 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniReg: Foundation Model for Controllable Medical Image Registration
Mar 17, 2025



Learning-based medical image registration has achieved performance parity with conventional methods while demonstrating a substantial advantage in computational efficiency. However, learning-based registration approaches lack generalizability across diverse clinical scenarios, requiring the laborious development of multiple isolated networks for specific registration tasks, e.g., inter-/intra-subject registration or organ-specific alignment. % To overcome this limitation, we propose \textbf{UniReg}, the first interactive foundation model for medical image registration, which combines the precision advantages of task-specific learning methods with the generalization of traditional optimization methods. Our key innovation is a unified framework for diverse registration scenarios, achieved through a conditional deformation field estimation within a unified registration model. This is realized through a dynamic learning paradigm that explicitly encodes: (1) anatomical structure priors, (2) registration type constraints (inter/intra-subject), and (3) instance-specific features, enabling the generation of scenario-optimal deformation fields. % Through comprehensive experiments encompassing $90$ anatomical structures at different body regions, our UniReg model demonstrates comparable performance with contemporary state-of-the-art methodologies while achieving ~50\% reduction in required training iterations relative to the conventional learning-based paradigm. This optimization contributes to a significant reduction in computational resources, such as training time. Code and model will be available.
Leveraging Semantic Asymmetry for Precise Gross Tumor Volume Segmentation of Nasopharyngeal Carcinoma in Planning CT
Nov 27, 2024



In the radiation therapy of nasopharyngeal carcinoma (NPC), clinicians typically delineate the gross tumor volume (GTV) using non-contrast planning computed tomography to ensure accurate radiation dose delivery. However, the low contrast between tumors and adjacent normal tissues necessitates that radiation oncologists manually delineate the tumors, often relying on diagnostic MRI for guidance. % In this study, we propose a novel approach to directly segment NPC gross tumors on non-contrast planning CT images, circumventing potential registration errors when aligning MRI or MRI-derived tumor masks to planning CT. To address the low contrast issues between tumors and adjacent normal structures in planning CT, we introduce a 3D Semantic Asymmetry Tumor segmentation (SATs) method. Specifically, we posit that a healthy nasopharyngeal region is characteristically bilaterally symmetric, whereas the emergence of nasopharyngeal carcinoma disrupts this symmetry. Then, we propose a Siamese contrastive learning segmentation framework that minimizes the voxel-wise distance between original and flipped areas without tumor and encourages a larger distance between original and flipped areas with tumor. Thus, our approach enhances the sensitivity of features to semantic asymmetries. % Extensive experiments demonstrate that the proposed SATs achieves the leading NPC GTV segmentation performance in both internal and external testing, \emph{e.g.}, with at least 2\% absolute Dice score improvement and 12\% average distance error reduction when compared to other state-of-the-art methods in the external testing.
A Joint Representation Using Continuous and Discrete Features for Cardiovascular Diseases Risk Prediction on Chest CT Scans
Oct 24, 2024



Cardiovascular diseases (CVD) remain a leading health concern and contribute significantly to global mortality rates. While clinical advancements have led to a decline in CVD mortality, accurately identifying individuals who could benefit from preventive interventions remains an unsolved challenge in preventive cardiology. Current CVD risk prediction models, recommended by guidelines, are based on limited traditional risk factors or use CT imaging to acquire quantitative biomarkers, and still have limitations in predictive accuracy and applicability. On the other hand, end-to-end trained CVD risk prediction methods leveraging deep learning on CT images often fail to provide transparent and explainable decision grounds for assisting physicians. In this work, we proposed a novel joint representation that integrates discrete quantitative biomarkers and continuous deep features extracted from chest CT scans. Our approach initiated with a deep CVD risk classification model by capturing comprehensive continuous deep learning features while jointly obtaining currently clinical-established quantitative biomarkers via segmentation models. In the feature joint representation stage, we use an instance-wise feature-gated mechanism to align the continuous and discrete features, followed by a soft instance-wise feature interaction mechanism fostering independent and effective feature interaction for the final CVD risk prediction. Our method substantially improves CVD risk predictive performance and offers individual contribution analysis of each biomarker, which is important in assisting physicians' decision-making processes. We validated our method on a public chest low-dose CT dataset and a private external chest standard-dose CT patient cohort of 17,207 CT volumes from 6,393 unique subjects, and demonstrated superior predictive performance, achieving AUCs of 0.875 and 0.843, respectively.
Cross-Phase Mutual Learning Framework for Pulmonary Embolism Identification on Non-Contrast CT Scans
Jul 16, 2024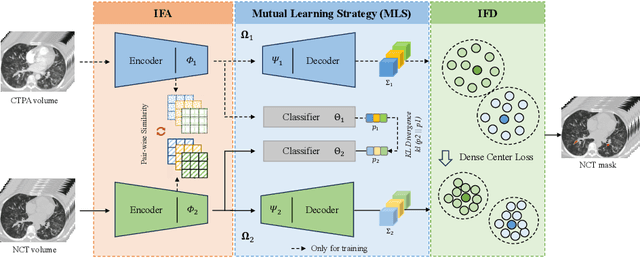

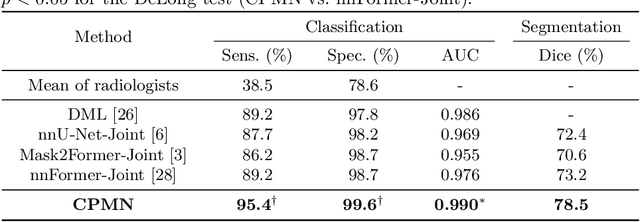
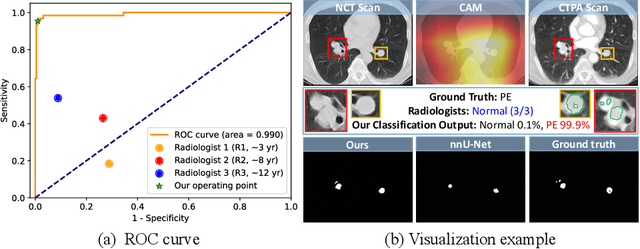
Pulmonary embolism (PE) is a life-threatening condition where rapid and accurate diagnosis is imperative yet difficult due to predominantly atypical symptomatology. Computed tomography pulmonary angiography (CTPA) is acknowledged as the gold standard imaging tool in clinics, yet it can be contraindicated for emergency department (ED) patients and represents an onerous procedure, thus necessitating PE identification through non-contrast CT (NCT) scans. In this work, we explore the feasibility of applying a deep-learning approach to NCT scans for PE identification. We propose a novel Cross-Phase Mutual learNing framework (CPMN) that fosters knowledge transfer from CTPA to NCT, while concurrently conducting embolism segmentation and abnormality classification in a multi-task manner. The proposed CPMN leverages the Inter-Feature Alignment (IFA) strategy that enhances spatial contiguity and mutual learning between the dual-pathway network, while the Intra-Feature Discrepancy (IFD) strategy can facilitate precise segmentation of PE against complex backgrounds for single-pathway networks. For a comprehensive assessment of the proposed approach, a large-scale dual-phase dataset containing 334 PE patients and 1,105 normal subjects has been established. Experimental results demonstrate that CPMN achieves the leading identification performance, which is 95.4\% and 99.6\% in patient-level sensitivity and specificity on NCT scans, indicating the potential of our approach as an economical, accessible, and precise tool for PE identification in clinical practice.
Rapid and Accurate Diagnosis of Acute Aortic Syndrome using Non-contrast CT: A Large-scale, Retrospective, Multi-center and AI-based Study
Jun 25, 2024



Chest pain symptoms are highly prevalent in emergency departments (EDs), where acute aortic syndrome (AAS) is a catastrophic cardiovascular emergency with a high fatality rate, especially when timely and accurate treatment is not administered. However, current triage practices in the ED can cause up to approximately half of patients with AAS to have an initially missed diagnosis or be misdiagnosed as having other acute chest pain conditions. Subsequently, these AAS patients will undergo clinically inaccurate or suboptimal differential diagnosis. Fortunately, even under these suboptimal protocols, nearly all these patients underwent non-contrast CT covering the aorta anatomy at the early stage of differential diagnosis. In this study, we developed an artificial intelligence model (DeepAAS) using non-contrast CT, which is highly accurate for identifying AAS and provides interpretable results to assist in clinical decision-making. Performance was assessed in two major phases: a multi-center retrospective study (n = 20,750) and an exploration in real-world emergency scenarios (n = 137,525). In the multi-center cohort, DeepAAS achieved a mean area under the receiver operating characteristic curve of 0.958 (95% CI 0.950-0.967). In the real-world cohort, DeepAAS detected 109 AAS patients with misguided initial suspicion, achieving 92.6% (95% CI 76.2%-97.5%) in mean sensitivity and 99.2% (95% CI 99.1%-99.3%) in mean specificity. Our AI model performed well on non-contrast CT at all applicable early stages of differential diagnosis workflows, effectively reduced the overall missed diagnosis and misdiagnosis rate from 48.8% to 4.8% and shortened the diagnosis time for patients with misguided initial suspicion from an average of 681.8 (74-11,820) mins to 68.5 (23-195) mins. DeepAAS could effectively fill the gap in the current clinical workflow without requiring additional tests.
Modality-Agnostic Structural Image Representation Learning for Deformable Multi-Modality Medical Image Registration
Feb 29, 2024



Establishing dense anatomical correspondence across distinct imaging modalities is a foundational yet challenging procedure for numerous medical image analysis studies and image-guided radiotherapy. Existing multi-modality image registration algorithms rely on statistical-based similarity measures or local structural image representations. However, the former is sensitive to locally varying noise, while the latter is not discriminative enough to cope with complex anatomical structures in multimodal scans, causing ambiguity in determining the anatomical correspondence across scans with different modalities. In this paper, we propose a modality-agnostic structural representation learning method, which leverages Deep Neighbourhood Self-similarity (DNS) and anatomy-aware contrastive learning to learn discriminative and contrast-invariance deep structural image representations (DSIR) without the need for anatomical delineations or pre-aligned training images. We evaluate our method on multiphase CT, abdomen MR-CT, and brain MR T1w-T2w registration. Comprehensive results demonstrate that our method is superior to the conventional local structural representation and statistical-based similarity measures in terms of discriminability and accuracy.
A Novel Multi-Task Model Imitating Dermatologists for Accurate Differential Diagnosis of Skin Diseases in Clinical Images
Jul 17, 2023



Skin diseases are among the most prevalent health issues, and accurate computer-aided diagnosis methods are of importance for both dermatologists and patients. However, most of the existing methods overlook the essential domain knowledge required for skin disease diagnosis. A novel multi-task model, namely DermImitFormer, is proposed to fill this gap by imitating dermatologists' diagnostic procedures and strategies. Through multi-task learning, the model simultaneously predicts body parts and lesion attributes in addition to the disease itself, enhancing diagnosis accuracy and improving diagnosis interpretability. The designed lesion selection module mimics dermatologists' zoom-in action, effectively highlighting the local lesion features from noisy backgrounds. Additionally, the presented cross-interaction module explicitly models the complicated diagnostic reasoning between body parts, lesion attributes, and diseases. To provide a more robust evaluation of the proposed method, a large-scale clinical image dataset of skin diseases with significantly more cases than existing datasets has been established. Extensive experiments on three different datasets consistently demonstrate the state-of-the-art recognition performance of the proposed approach.
Group Feature Learning and Domain Adversarial Neural Network for aMCI Diagnosis System Based on EEG
Apr 28, 2021
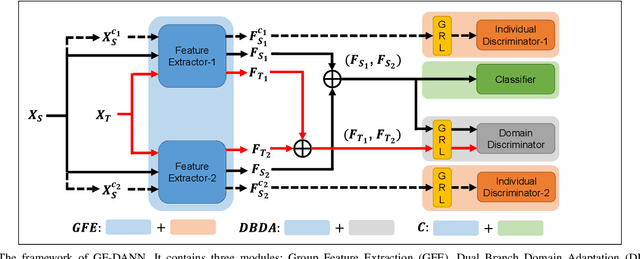
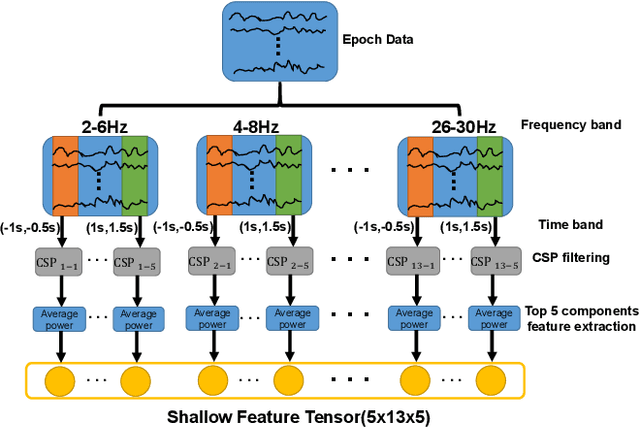
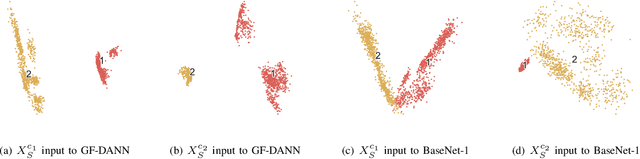
Medical diagnostic robot systems have been paid more and more attention due to its objectivity and accuracy. The diagnosis of mild cognitive impairment (MCI) is considered an effective means to prevent Alzheimer's disease (AD). Doctors diagnose MCI based on various clinical examinations, which are expensive and the diagnosis results rely on the knowledge of doctors. Therefore, it is necessary to develop a robot diagnostic system to eliminate the influence of human factors and obtain a higher accuracy rate. In this paper, we propose a novel Group Feature Domain Adversarial Neural Network (GF-DANN) for amnestic MCI (aMCI) diagnosis, which involves two important modules. A Group Feature Extraction (GFE) module is proposed to reduce individual differences by learning group-level features through adversarial learning. A Dual Branch Domain Adaptation (DBDA) module is carefully designed to reduce the distribution difference between the source and target domain in a domain adaption way. On three types of data set, GF-DANN achieves the best accuracy compared with classic machine learning and deep learning methods. On the DMS data set, GF-DANN has obtained an accuracy rate of 89.47%, and the sensitivity and specificity are 90% and 89%. In addition, by comparing three EEG data collection paradigms, our results demonstrate that the DMS paradigm has the potential to build an aMCI diagnose robot system.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020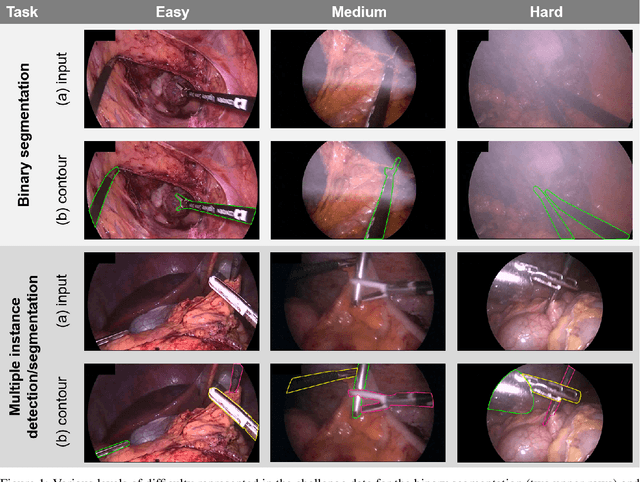
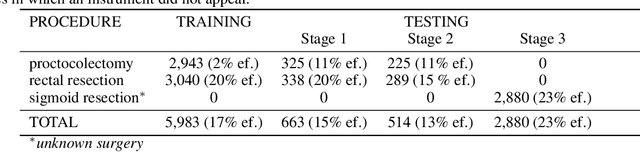
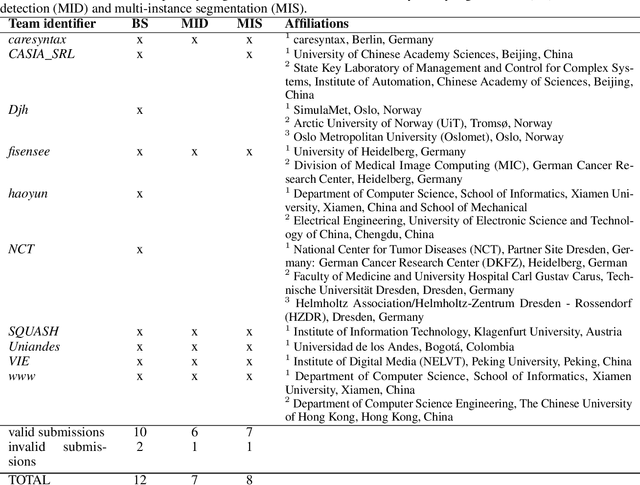
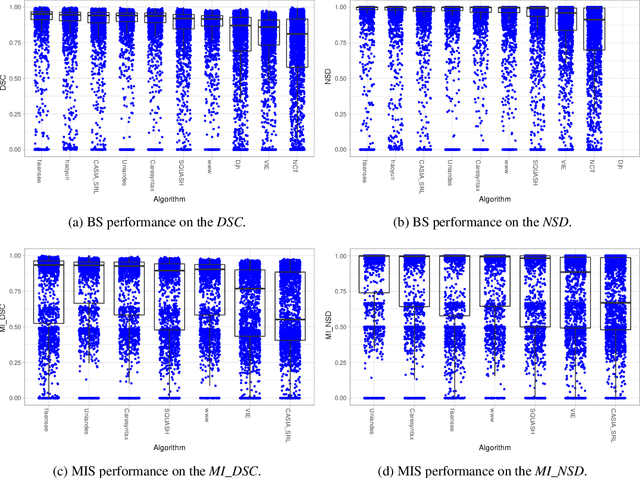
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
RAUNet: Residual Attention U-Net for Semantic Segmentation of Cataract Surgical Instruments
Oct 02, 2019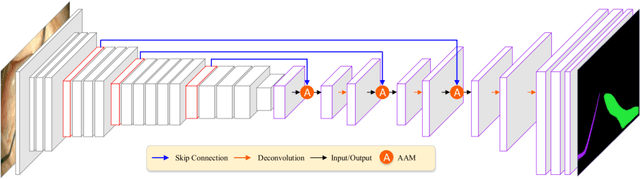
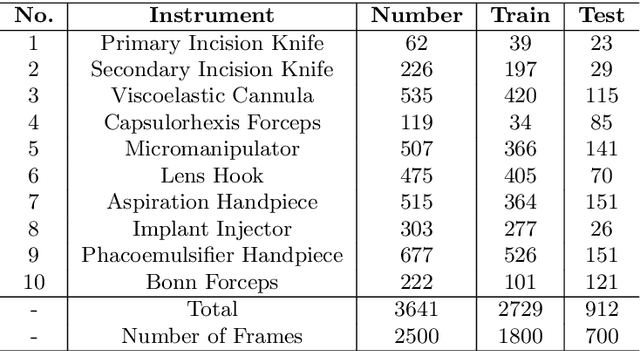
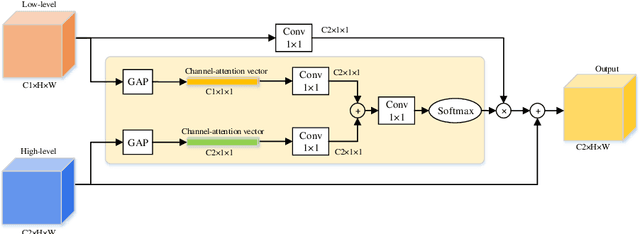
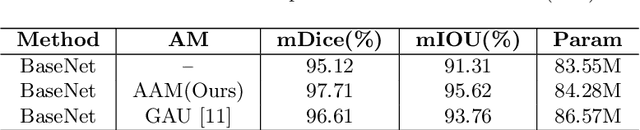
Semantic segmentation of surgical instruments plays a crucial role in robot-assisted surgery. However, accurate segmentation of cataract surgical instruments is still a challenge due to specular reflection and class imbalance issues. In this paper, an attention-guided network is proposed to segment the cataract surgical instrument. A new attention module is designed to learn discriminative features and address the specular reflection issue. It captures global context and encodes semantic dependencies to emphasize key semantic features, boosting the feature representation. This attention module has very few parameters, which helps to save memory. Thus, it can be flexibly plugged into other networks. Besides, a hybrid loss is introduced to train our network for addressing the class imbalance issue, which merges cross entropy and logarithms of Dice loss. A new dataset named Cata7 is constructed to evaluate our network. To the best of our knowledge, this is the first cataract surgical instrument dataset for semantic segmentation. Based on this dataset, RAUNet achieves state-of-the-art performance 97.71% mean Dice and 95.62% mean IOU.