 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021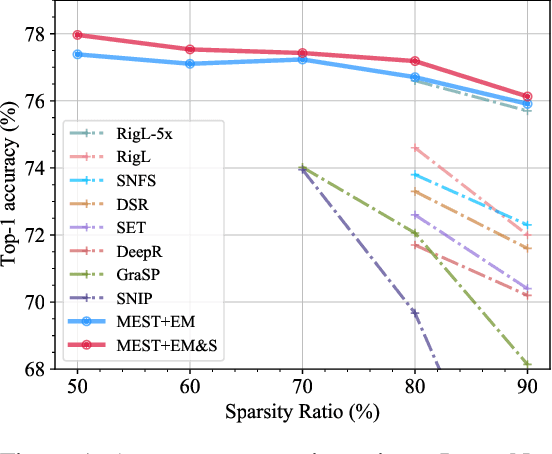
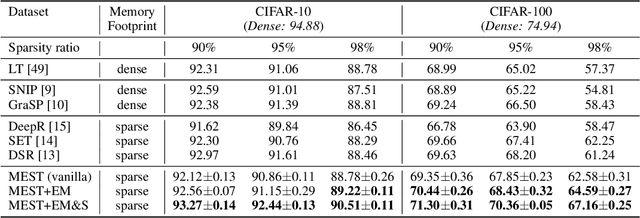
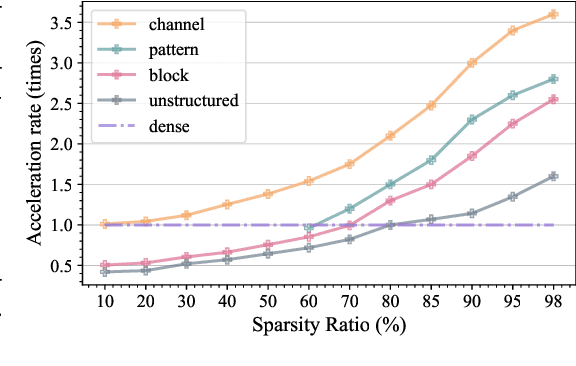
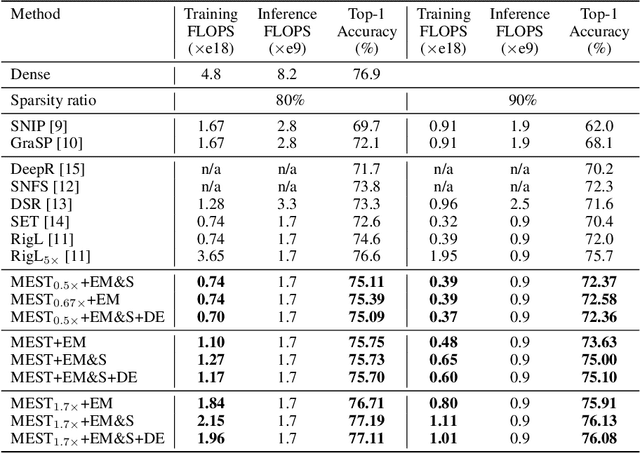
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
Enabling Level-4 Autonomous Driving on a Single $1k Off-the-Shelf Card
Oct 12, 2021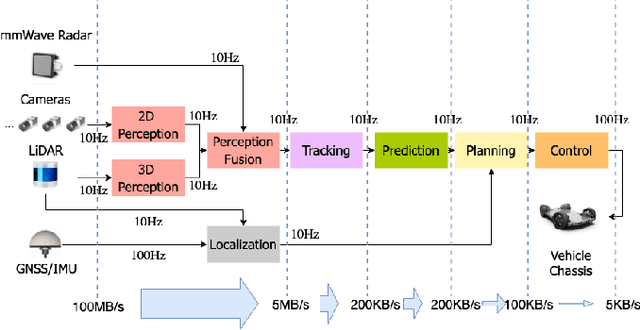
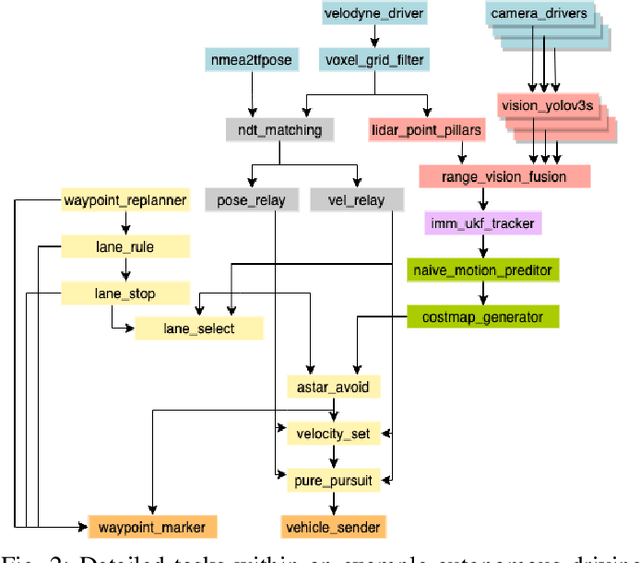
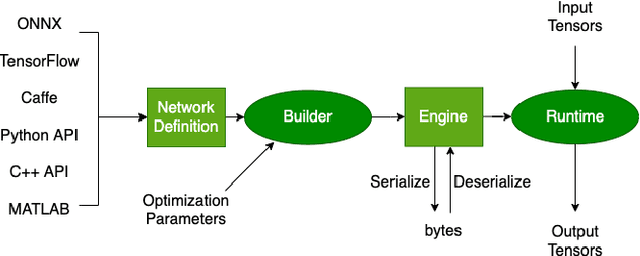
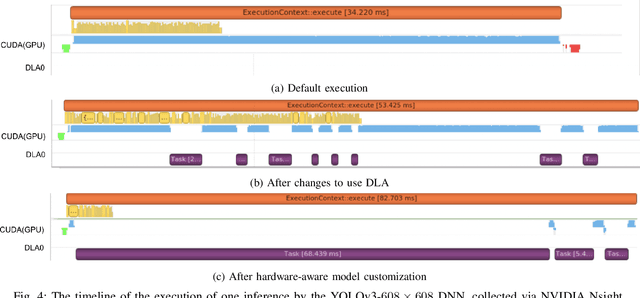
Autonomous driving is of great interest in both research and industry. The high cost has been one of the major roadblocks that slow down the development and adoption of autonomous driving in practice. This paper, for the first-time, shows that it is possible to run level-4 (i.e., fully autonomous driving) software on a single off-the-shelf card (Jetson AGX Xavier) for less than $1k, an order of magnitude less than the state-of-the-art systems, while meeting all the requirements of latency. The success comes from the resolution of some important issues shared by existing practices through a series of measures and innovations. The study overturns the common perceptions of the computing resources required by level-4 autonomous driving, points out a promising path for the industry to lower the cost, and suggests a number of research opportunities for rethinking the architecture, software design, and optimizations of autonomous driving.
Elastic Significant Bit Quantization and Acceleration for Deep Neural Networks
Sep 08, 2021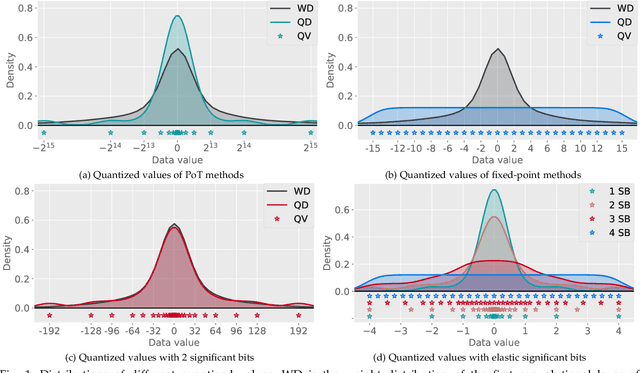
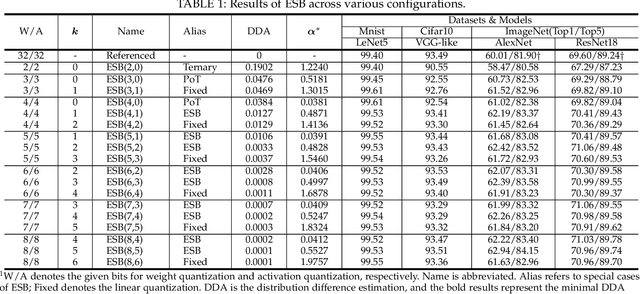
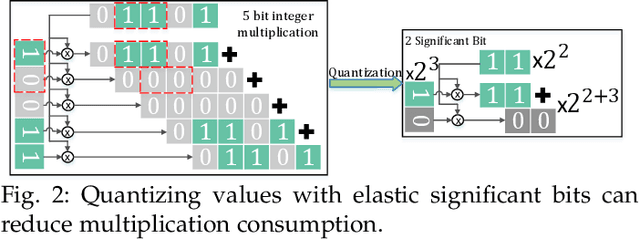
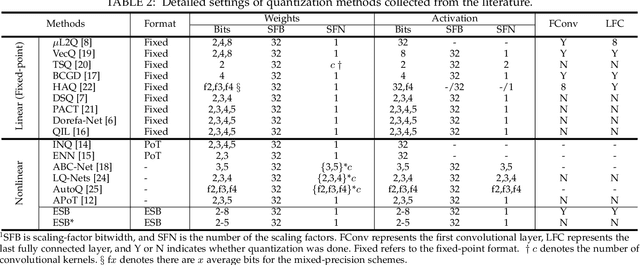
Quantization has been proven to be a vital method for improving the inference efficiency of deep neural networks (DNNs). However, it is still challenging to strike a good balance between accuracy and efficiency while quantizing DNN weights or activation values from high-precision formats to their quantized counterparts. We propose a new method called elastic significant bit quantization (ESB) that controls the number of significant bits of quantized values to obtain better inference accuracy with fewer resources. We design a unified mathematical formula to constrain the quantized values of the ESB with a flexible number of significant bits. We also introduce a distribution difference aligner (DDA) to quantitatively align the distributions between the full-precision weight or activation values and quantized values. Consequently, ESB is suitable for various bell-shaped distributions of weights and activation of DNNs, thus maintaining a high inference accuracy. Benefitting from fewer significant bits of quantized values, ESB can reduce the multiplication complexity. We implement ESB as an accelerator and quantitatively evaluate its efficiency on FPGAs. Extensive experimental results illustrate that ESB quantization consistently outperforms state-of-the-art methods and achieves average accuracy improvements of 4.78%, 1.92%, and 3.56% over AlexNet, ResNet18, and MobileNetV2, respectively. Furthermore, ESB as an accelerator can achieve 10.95 GOPS peak performance of 1k LUTs without DSPs on the Xilinx ZCU102 FPGA platform. Compared with CPU, GPU, and state-of-the-art accelerators on FPGAs, the ESB accelerator can improve the energy efficiency by up to 65x, 11x, and 26x, respectively.
DNNFusion: Accelerating Deep Neural Networks Execution with Advanced Operator Fusion
Aug 30, 2021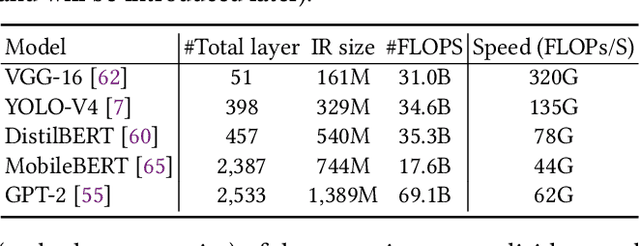
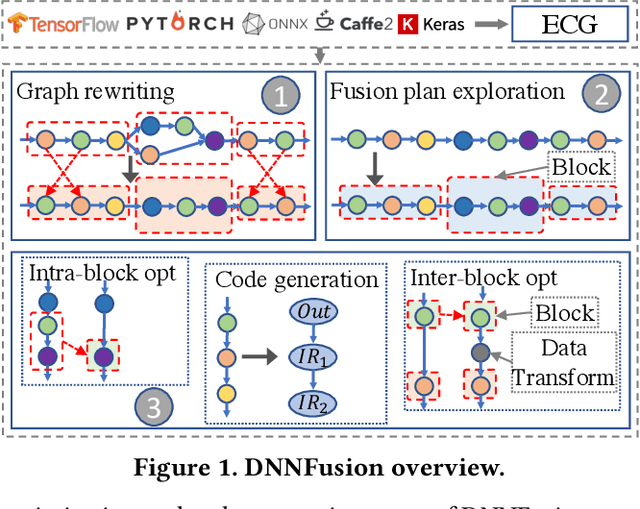

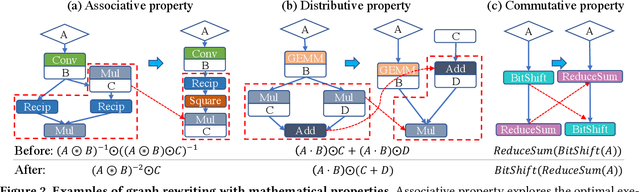
Deep Neural Networks (DNNs) have emerged as the core enabler of many major applications on mobile devices. To achieve high accuracy, DNN models have become increasingly deep with hundreds or even thousands of operator layers, leading to high memory and computational requirements for inference. Operator fusion (or kernel/layer fusion) is key optimization in many state-of-the-art DNN execution frameworks, such as TensorFlow, TVM, and MNN. However, these frameworks usually adopt fusion approaches based on certain patterns that are too restrictive to cover the diversity of operators and layer connections. Polyhedral-based loop fusion techniques, on the other hand, work on a low-level view of the computation without operator-level information, and can also miss potential fusion opportunities. To address this challenge, this paper proposes a novel and extensive loop fusion framework called DNNFusion. The basic idea of this work is to work at an operator view of DNNs, but expand fusion opportunities by developing a classification of both individual operators and their combinations. In addition, DNNFusion includes 1) a novel mathematical-property-based graph rewriting framework to reduce evaluation costs and facilitate subsequent operator fusion, 2) an integrated fusion plan generation that leverages the high-level analysis and accurate light-weight profiling, and 3) additional optimizations during fusion code generation. DNNFusion is extensively evaluated on 15 DNN models with varied types of tasks, model sizes, and layer counts. The evaluation results demonstrate that DNNFusion finds up to 8.8x higher fusion opportunities, outperforms four state-of-the-art DNN execution frameworks with 9.3x speedup. The memory requirement reduction and speedups can enable the execution of many of the target models on mobile devices and even make them part of a real-time application.
GRIM: A General, Real-Time Deep Learning Inference Framework for Mobile Devices based on Fine-Grained Structured Weight Sparsity
Aug 25, 2021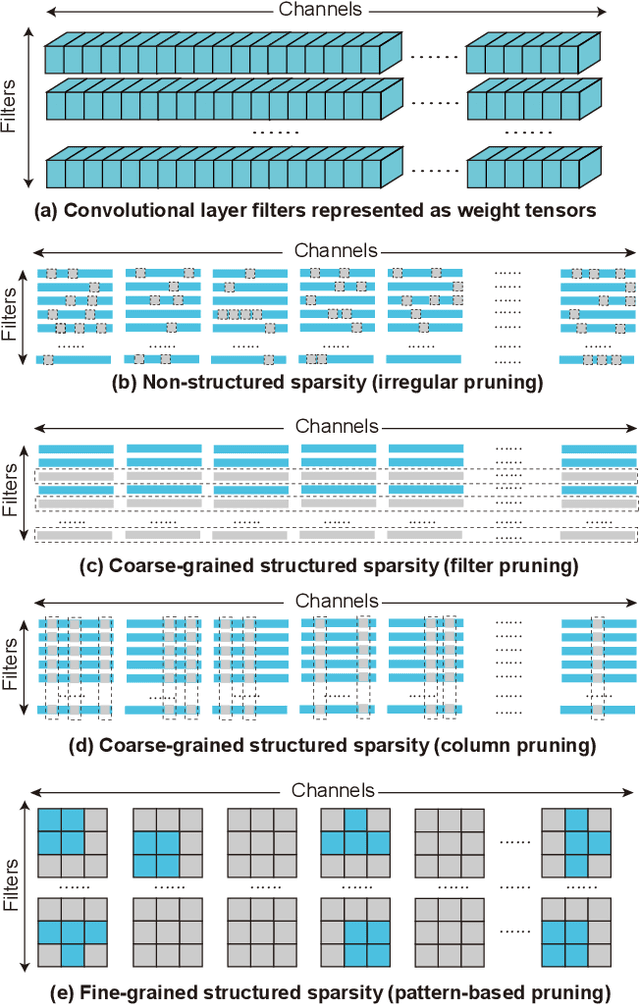
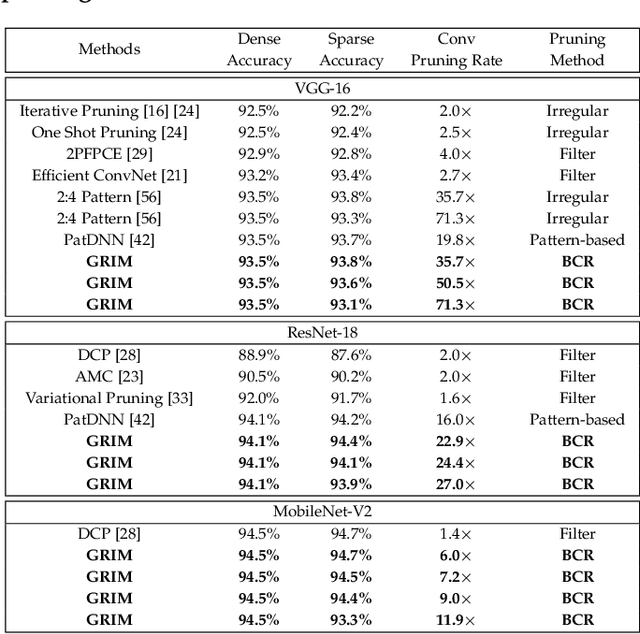
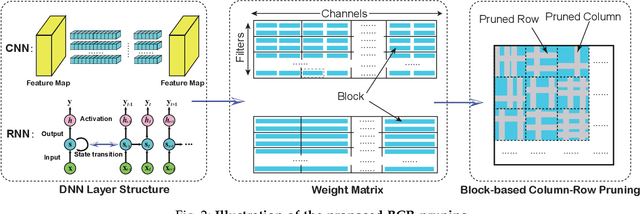
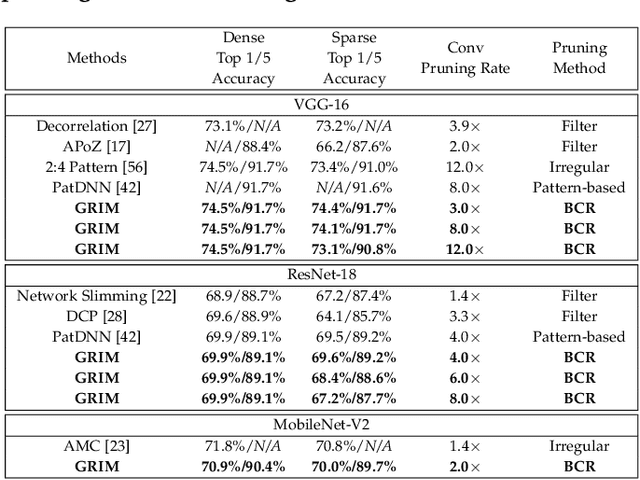
It is appealing but challenging to achieve real-time deep neural network (DNN) inference on mobile devices because even the powerful modern mobile devices are considered as ``resource-constrained'' when executing large-scale DNNs. It necessitates the sparse model inference via weight pruning, i.e., DNN weight sparsity, and it is desirable to design a new DNN weight sparsity scheme that can facilitate real-time inference on mobile devices while preserving a high sparse model accuracy. This paper designs a novel mobile inference acceleration framework GRIM that is General to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) and that achieves Real-time execution and high accuracy, leveraging fine-grained structured sparse model Inference and compiler optimizations for Mobiles. We start by proposing a new fine-grained structured sparsity scheme through the Block-based Column-Row (BCR) pruning. Based on this new fine-grained structured sparsity, our GRIM framework consists of two parts: (a) the compiler optimization and code generation for real-time mobile inference; and (b) the BCR pruning optimizations for determining pruning hyperparameters and performing weight pruning. We compare GRIM with Alibaba MNN, TVM, TensorFlow-Lite, a sparse implementation based on CSR, PatDNN, and ESE (a representative FPGA inference acceleration framework for RNNs), and achieve up to 14.08x speedup.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021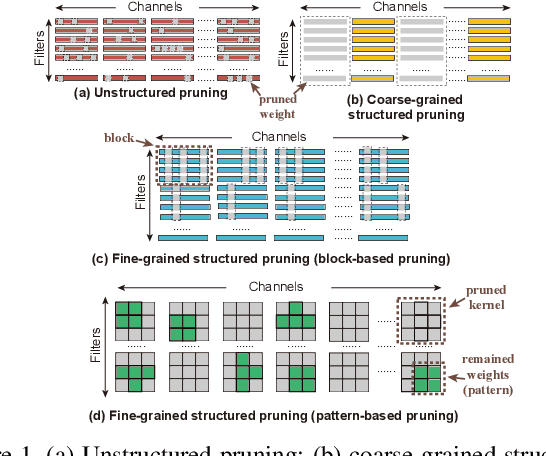
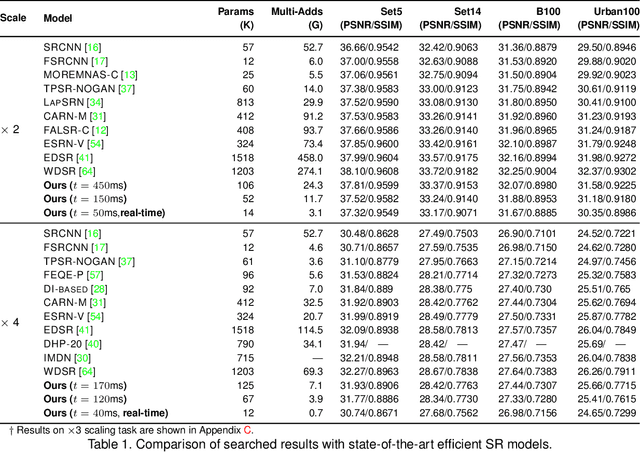
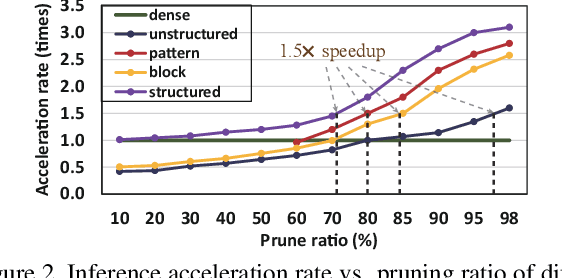
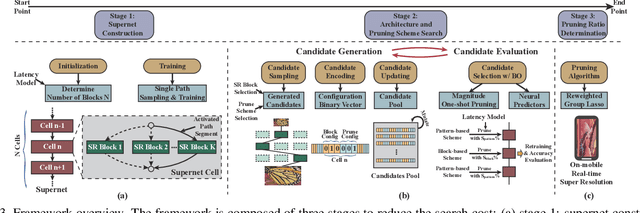
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
CAP-RAM: A Charge-Domain In-Memory Computing 6T-SRAM for Accurate and Precision-Programmable CNN Inference
Jul 06, 2021

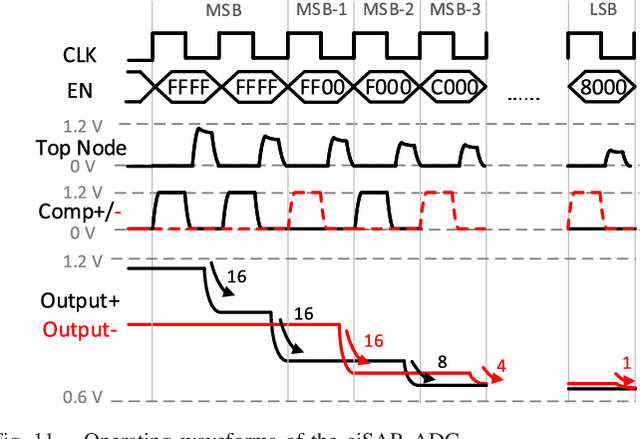
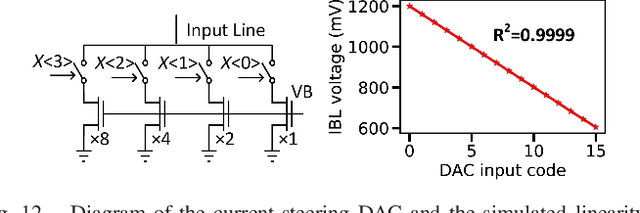
A compact, accurate, and bitwidth-programmable in-memory computing (IMC) static random-access memory (SRAM) macro, named CAP-RAM, is presented for energy-efficient convolutional neural network (CNN) inference. It leverages a novel charge-domain multiply-and-accumulate (MAC) mechanism and circuitry to achieve superior linearity under process variations compared to conventional IMC designs. The adopted semi-parallel architecture efficiently stores filters from multiple CNN layers by sharing eight standard 6T SRAM cells with one charge-domain MAC circuit. Moreover, up to six levels of bit-width of weights with two encoding schemes and eight levels of input activations are supported. A 7-bit charge-injection SAR (ciSAR) analog-to-digital converter (ADC) getting rid of sample and hold (S&H) and input/reference buffers further improves the overall energy efficiency and throughput. A 65-nm prototype validates the excellent linearity and computing accuracy of CAP-RAM. A single 512x128 macro stores a complete pruned and quantized CNN model to achieve 98.8% inference accuracy on the MNIST data set and 89.0% on the CIFAR-10 data set, with a 573.4-giga operations per second (GOPS) peak throughput and a 49.4-tera operations per second (TOPS)/W energy efficiency.
* This work has been accepted by IEEE Journal of Solid-State Circuits (JSSC 2021)
Sanity Checks for Lottery Tickets: Does Your Winning Ticket Really Win the Jackpot?
Jul 01, 2021
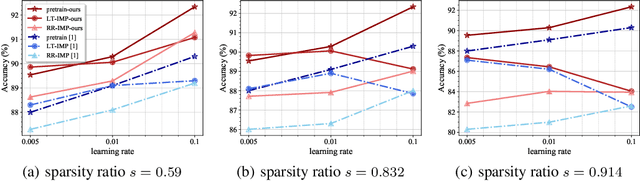
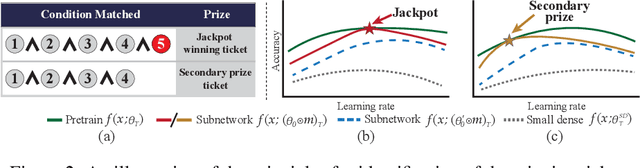

There have been long-standing controversies and inconsistencies over the experiment setup and criteria for identifying the "winning ticket" in literature. To reconcile such, we revisit the definition of lottery ticket hypothesis, with comprehensive and more rigorous conditions. Under our new definition, we show concrete evidence to clarify whether the winning ticket exists across the major DNN architectures and/or applications. Through extensive experiments, we perform quantitative analysis on the correlations between winning tickets and various experimental factors, and empirically study the patterns of our observations. We find that the key training hyperparameters, such as learning rate and training epochs, as well as the architecture characteristics such as capacities and residual connections, are all highly correlated with whether and when the winning tickets can be identified. Based on our analysis, we summarize a guideline for parameter settings in regards of specific architecture characteristics, which we hope to catalyze the research progress on the topic of lottery ticket hypothesis.
Achieving Real-Time Object Detection on MobileDevices with Neural Pruning Search
Jun 28, 2021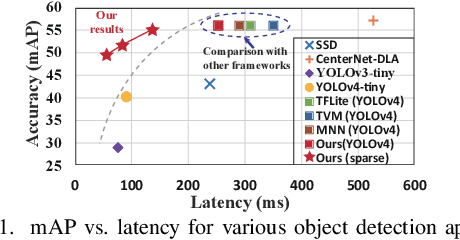
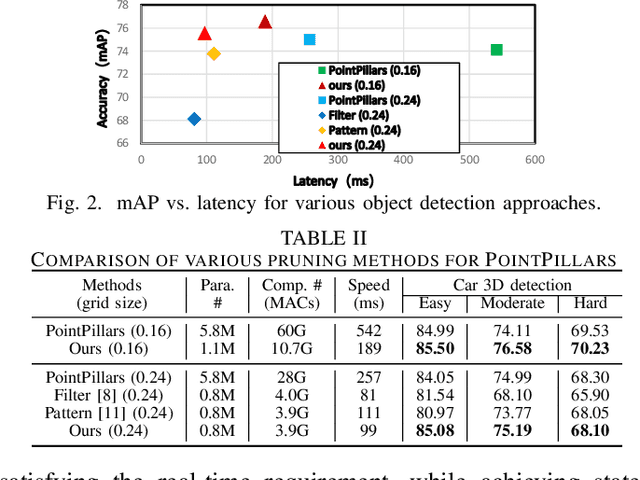
Object detection plays an important role in self-driving cars for security development. However, mobile systems on self-driving cars with limited computation resources lead to difficulties for object detection. To facilitate this, we propose a compiler-aware neural pruning search framework to achieve high-speed inference on autonomous vehicles for 2D and 3D object detection. The framework automatically searches the pruning scheme and rate for each layer to find a best-suited pruning for optimizing detection accuracy and speed performance under compiler optimization. Our experiments demonstrate that for the first time, the proposed method achieves (close-to) real-time, 55ms and 99ms inference times for YOLOv4 based 2D object detection and PointPillars based 3D detection, respectively, on an off-the-shelf mobile phone with minor (or no) accuracy loss.
Improving DNN Fault Tolerance using Weight Pruning and Differential Crossbar Mapping for ReRAM-based Edge AI
Jun 18, 2021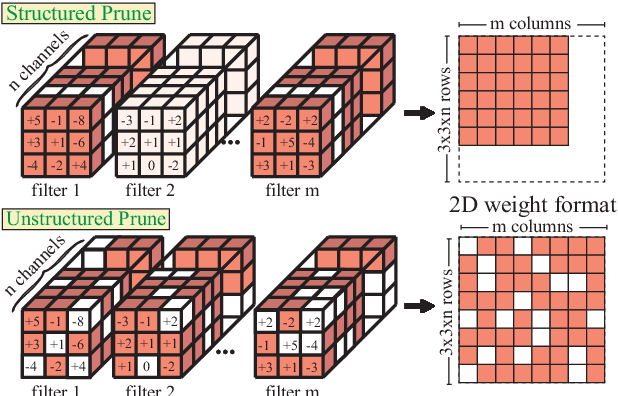
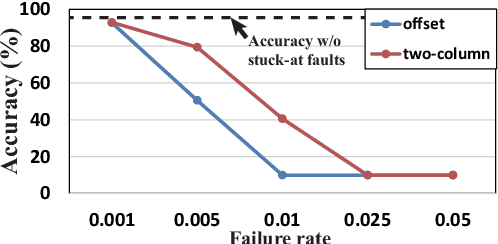
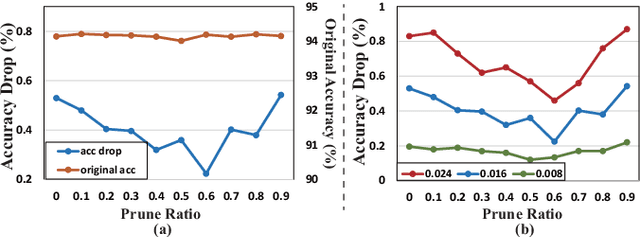
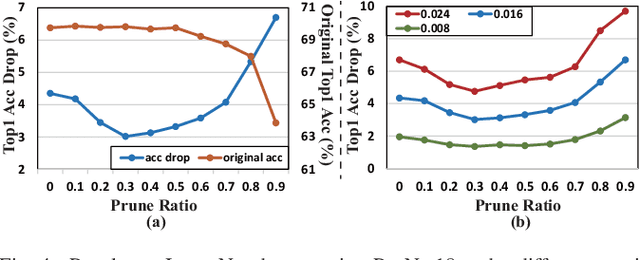
Recent research demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in deep neural networks (DNNs). However, hardware failure, such as stuck-at-fault defects, is one of the main concerns that impedes the ReRAM devices to be a feasible solution for real implementations. The existing solutions to address this issue usually require an optimization to be conducted for each individual device, which is impractical for mass-produced products (e.g., IoT devices). In this paper, we rethink the value of weight pruning in ReRAM-based DNN design from the perspective of model fault tolerance. And a differential mapping scheme is proposed to improve the fault tolerance under a high stuck-on fault rate. Our method can tolerate almost an order of magnitude higher failure rate than the traditional two-column method in representative DNN tasks. More importantly, our method does not require extra hardware cost compared to the traditional two-column mapping scheme. The improvement is universal and does not require the optimization process for each individual device.