 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models
Dec 17, 2025The text encoder is a critical component of text-to-image and text-to-video diffusion models, fundamentally determining the semantic fidelity of the generated content. However, its development has been hindered by two major challenges: the lack of an efficient evaluation framework that reliably predicts downstream generation performance, and the difficulty of effectively adapting pretrained language models for visual synthesis. To address these issues, we introduce GRAN-TED, a paradigm to Generate Robust, Aligned, and Nuanced Text Embeddings for Diffusion models. Our contribution is twofold. First, we propose TED-6K, a novel text-only benchmark that enables efficient and robust assessment of an encoder's representational quality without requiring costly end-to-end model training. We demonstrate that performance on TED-6K, standardized via a lightweight, unified adapter, strongly correlates with an encoder's effectiveness in downstream generation tasks. Second, guided by this validated framework, we develop a superior text encoder using a novel two-stage training paradigm. This process involves an initial fine-tuning stage on a Multimodal Large Language Model for better visual representation, followed by a layer-wise weighting method to extract more nuanced and potent text features. Our experiments show that the resulting GRAN-TED encoder not only achieves state-of-the-art performance on TED-6K but also leads to demonstrable performance gains in text-to-image and text-to-video generation. Our code is available at the following link: https://anonymous.4open.science/r/GRAN-TED-4FCC/.
Scone: Bridging Composition and Distinction in Subject-Driven Image Generation via Unified Understanding-Generation Modeling
Dec 14, 2025



Subject-driven image generation has advanced from single- to multi-subject composition, while neglecting distinction, the ability to identify and generate the correct subject when inputs contain multiple candidates. This limitation restricts effectiveness in complex, realistic visual settings. We propose Scone, a unified understanding-generation method that integrates composition and distinction. Scone enables the understanding expert to act as a semantic bridge, conveying semantic information and guiding the generation expert to preserve subject identity while minimizing interference. A two-stage training scheme first learns composition, then enhances distinction through semantic alignment and attention-based masking. We also introduce SconeEval, a benchmark for evaluating both composition and distinction across diverse scenarios. Experiments demonstrate that Scone outperforms existing open-source models in composition and distinction tasks on two benchmarks. Our model, benchmark, and training data are available at: https://github.com/Ryann-Ran/Scone.
The Unseen Bias: How Norm Discrepancy in Pre-Norm MLLMs Leads to Visual Information Loss
Dec 09, 2025



Multimodal Large Language Models (MLLMs), which couple pre-trained vision encoders and language models, have shown remarkable capabilities. However, their reliance on the ubiquitous Pre-Norm architecture introduces a subtle yet critical flaw: a severe norm disparity between the high-norm visual tokens and the low-norm text tokens. In this work, we present a formal theoretical analysis demonstrating that this imbalance is not a static issue. Instead, it induces an ``asymmetric update dynamic,'' where high-norm visual tokens exhibit a ``representational inertia,'' causing them to transform semantically much slower than their textual counterparts. This fundamentally impairs effective cross-modal feature fusion. Our empirical validation across a range of mainstream MLLMs confirms that this theoretical dynamic -- the persistence of norm disparity and the resulting asymmetric update rates -- is a prevalent phenomenon. Based on this insight, we propose a remarkably simple yet effective solution: inserting a single, carefully initialized LayerNorm layer after the visual projector to enforce norm alignment. Experiments conducted on the LLaVA-1.5 architecture show that this intervention yields significant performance gains not only on a wide suite of multimodal benchmarks but also, notably, on text-only evaluations such as MMLU, suggesting that resolving the architectural imbalance leads to a more holistically capable model.
PR-CapsNet: Pseudo-Riemannian Capsule Network with Adaptive Curvature Routing for Graph Learning
Dec 09, 2025Capsule Networks (CapsNets) show exceptional graph representation capacity via dynamic routing and vectorized hierarchical representations, but they model the complex geometries of real\-world graphs poorly by fixed\-curvature space due to the inherent geodesical disconnectedness issues, leading to suboptimal performance. Recent works find that non\-Euclidean pseudo\-Riemannian manifolds provide specific inductive biases for embedding graph data, but how to leverage them to improve CapsNets is still underexplored. Here, we extend the Euclidean capsule routing into geodesically disconnected pseudo\-Riemannian manifolds and derive a Pseudo\-Riemannian Capsule Network (PR\-CapsNet), which models data in pseudo\-Riemannian manifolds of adaptive curvature, for graph representation learning. Specifically, PR\-CapsNet enhances the CapsNet with Adaptive Pseudo\-Riemannian Tangent Space Routing by utilizing pseudo\-Riemannian geometry. Unlike single\-curvature or subspace\-partitioning methods, PR\-CapsNet concurrently models hierarchical and cluster or cyclic graph structures via its versatile pseudo\-Riemannian metric. It first deploys Pseudo\-Riemannian Tangent Space Routing to decompose capsule states into spherical\-temporal and Euclidean\-spatial subspaces with diffeomorphic transformations. Then, an Adaptive Curvature Routing is developed to adaptively fuse features from different curvature spaces for complex graphs via a learnable curvature tensor with geometric attention from local manifold properties. Finally, a geometric properties\-preserved Pseudo\-Riemannian Capsule Classifier is developed to project capsule embeddings to tangent spaces and use curvature\-weighted softmax for classification. Extensive experiments on node and graph classification benchmarks show PR\-CapsNet outperforms SOTA models, validating PR\-CapsNet's strong representation power for complex graph structures.
Hybrid Attribution Priors for Explainable and Robust Model Training
Dec 09, 2025Small language models (SLMs) are widely used in tasks that require low latency and lightweight deployment, particularly classification. As interpretability and robustness gain increasing importance, explanation-guided learning has emerged as an effective framework by introducing attribution-based supervision during training; however, deriving general and reliable attribution priors remains a significant challenge. Through an analysis of representative attribution methods in classification settings, we find that although these methods can reliably highlight class-relevant tokens, they often focus on common keywords shared by semantically similar classes. Because such classes are already difficult to distinguish under standard training, these attributions provide insufficient discriminative cues, limiting their ability to improve model differentiation. To overcome this limitation, we propose Class-Aware Attribution Prior (CAP), a novel attribution prior extraction framework that guides language models toward capturing fine-grained class distinctions and producing more salient, discriminative attribution priors. Building on this idea, we further introduce CAP Hybrid, which combines priors from CAP with those from existing attribution techniques to form a more comprehensive and balanced supervisory signal. By aligning a model's self-attribution with these enriched priors, our approach encourages the learning of diverse, decision-relevant features. Extensive experiments in full-data, few-shot, and adversarial scenarios demonstrate that our method consistently enhances both interpretability and robustness.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

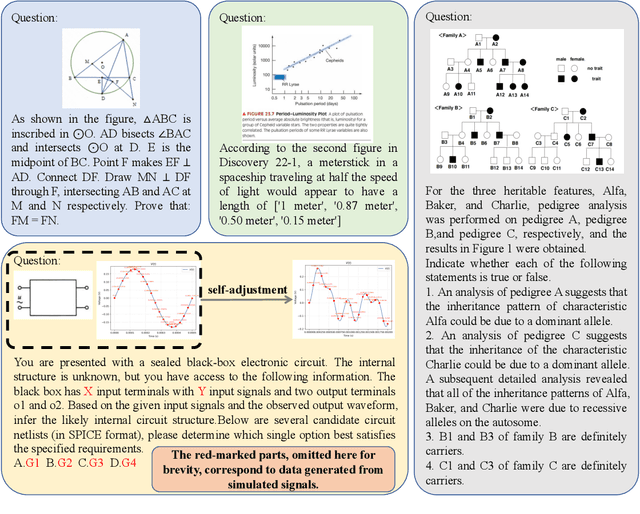
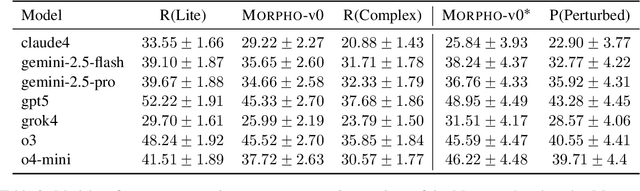
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
BaseReward: A Strong Baseline for Multimodal Reward Model
Sep 19, 2025



The rapid advancement of Multimodal Large Language Models (MLLMs) has made aligning them with human preferences a critical challenge. Reward Models (RMs) are a core technology for achieving this goal, but a systematic guide for building state-of-the-art Multimodal Reward Models (MRMs) is currently lacking in both academia and industry. Through exhaustive experimental analysis, this paper aims to provide a clear ``recipe'' for constructing high-performance MRMs. We systematically investigate every crucial component in the MRM development pipeline, including \textit{reward modeling paradigms} (e.g., Naive-RM, Critic-based RM, and Generative RM), \textit{reward head architecture}, \textit{training strategies}, \textit{data curation} (covering over ten multimodal and text-only preference datasets), \textit{backbone model} and \textit{model scale}, and \textit{ensemble methods}. Based on these experimental insights, we introduce \textbf{BaseReward}, a powerful and efficient baseline for multimodal reward modeling. BaseReward adopts a simple yet effective architecture, built upon a {Qwen2.5-VL} backbone, featuring an optimized two-layer reward head, and is trained on a carefully curated mixture of high-quality multimodal and text-only preference data. Our results show that BaseReward establishes a new SOTA on major benchmarks such as MM-RLHF-Reward Bench, VL-Reward Bench, and Multimodal Reward Bench, outperforming previous models. Furthermore, to validate its practical utility beyond static benchmarks, we integrate BaseReward into a real-world reinforcement learning pipeline, successfully enhancing an MLLM's performance across various perception, reasoning, and conversational tasks. This work not only delivers a top-tier MRM but, more importantly, provides the community with a clear, empirically-backed guide for developing robust reward models for the next generation of MLLMs.
Collaborative-Online-Learning-Enabled Distributionally Robust Motion Control for Multi-Robot Systems
Aug 24, 2025This paper develops a novel COllaborative-Online-Learning (COOL)-enabled motion control framework for multi-robot systems to avoid collision amid randomly moving obstacles whose motion distributions are partially observable through decentralized data streams. To address the notable challenge of data acquisition due to occlusion, a COOL approach based on the Dirichlet process mixture model is proposed to efficiently extract motion distribution information by exchanging among robots selected learning structures. By leveraging the fine-grained local-moment information learned through COOL, a data-stream-driven ambiguity set for obstacle motion is constructed. We then introduce a novel ambiguity set propagation method, which theoretically admits the derivation of the ambiguity sets for obstacle positions over the entire prediction horizon by utilizing obstacle current positions and the ambiguity set for obstacle motion. Additionally, we develop a compression scheme with its safety guarantee to automatically adjust the complexity and granularity of the ambiguity set by aggregating basic ambiguity sets that are close in a measure space, thereby striking an attractive trade-off between control performance and computation time. Then the probabilistic collision-free trajectories are generated through distributionally robust optimization problems. The distributionally robust obstacle avoidance constraints based on the compressed ambiguity set are equivalently reformulated by deriving separating hyperplanes through tractable semi-definite programming. Finally, we establish the probabilistic collision avoidance guarantee and the long-term tracking performance guarantee for the proposed framework. The numerical simulations are used to demonstrate the efficacy and superiority of the proposed approach compared with state-of-the-art methods.
VersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Jun 10, 2025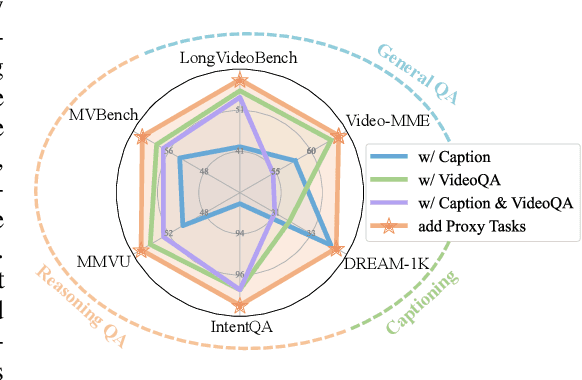

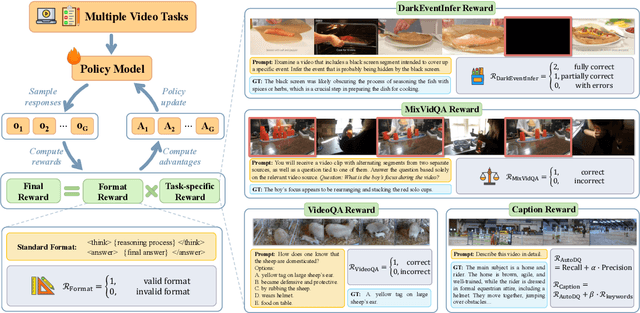

Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model's advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.
MME-VideoOCR: Evaluating OCR-Based Capabilities of Multimodal LLMs in Video Scenarios
May 27, 2025Multimodal Large Language Models (MLLMs) have achieved considerable accuracy in Optical Character Recognition (OCR) from static images. However, their efficacy in video OCR is significantly diminished due to factors such as motion blur, temporal variations, and visual effects inherent in video content. To provide clearer guidance for training practical MLLMs, we introduce the MME-VideoOCR benchmark, which encompasses a comprehensive range of video OCR application scenarios. MME-VideoOCR features 10 task categories comprising 25 individual tasks and spans 44 diverse scenarios. These tasks extend beyond text recognition to incorporate deeper comprehension and reasoning of textual content within videos. The benchmark consists of 1,464 videos with varying resolutions, aspect ratios, and durations, along with 2,000 meticulously curated, manually annotated question-answer pairs. We evaluate 18 state-of-the-art MLLMs on MME-VideoOCR, revealing that even the best-performing model (Gemini-2.5 Pro) achieves an accuracy of only 73.7%. Fine-grained analysis indicates that while existing MLLMs demonstrate strong performance on tasks where relevant texts are contained within a single or few frames, they exhibit limited capability in effectively handling tasks that demand holistic video comprehension. These limitations are especially evident in scenarios that require spatio-temporal reasoning, cross-frame information integration, or resistance to language prior bias. Our findings also highlight the importance of high-resolution visual input and sufficient temporal coverage for reliable OCR in dynamic video scenarios.