 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021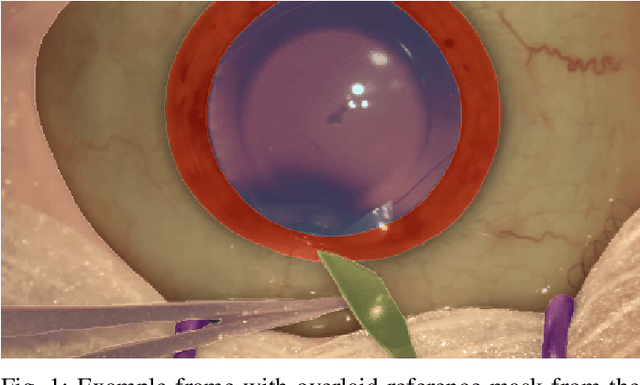
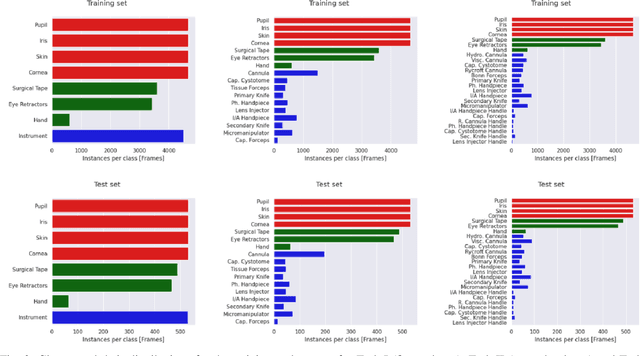
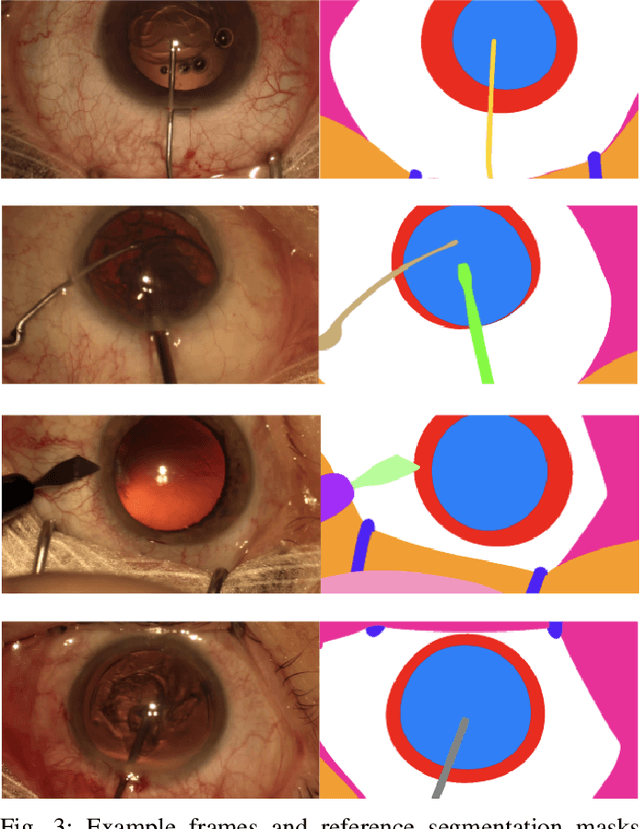
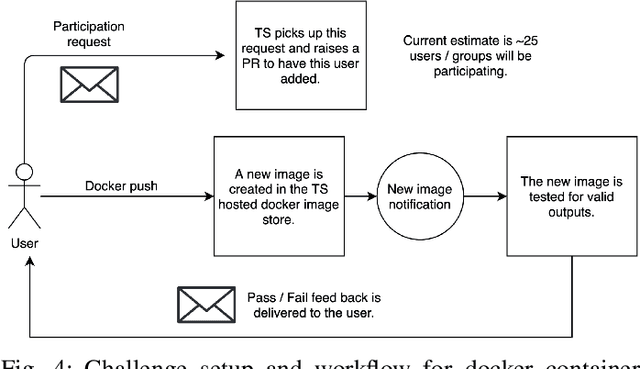
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020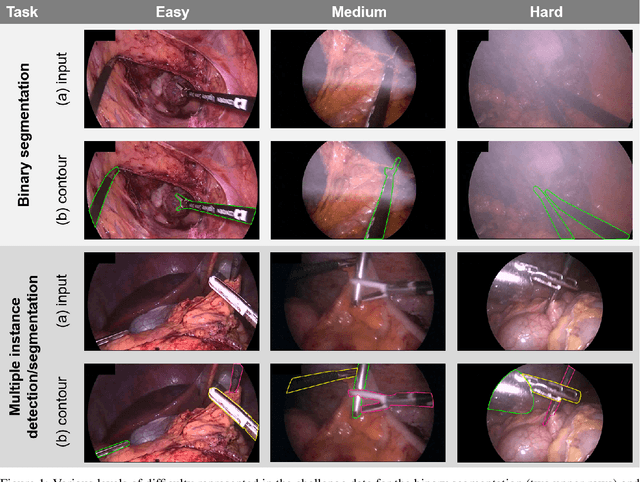
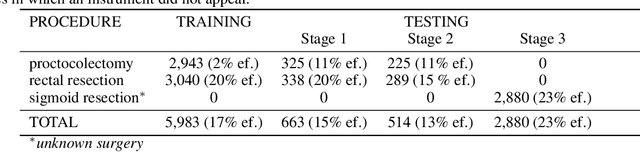
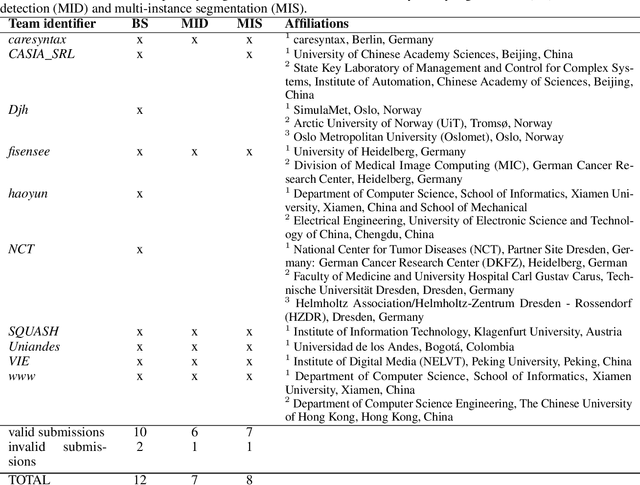
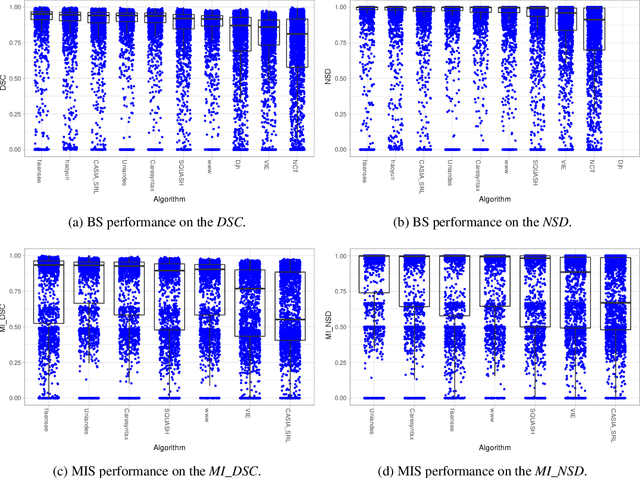
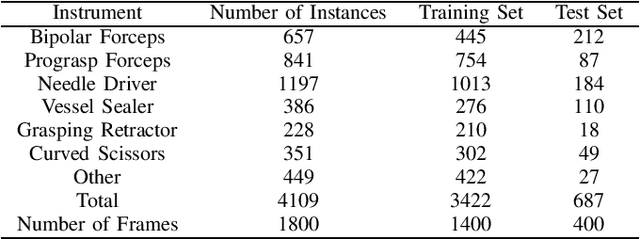
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
BARNet: Bilinear Attention Network with Adaptive Receptive Field for Surgical Instrument Segmentation
Jan 20, 2020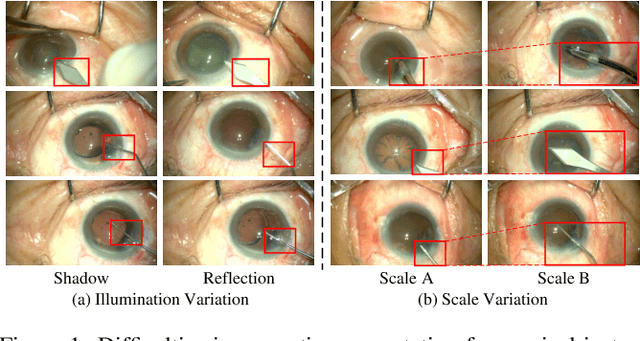
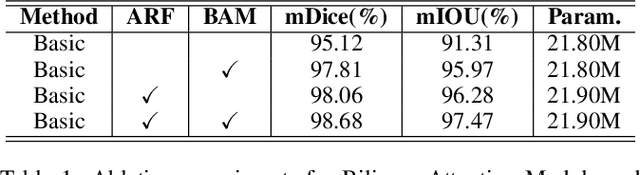
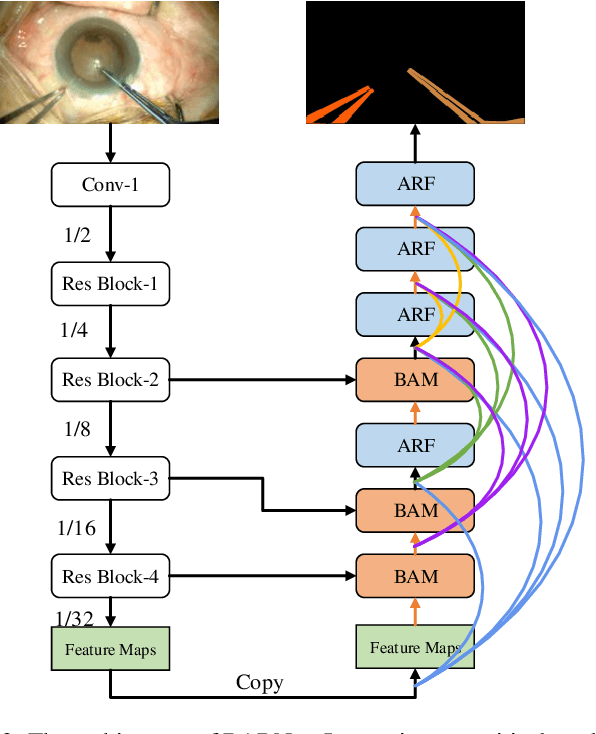
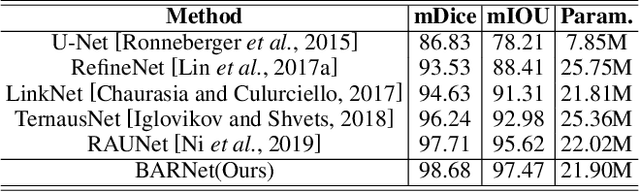
Surgical instrument segmentation is extremely important for computer-assisted surgery. Different from common object segmentation, it is more challenging due to the large illumination and scale variation caused by the special surgical scenes. In this paper, we propose a novel bilinear attention network with adaptive receptive field to solve these two challenges. For the illumination variation, the bilinear attention module can capture second-order statistics to encode global contexts and semantic dependencies between local pixels. With them, semantic features in challenging areas can be inferred from their neighbors and the distinction of various semantics can be boosted. For the scale variation, our adaptive receptive field module aggregates multi-scale features and automatically fuses them with different weights. Specifically, it encodes the semantic relationship between channels to emphasize feature maps with appropriate scales, changing the receptive field of subsequent convolutions. The proposed network achieves the best performance 97.47% mean IOU on Cata7 and comes first place on EndoVis 2017 by 10.10% IOU overtaking second-ranking method.
Attention-Guided Lightweight Network for Real-Time Segmentation of Robotic Surgical Instruments
Oct 24, 2019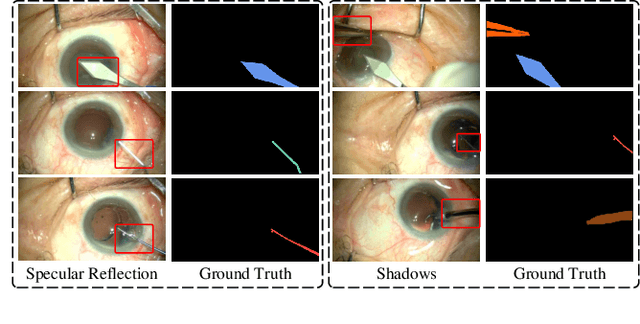
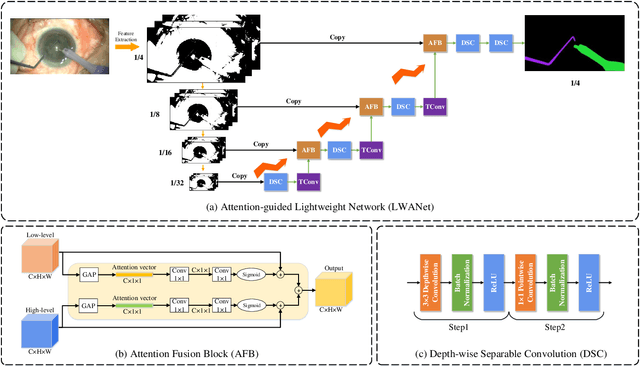
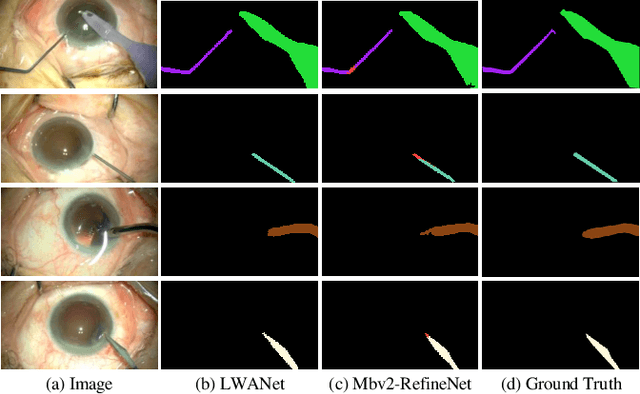
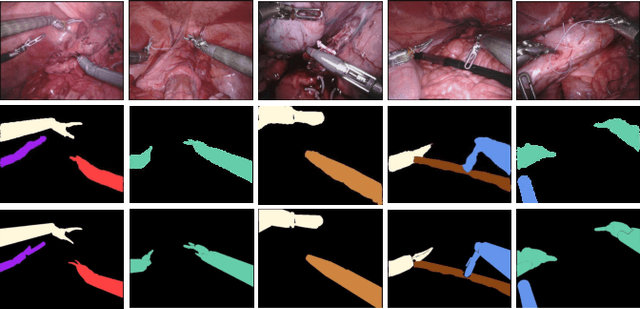
Real-time segmentation of surgical instruments plays a crucial role in robot-assisted surgery. However, real-time segmentation of surgical instruments using current deep learning models is still a challenging task due to the high computational costs and slow inference speed. In this paper, an attention-guided lightweight network (LWANet), is proposed to segment surgical instruments in real-time. LWANet adopts the encoder-decoder architecture, where the encoder is the lightweight network MobileNetV2 and the decoder consists of depth-wise separable convolution, attention fusion block, and transposed convolution. Depth-wise separable convolution is used as the basic unit to construct the decoder, which can reduce the model size and computational costs. Attention fusion block captures global context and encodes semantic dependencies between channels to emphasize target regions, contributing to locating the surgical instrument. Transposed convolution is performed to upsample the feature map for acquiring refined edges. LWANet can segment surgical instruments in real-time, taking few computational costs. Based on 960*544 inputs, its inference speed can reach 39 fps with only 3.39 GFLOPs. Also, it has a small model size and the number of parameters is only 2.06 M. The proposed network is evaluated on two datasets. It achieves state-of-the-art performance 94.10% mean IOU on Cata7 and obtains a new record on EndoVis 2017 with 4.10% increase on mean mIOU.
RAUNet: Residual Attention U-Net for Semantic Segmentation of Cataract Surgical Instruments
Oct 02, 2019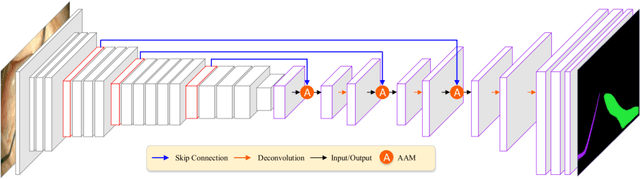
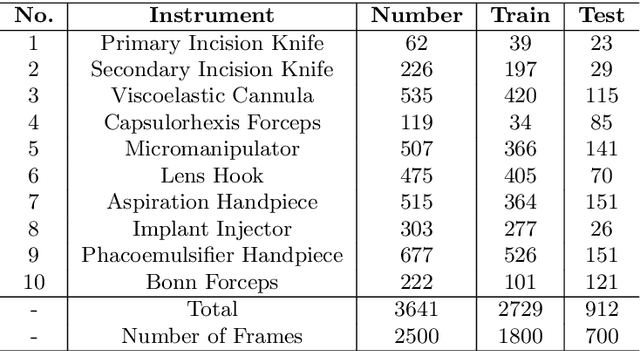
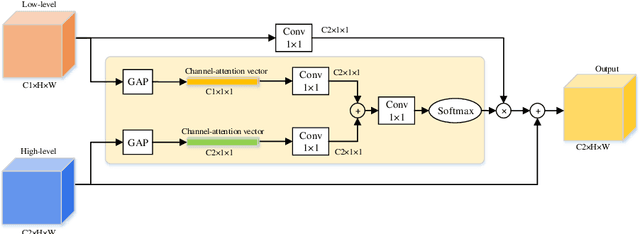
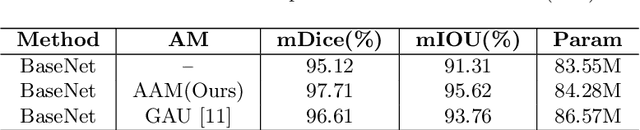
Semantic segmentation of surgical instruments plays a crucial role in robot-assisted surgery. However, accurate segmentation of cataract surgical instruments is still a challenge due to specular reflection and class imbalance issues. In this paper, an attention-guided network is proposed to segment the cataract surgical instrument. A new attention module is designed to learn discriminative features and address the specular reflection issue. It captures global context and encodes semantic dependencies to emphasize key semantic features, boosting the feature representation. This attention module has very few parameters, which helps to save memory. Thus, it can be flexibly plugged into other networks. Besides, a hybrid loss is introduced to train our network for addressing the class imbalance issue, which merges cross entropy and logarithms of Dice loss. A new dataset named Cata7 is constructed to evaluate our network. To the best of our knowledge, this is the first cataract surgical instrument dataset for semantic segmentation. Based on this dataset, RAUNet achieves state-of-the-art performance 97.71% mean Dice and 95.62% mean IOU.
RASNet: Segmentation for Tracking Surgical Instruments in Surgical Videos Using Refined Attention Segmentation Network
May 21, 2019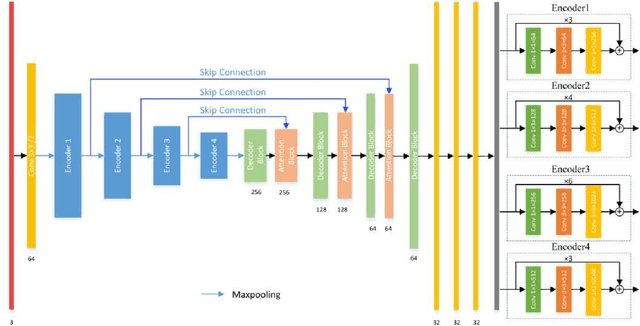
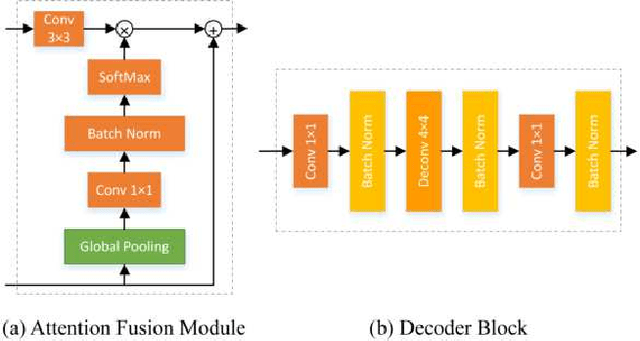
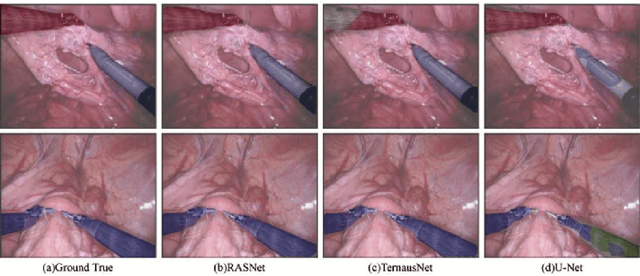
Segmentation for tracking surgical instruments plays an important role in robot-assisted surgery. Segmentation of surgical instruments contributes to capturing accurate spatial information for tracking. In this paper, a novel network, Refined Attention Segmentation Network, is proposed to simultaneously segment surgical instruments and identify their categories. The U-shape network which is popular in segmentation is used. Different from previous work, an attention module is adopted to help the network focus on key regions, which can improve the segmentation accuracy. To solve the class imbalance problem, the weighted sum of the cross entropy loss and the logarithm of the Jaccard index is used as loss function. Furthermore, transfer learning is adopted in our network. The encoder is pre-trained on ImageNet. The dataset from the MICCAI EndoVis Challenge 2017 is used to evaluate our network. Based on this dataset, our network achieves state-of-the-art performance 94.65% mean Dice and 90.33% mean IOU.