 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022



The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020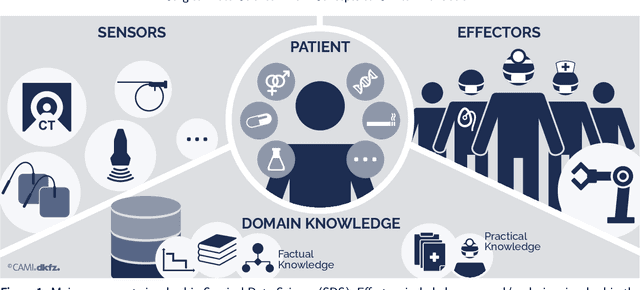
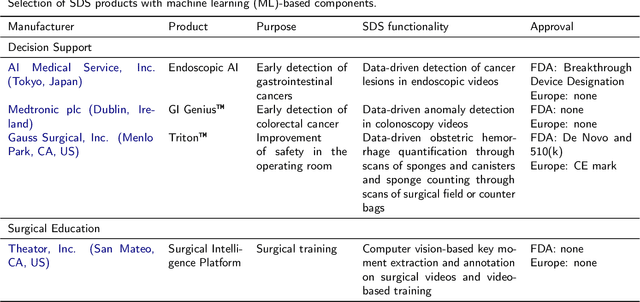
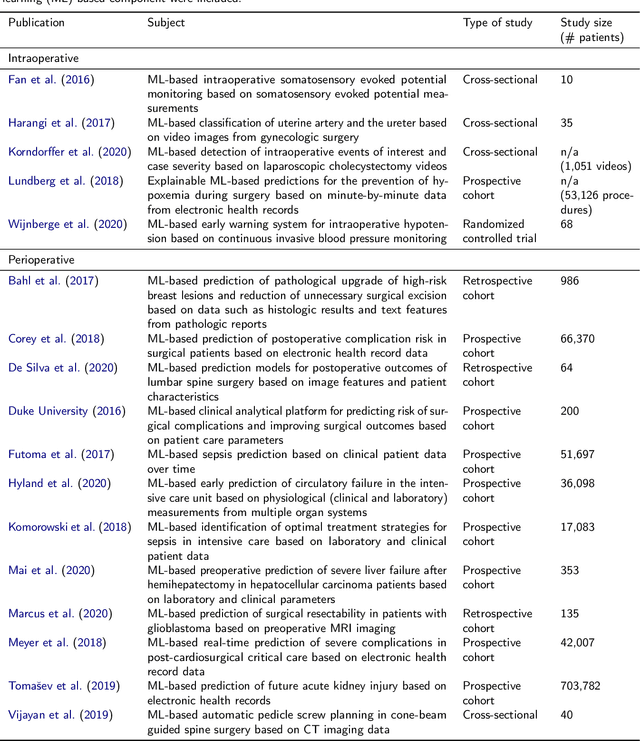
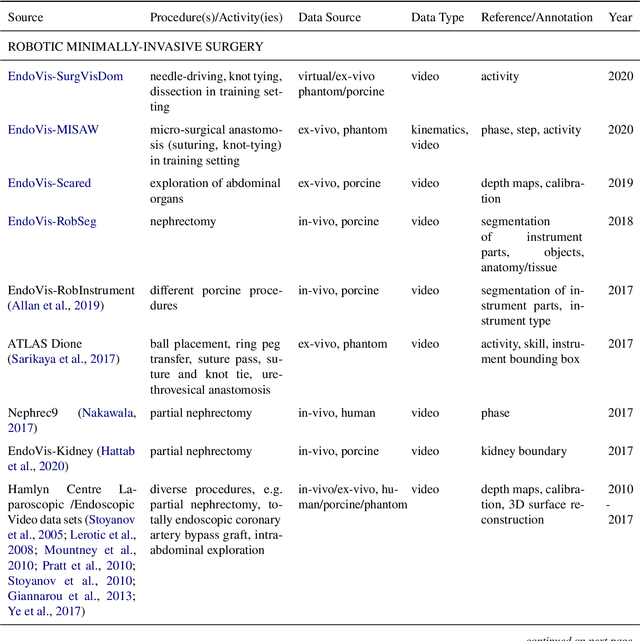
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020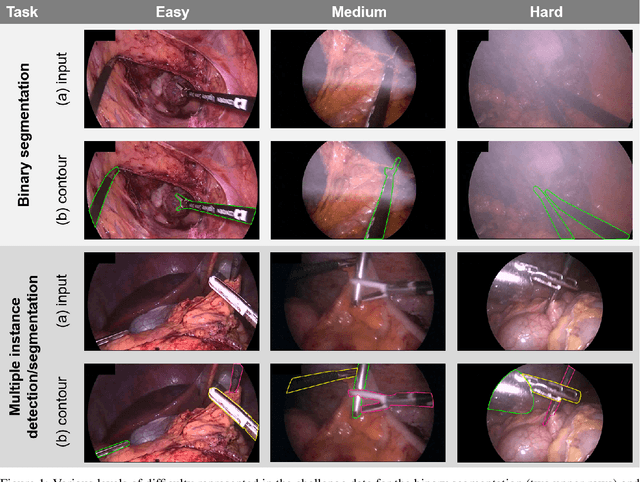
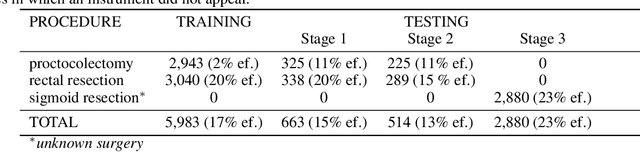
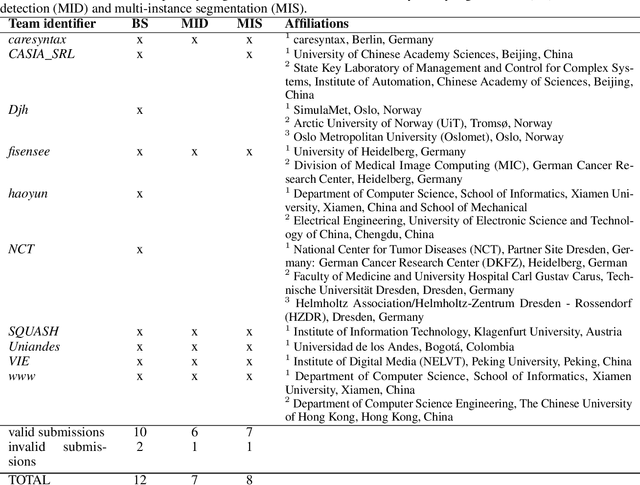
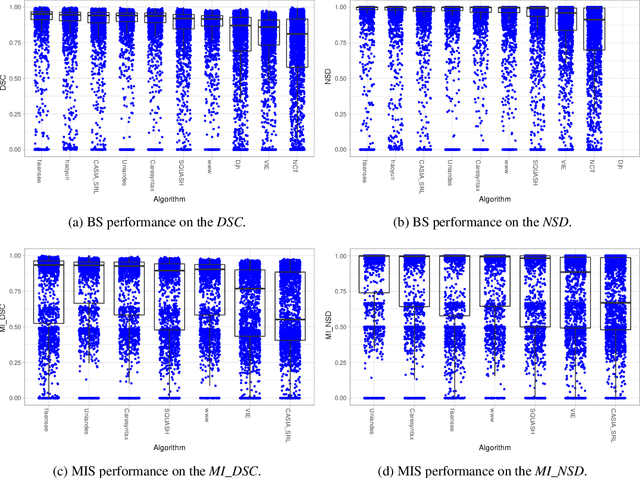
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Prediction of laparoscopic procedure duration using unlabeled, multimodal sensor data
Nov 08, 2018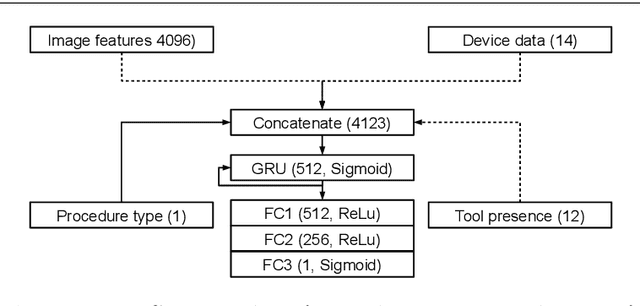
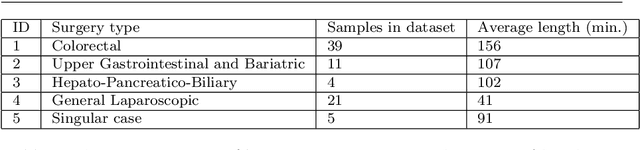
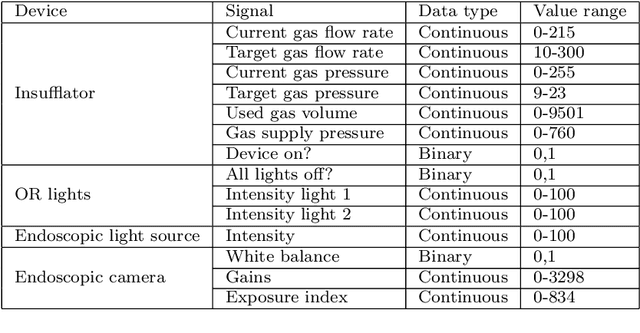
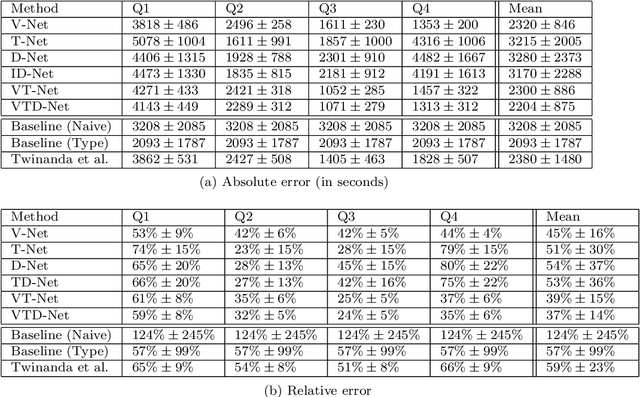
The course of surgical procedures is often unpredictable, making it difficult to estimate the duration of procedures beforehand. This uncertainty makes scheduling surgical procedures a difficult task. A context-aware method that analyses the workflow of an intervention online and automatically predicts the remaining duration would alleviate these problems. As basis for such an estimate, information regarding the current state of the intervention is a requirement. Today, the operating room contains a diverse range of sensors. During laparoscopic interventions, the endoscopic video stream is an ideal source of such information. Extracting quantitative information from the video is challenging though, due to its high dimensionality. Other surgical devices (e.g. insufflator, lights, etc.) provide data streams which are, in contrast to the video stream, more compact and easier to quantify. Though whether such streams offer sufficient information for estimating the duration of surgery is uncertain. In this paper, we propose and compare methods, based on convolutional neural networks, for continuously predicting the duration of laparoscopic interventions based on unlabeled data, such as from endoscopic image and surgical device streams. The methods are evaluated on 80 recorded laparoscopic interventions of various types, for which surgical device data and the endoscopic video streams are available. Here the combined method performs best with an overall average error of 37% and an average halftime error of approximately 28%.
Real-time image-based instrument classification for laparoscopic surgery
Aug 01, 2018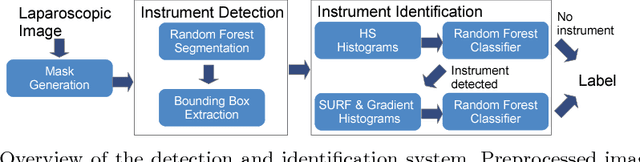
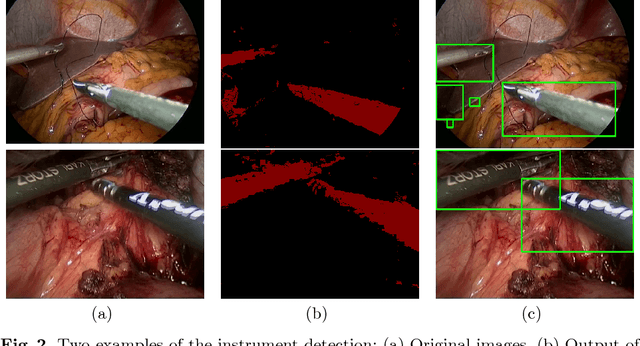


During laparoscopic surgery, context-aware assistance systems aim to alleviate some of the difficulties the surgeon faces. To ensure that the right information is provided at the right time, the current phase of the intervention has to be known. Real-time locating and classification the surgical tools currently in use are key components of both an activity-based phase recognition and assistance generation. In this paper, we present an image-based approach that detects and classifies tools during laparoscopic interventions in real-time. First, potential instrument bounding boxes are detected using a pixel-wise random forest segmentation. Each of these bounding boxes is then classified using a cascade of random forest. For this, multiple features, such as histograms over hue and saturation, gradients and SURF feature, are extracted from each detected bounding box. We evaluated our approach on five different videos from two different types of procedures. We distinguished between the four most common classes of instruments (LigaSure, atraumatic grasper, aspirator, clip applier) and background. Our method succesfully located up to 86% of all instruments respectively. On manually provided bounding boxes, we achieve a instrument type recognition rate of up to 58% and on automatically detected bounding boxes up to 49%. To our knowledge, this is the first approach that allows an image-based classification of surgical tools in a laparoscopic setting in real-time.
* Workshop paper accepted and presented at Modeling and Monitoring of Computer Assisted Interventions (M2CAI) (2015)
Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
May 07, 2018
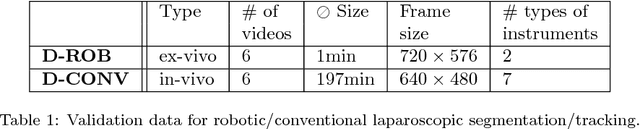

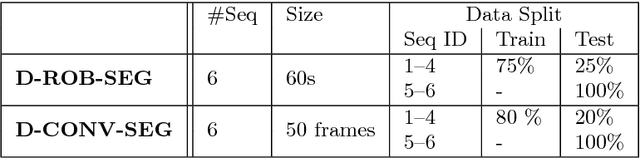
Intraoperative segmentation and tracking of minimally invasive instruments is a prerequisite for computer- and robotic-assisted surgery. Since additional hardware like tracking systems or the robot encoders are cumbersome and lack accuracy, surgical vision is evolving as promising techniques to segment and track the instruments using only the endoscopic images. However, what is missing so far are common image data sets for consistent evaluation and benchmarking of algorithms against each other. The paper presents a comparative validation study of different vision-based methods for instrument segmentation and tracking in the context of robotic as well as conventional laparoscopic surgery. The contribution of the paper is twofold: we introduce a comprehensive validation data set that was provided to the study participants and present the results of the comparative validation study. Based on the results of the validation study, we arrive at the conclusion that modern deep learning approaches outperform other methods in instrument segmentation tasks, but the results are still not perfect. Furthermore, we show that merging results from different methods actually significantly increases accuracy in comparison to the best stand-alone method. On the other hand, the results of the instrument tracking task show that this is still an open challenge, especially during challenging scenarios in conventional laparoscopic surgery.
Exploiting the potential of unlabeled endoscopic video data with self-supervised learning
Jan 31, 2018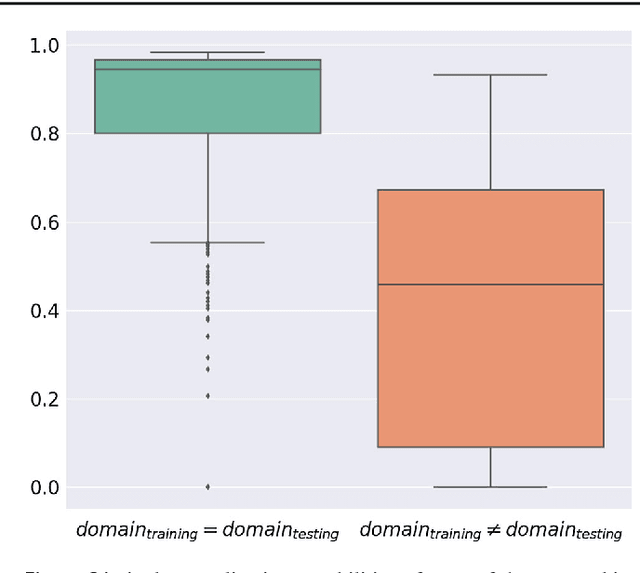
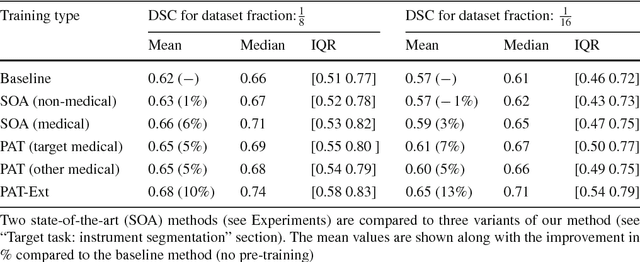
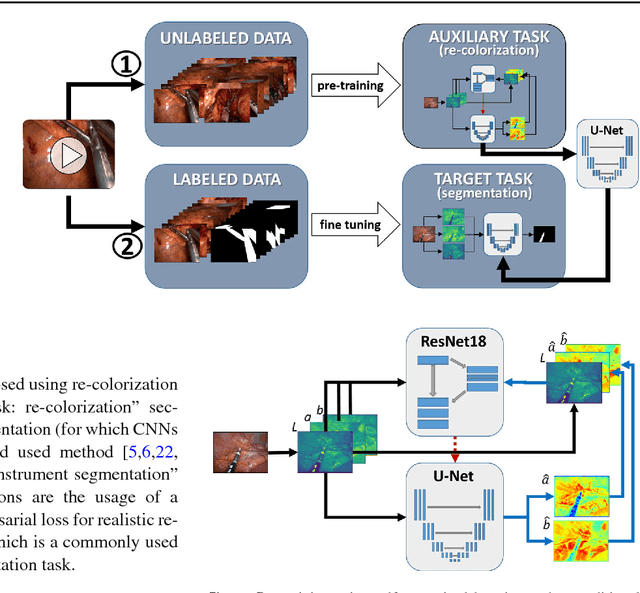
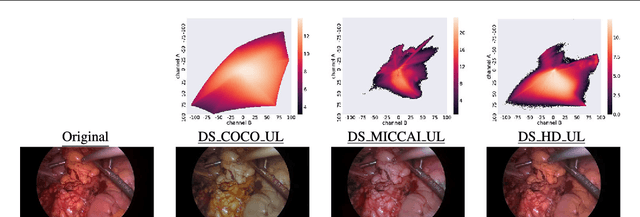
Surgical data science is a new research field that aims to observe all aspects of the patient treatment process in order to provide the right assistance at the right time. Due to the breakthrough successes of deep learning-based solutions for automatic image annotation, the availability of reference annotations for algorithm training is becoming a major bottleneck in the field. The purpose of this paper was to investigate the concept of self-supervised learning to address this issue. Our approach is guided by the hypothesis that unlabeled video data can be used to learn a representation of the target domain that boosts the performance of state-of-the-art machine learning algorithms when used for pre-training. Core of the method is an auxiliary task based on raw endoscopic video data of the target domain that is used to initialize the convolutional neural network (CNN) for the target task. In this paper, we propose the re-colorization of medical images with a generative adversarial network (GAN)-based architecture as auxiliary task. A variant of the method involves a second pre-training step based on labeled data for the target task from a related domain. We validate both variants using medical instrument segmentation as target task. The proposed approach can be used to radically reduce the manual annotation effort involved in training CNNs. Compared to the baseline approach of generating annotated data from scratch, our method decreases exploratively the number of labeled images by up to 75% without sacrificing performance. Our method also outperforms alternative methods for CNN pre-training, such as pre-training on publicly available non-medical or medical data using the target task (in this instance: segmentation). As it makes efficient use of available (non-)public and (un-)labeled data, the approach has the potential to become a valuable tool for CNN (pre-)training.
Unsupervised temporal context learning using convolutional neural networks for laparoscopic workflow analysis
Feb 13, 2017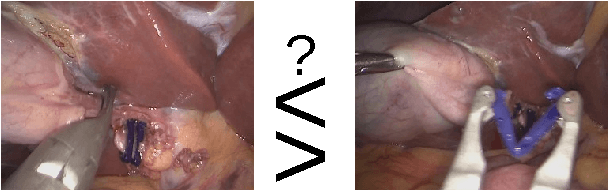

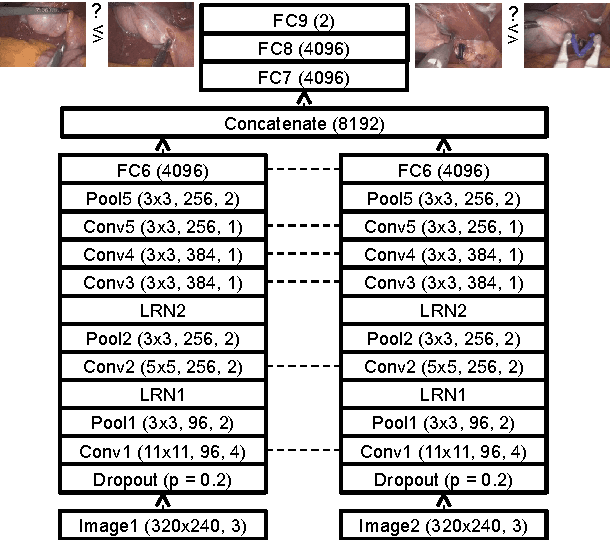
Computer-assisted surgery (CAS) aims to provide the surgeon with the right type of assistance at the right moment. Such assistance systems are especially relevant in laparoscopic surgery, where CAS can alleviate some of the drawbacks that surgeons incur. For many assistance functions, e.g. displaying the location of a tumor at the appropriate time or suggesting what instruments to prepare next, analyzing the surgical workflow is a prerequisite. Since laparoscopic interventions are performed via endoscope, the video signal is an obvious sensor modality to rely on for workflow analysis. Image-based workflow analysis tasks in laparoscopy, such as phase recognition, skill assessment, video indexing or automatic annotation, require a temporal distinction between video frames. Generally computer vision based methods that generalize from previously seen data are used. For training such methods, large amounts of annotated data are necessary. Annotating surgical data requires expert knowledge, therefore collecting a sufficient amount of data is difficult, time-consuming and not always feasible. In this paper, we address this problem by presenting an unsupervised method for training a convolutional neural network (CNN) to differentiate between laparoscopic video frames on a temporal basis. We extract video frames at regular intervals from 324 unlabeled laparoscopic interventions, resulting in a dataset of approximately 2.2 million images. From this dataset, we extract image pairs from the same video and train a CNN to determine their temporal order. To solve this problem, the CNN has to extract features that are relevant for comprehending laparoscopic workflow. Furthermore, we demonstrate that such a CNN can be adapted for surgical workflow segmentation. We performed image-based workflow segmentation on a publicly available dataset of 7 cholecystectomies and 9 colorectal interventions.