework offers an efficient, scalable solution for cross-embodiment mobility, enabling robots with different designs to navigate safely and efficiently in complex scenarios.
A Pioneering Neural Network Method for Efficient and Robust Fuel Sloshing Simulation in Aircraft
Dec 14, 2024



Simulating fuel sloshing within aircraft tanks during flight is crucial for aircraft safety research. Traditional methods based on Navier-Stokes equations are computationally expensive. In this paper, we treat fluid motion as point cloud transformation and propose the first neural network method specifically designed for simulating fuel sloshing in aircraft. This model is also the deep learning model that is the first to be capable of stably modeling fluid particle dynamics in such complex scenarios. Our triangle feature fusion design achieves an optimal balance among fluid dynamics modeling, momentum conservation constraints, and global stability control. Additionally, we constructed the Fueltank dataset, the first dataset for aircraft fuel surface sloshing. It comprises 320,000 frames across four typical tank types and covers a wide range of flight maneuvers, including multi-directional rotations. We conducted comprehensive experiments on both our dataset and the take-off scenario of the aircraft. Compared to existing neural network-based fluid simulation algorithms, we significantly enhanced accuracy while maintaining high computational speed. Compared to traditional SPH methods, our speed improved approximately 10 times. Furthermore, compared to traditional fluid simulation software such as Flow3D, our computation speed increased by more than 300 times.
X-MOBILITY: End-To-End Generalizable Navigation via World Modeling
Oct 23, 2024



General-purpose navigation in challenging environments remains a significant problem in robotics, with current state-of-the-art approaches facing myriad limitations. Classical approaches struggle with cluttered settings and require extensive tuning, while learning-based methods face difficulties generalizing to out-of-distribution environments. This paper introduces X-Mobility, an end-to-end generalizable navigation model that overcomes existing challenges by leveraging three key ideas. First, X-Mobility employs an auto-regressive world modeling architecture with a latent state space to capture world dynamics. Second, a diverse set of multi-head decoders enables the model to learn a rich state representation that correlates strongly with effective navigation skills. Third, by decoupling world modeling from action policy, our architecture can train effectively on a variety of data sources, both with and without expert policies: off-policy data allows the model to learn world dynamics, while on-policy data with supervisory control enables optimal action policy learning. Through extensive experiments, we demonstrate that X-Mobility not only generalizes effectively but also surpasses current state-of-the-art navigation approaches. Additionally, X-Mobility also achieves zero-shot Sim2Real transferability and shows strong potential for cross-embodiment generalization.
DualFluidNet: an Attention-based Dual-pipeline Network for Accurate and Generalizable Fluid-solid Coupled Simulation
Dec 28, 2023



Fluid motion can be considered as point cloud transformation when adopted by a Lagrangian description. Compared to traditional numerical analysis methods, using machine learning techniques to learn physics simulations can achieve near accuracy, while significantly increasing efficiency. In this paper, we propose an innovative approach for 3D fluid simulations utilizing an Attention-based Dual-pipeline Network, which employs a dual-pipeline architecture, seamlessly integrated with an Attention-based Feature Fusion Module. Unlike previous single-pipeline approaches, we find that a well-designed dual-pipeline approach achieves a better balance between global fluid control and physical law constraints. Furthermore, we design a Type-aware Input Module to adaptively recognize particles of different types and perform feature fusion afterward, such that fluid-solid coupling issues can be better dealt with. The experiments show that our approach significantly increases the accuracy of fluid simulation predictions and enhances generalizability to previously unseen scenarios. We demonstrate its superior performance over the state-of-the-art approaches across various metrics.
SafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
Sep 28, 2021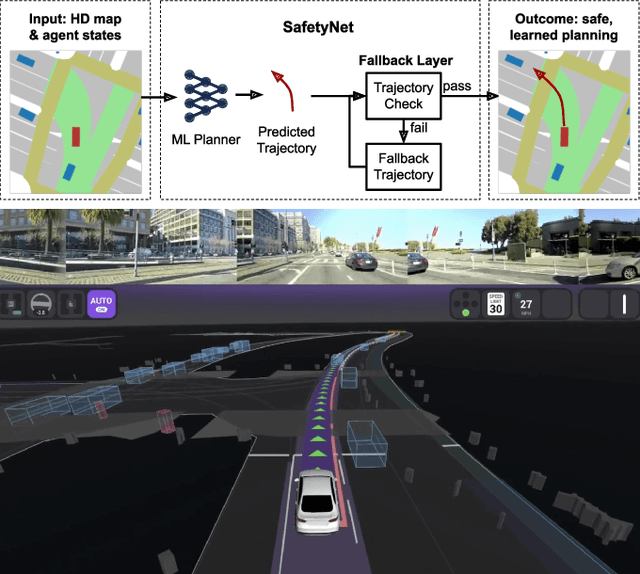
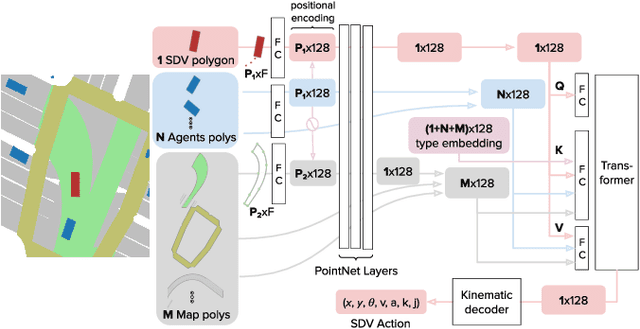
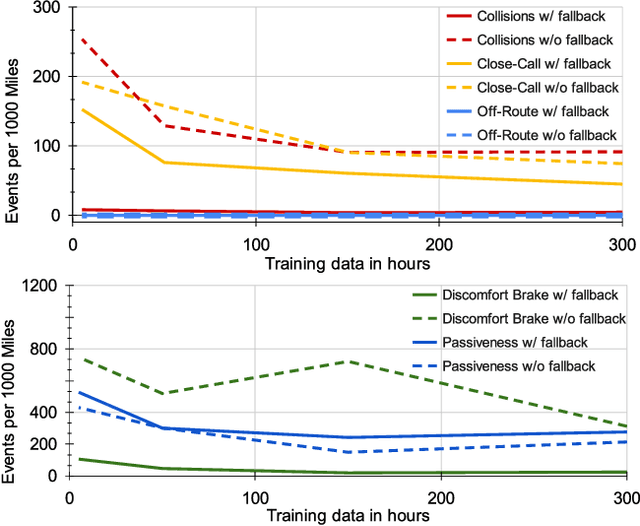
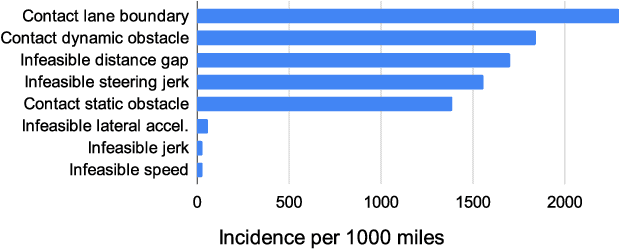
In this paper we present the first safe system for full control of self-driving vehicles trained from human demonstrations and deployed in challenging, real-world, urban environments. Current industry-standard solutions use rule-based systems for planning. Although they perform reasonably well in common scenarios, the engineering complexity renders this approach incompatible with human-level performance. On the other hand, the performance of machine-learned (ML) planning solutions can be improved by simply adding more exemplar data. However, ML methods cannot offer safety guarantees and sometimes behave unpredictably. To combat this, our approach uses a simple yet effective rule-based fallback layer that performs sanity checks on an ML planner's decisions (e.g. avoiding collision, assuring physical feasibility). This allows us to leverage ML to handle complex situations while still assuring the safety, reducing ML planner-only collisions by 95%. We train our ML planner on 300 hours of expert driving demonstrations using imitation learning and deploy it along with the fallback layer in downtown San Francisco, where it takes complete control of a real vehicle and navigates a wide variety of challenging urban driving scenarios.