 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Mapping of the Best-Suited DNN Pruning Schemes for Real-Time Mobile Acceleration
Nov 22, 2021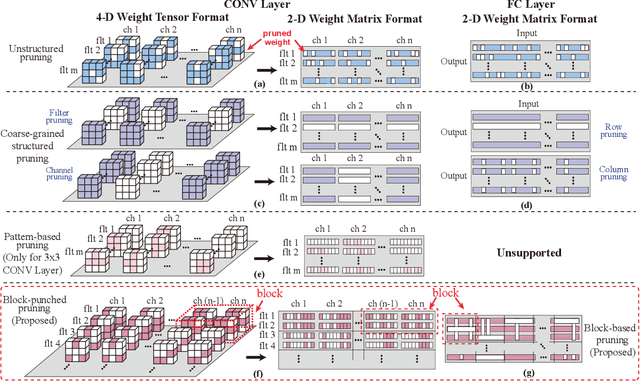

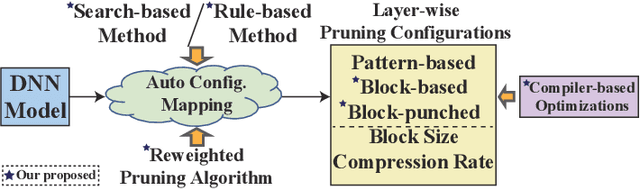
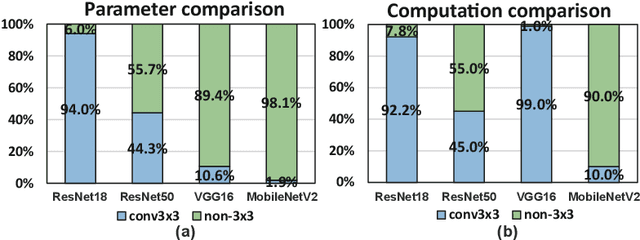
Weight pruning is an effective model compression technique to tackle the challenges of achieving real-time deep neural network (DNN) inference on mobile devices. However, prior pruning schemes have limited application scenarios due to accuracy degradation, difficulty in leveraging hardware acceleration, and/or restriction on certain types of DNN layers. In this paper, we propose a general, fine-grained structured pruning scheme and corresponding compiler optimizations that are applicable to any type of DNN layer while achieving high accuracy and hardware inference performance. With the flexibility of applying different pruning schemes to different layers enabled by our compiler optimizations, we further probe into the new problem of determining the best-suited pruning scheme considering the different acceleration and accuracy performance of various pruning schemes. Two pruning scheme mapping methods, one is search-based and the other is rule-based, are proposed to automatically derive the best-suited pruning regularity and block size for each layer of any given DNN. Experimental results demonstrate that our pruning scheme mapping methods, together with the general fine-grained structured pruning scheme, outperform the state-of-the-art DNN optimization framework with up to 2.48$\times$ and 1.73$\times$ DNN inference acceleration on CIFAR-10 and ImageNet dataset without accuracy loss.
ILMPQ : An Intra-Layer Multi-Precision Deep Neural Network Quantization framework for FPGA
Oct 30, 2021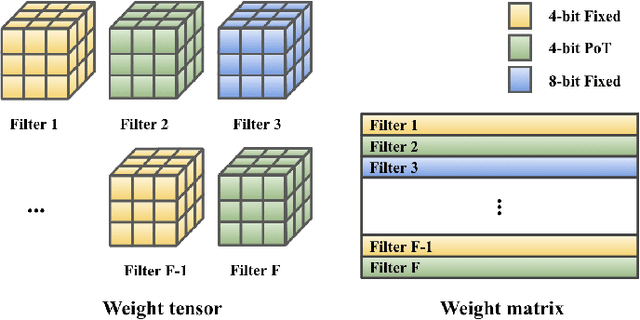
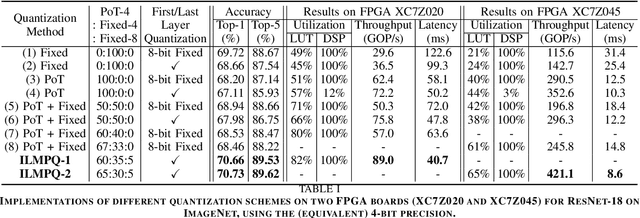
This work targets the commonly used FPGA (field-programmable gate array) devices as the hardware platform for DNN edge computing. We focus on DNN quantization as the main model compression technique. The novelty of this work is: We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach. Our proposed ILMPQ DNN quantization framework achieves 70.73 Top1 accuracy in ResNet-18 on the ImageNet dataset. We also validate the proposed MSP framework on two FPGA devices i.e., Xilinx XC7Z020 and XC7Z045. We achieve 3.65x speedup in end-to-end inference time on the ImageNet, compared with the fixed-point quantization method.
RMSMP: A Novel Deep Neural Network Quantization Framework with Row-wise Mixed Schemes and Multiple Precisions
Oct 30, 2021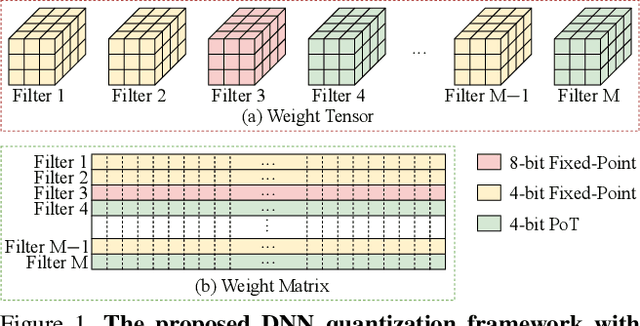
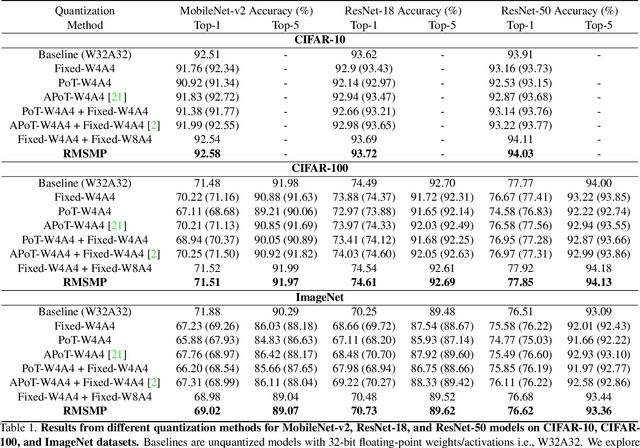
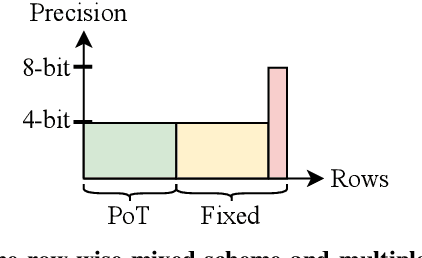
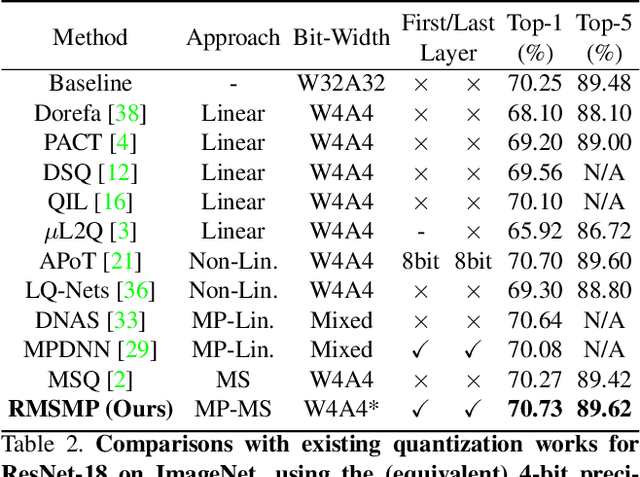
This work proposes a novel Deep Neural Network (DNN) quantization framework, namely RMSMP, with a Row-wise Mixed-Scheme and Multi-Precision approach. Specifically, this is the first effort to assign mixed quantization schemes and multiple precisions within layers -- among rows of the DNN weight matrix, for simplified operations in hardware inference, while preserving accuracy. Furthermore, this paper makes a different observation from the prior work that the quantization error does not necessarily exhibit the layer-wise sensitivity, and actually can be mitigated as long as a certain portion of the weights in every layer are in higher precisions. This observation enables layer-wise uniformality in the hardware implementation towards guaranteed inference acceleration, while still enjoying row-wise flexibility of mixed schemes and multiple precisions to boost accuracy. The candidates of schemes and precisions are derived practically and effectively with a highly hardware-informative strategy to reduce the problem search space. With the offline determined ratio of different quantization schemes and precisions for all the layers, the RMSMP quantization algorithm uses the Hessian and variance-based method to effectively assign schemes and precisions for each row. The proposed RMSMP is tested for the image classification and natural language processing (BERT) applications and achieves the best accuracy performance among state-of-the-arts under the same equivalent precisions. The RMSMP is implemented on FPGA devices, achieving 3.65x speedup in the end-to-end inference time for ResNet-18 on ImageNet, compared with the 4-bit Fixed-point baseline.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021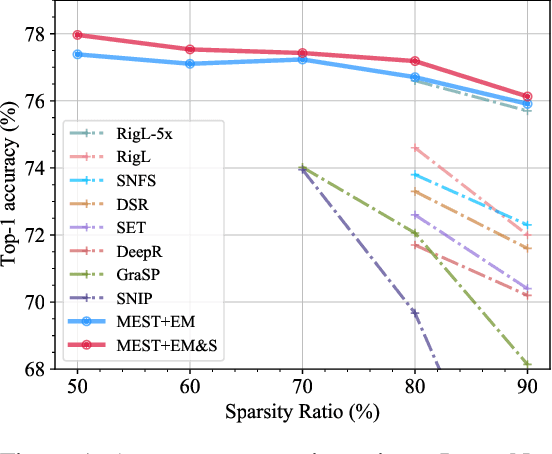
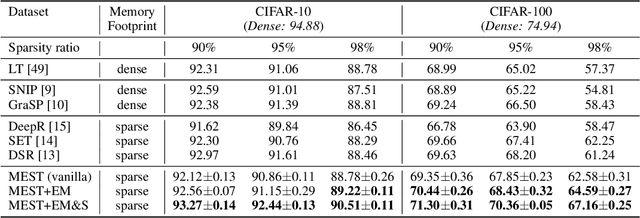
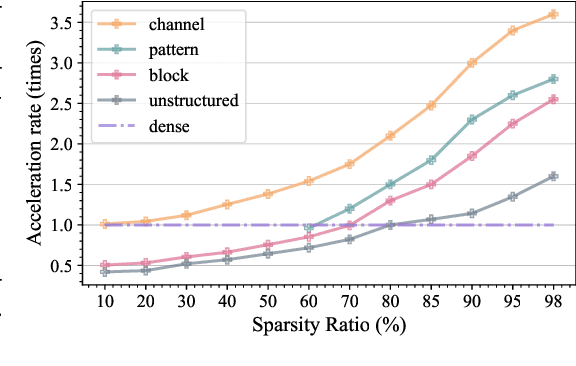
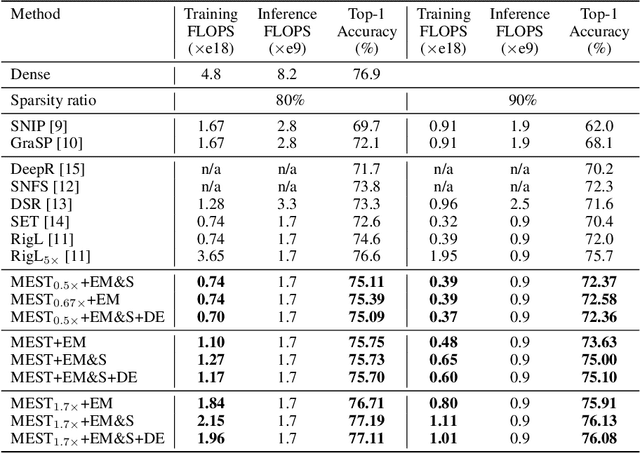
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
GRIM: A General, Real-Time Deep Learning Inference Framework for Mobile Devices based on Fine-Grained Structured Weight Sparsity
Aug 25, 2021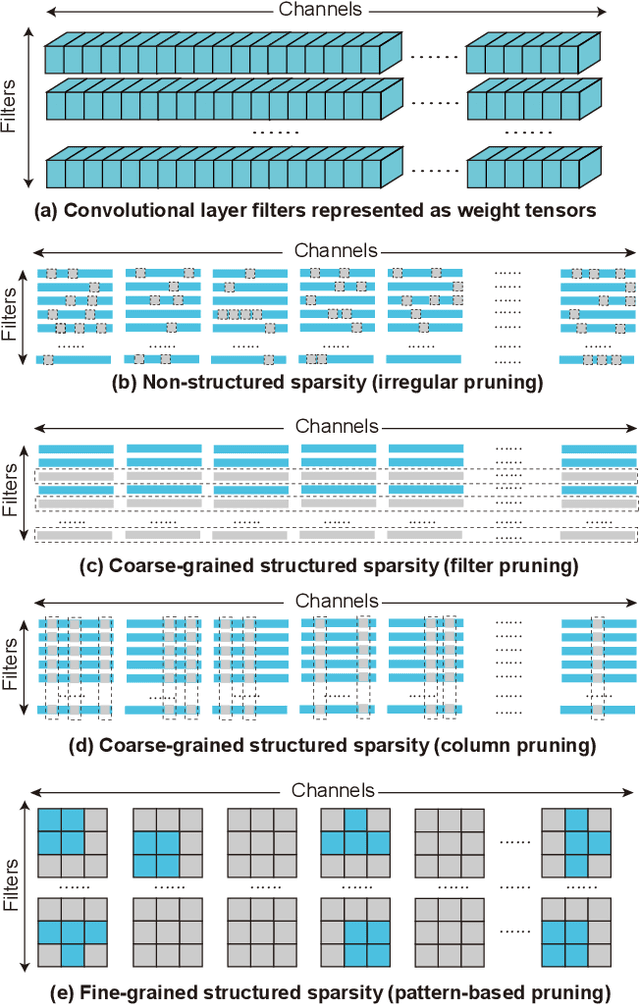
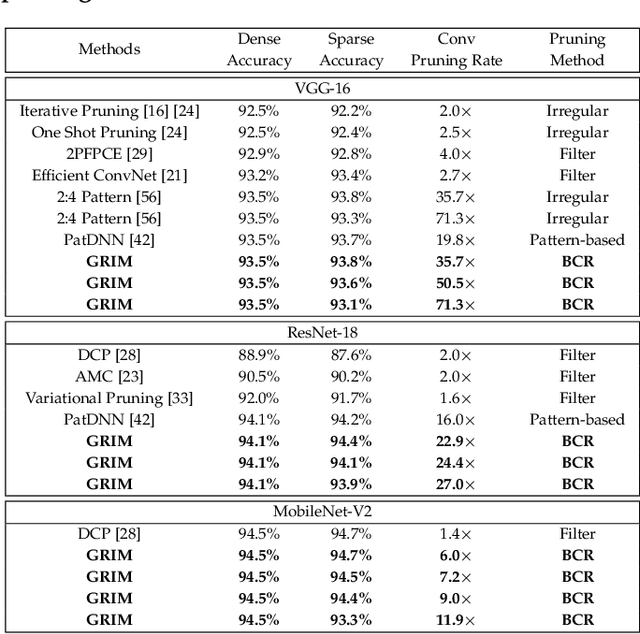
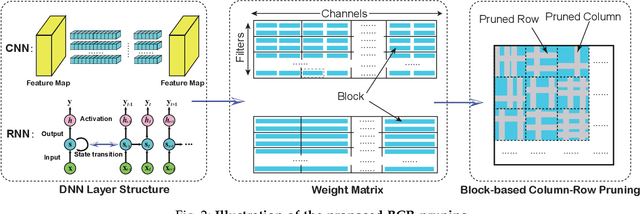
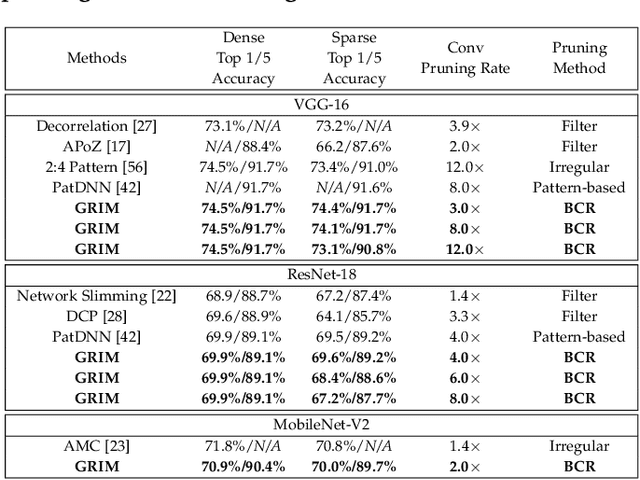
It is appealing but challenging to achieve real-time deep neural network (DNN) inference on mobile devices because even the powerful modern mobile devices are considered as ``resource-constrained'' when executing large-scale DNNs. It necessitates the sparse model inference via weight pruning, i.e., DNN weight sparsity, and it is desirable to design a new DNN weight sparsity scheme that can facilitate real-time inference on mobile devices while preserving a high sparse model accuracy. This paper designs a novel mobile inference acceleration framework GRIM that is General to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) and that achieves Real-time execution and high accuracy, leveraging fine-grained structured sparse model Inference and compiler optimizations for Mobiles. We start by proposing a new fine-grained structured sparsity scheme through the Block-based Column-Row (BCR) pruning. Based on this new fine-grained structured sparsity, our GRIM framework consists of two parts: (a) the compiler optimization and code generation for real-time mobile inference; and (b) the BCR pruning optimizations for determining pruning hyperparameters and performing weight pruning. We compare GRIM with Alibaba MNN, TVM, TensorFlow-Lite, a sparse implementation based on CSR, PatDNN, and ESE (a representative FPGA inference acceleration framework for RNNs), and achieve up to 14.08x speedup.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021
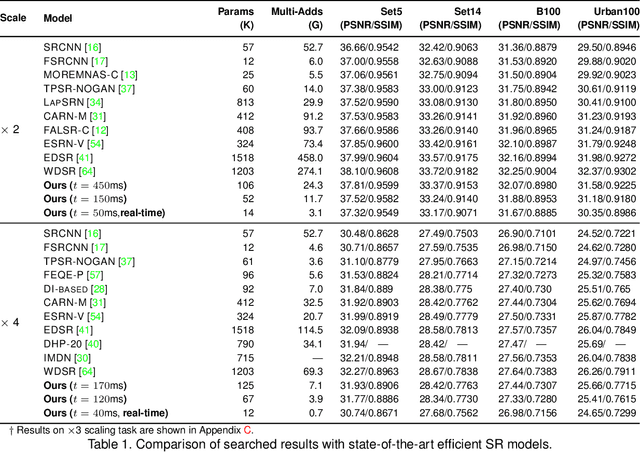
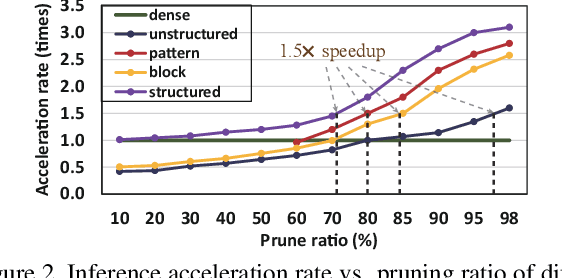
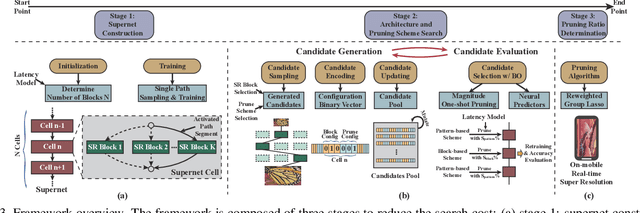
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
Achieving Real-Time Object Detection on MobileDevices with Neural Pruning Search
Jun 28, 2021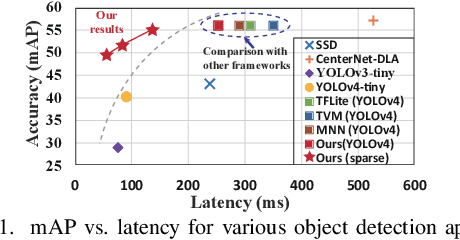
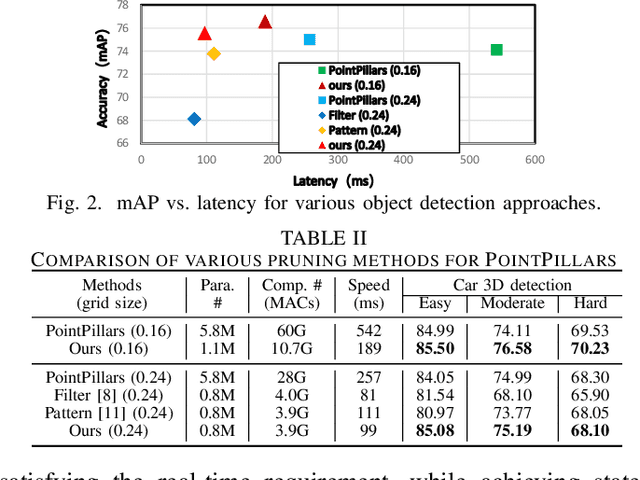
Object detection plays an important role in self-driving cars for security development. However, mobile systems on self-driving cars with limited computation resources lead to difficulties for object detection. To facilitate this, we propose a compiler-aware neural pruning search framework to achieve high-speed inference on autonomous vehicles for 2D and 3D object detection. The framework automatically searches the pruning scheme and rate for each layer to find a best-suited pruning for optimizing detection accuracy and speed performance under compiler optimization. Our experiments demonstrate that for the first time, the proposed method achieves (close-to) real-time, 55ms and 99ms inference times for YOLOv4 based 2D object detection and PointPillars based 3D detection, respectively, on an off-the-shelf mobile phone with minor (or no) accuracy loss.
High-Robustness, Low-Transferability Fingerprinting of Neural Networks
May 14, 2021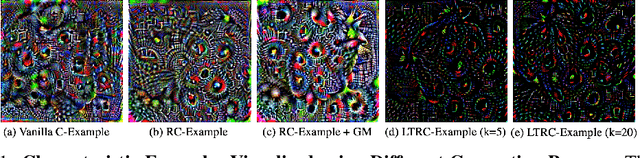
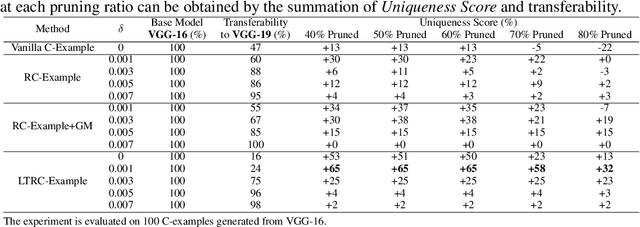
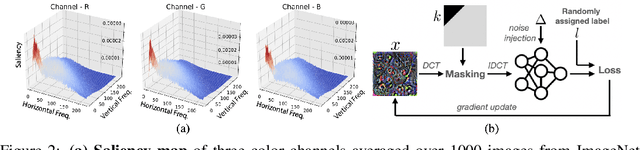
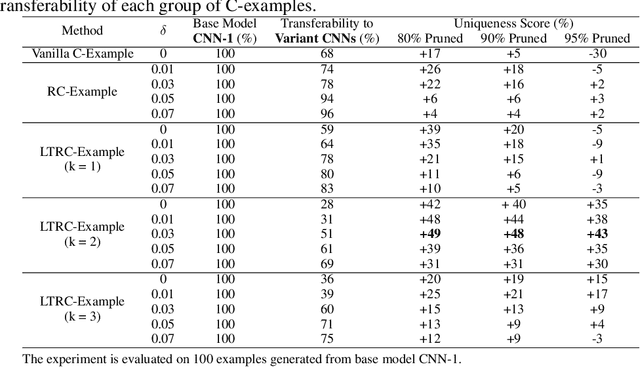
This paper proposes Characteristic Examples for effectively fingerprinting deep neural networks, featuring high-robustness to the base model against model pruning as well as low-transferability to unassociated models. This is the first work taking both robustness and transferability into consideration for generating realistic fingerprints, whereas current methods lack practical assumptions and may incur large false positive rates. To achieve better trade-off between robustness and transferability, we propose three kinds of characteristic examples: vanilla C-examples, RC-examples, and LTRC-example, to derive fingerprints from the original base model. To fairly characterize the trade-off between robustness and transferability, we propose Uniqueness Score, a comprehensive metric that measures the difference between robustness and transferability, which also serves as an indicator to the false alarm problem.
Mixture of Robust Experts : A Flexible Defense Against Multiple Perturbations
Apr 21, 2021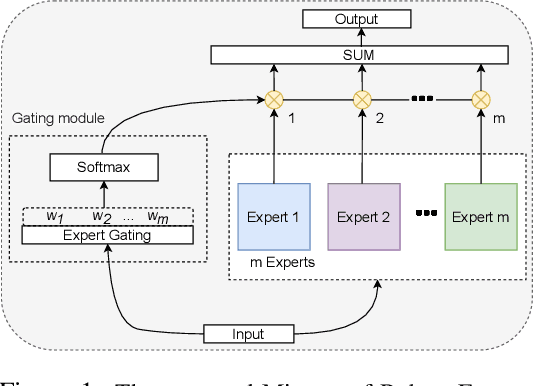
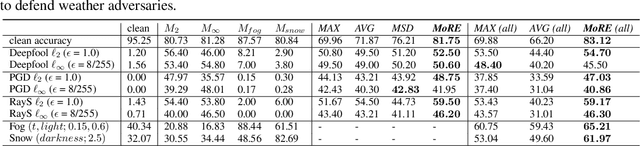
To tackle the susceptibility of deep neural networks to adversarial examples, the adversarial training has been proposed which provides a notion of security through an inner maximization problem presenting the first-order adversaries embedded within the outer minimization of the training loss. To generalize the adversarial robustness over different perturbation types, the adversarial training method has been augmented with the improved inner maximization presenting a union of multiple perturbations e.g., various $\ell_p$ norm-bounded perturbations. However, the improved inner maximization only enjoys limited flexibility in terms of the allowable perturbation types. In this work, through a gating mechanism, we assemble a set of expert networks, each one either adversarially trained to deal with a particular perturbation type or normally trained for boosting accuracy on clean data. The gating module assigns weights dynamically to each expert to achieve superior accuracy under various data types e.g., adversarial examples, adverse weather perturbations, and clean input. In order to deal with the obfuscated gradients issue, the training of the gating module is conducted together with fine-tuning of the last fully connected layers of expert networks through adversarial training approach. Using extensive experiments, we show that our Mixture of Robust Experts (MoRE) approach enables flexible integration of a broad range of robust experts with superior performance.
Beta-CROWN: Efficient Bound Propagation with Per-neuron Split Constraints for Complete and Incomplete Neural Network Verification
Mar 11, 2021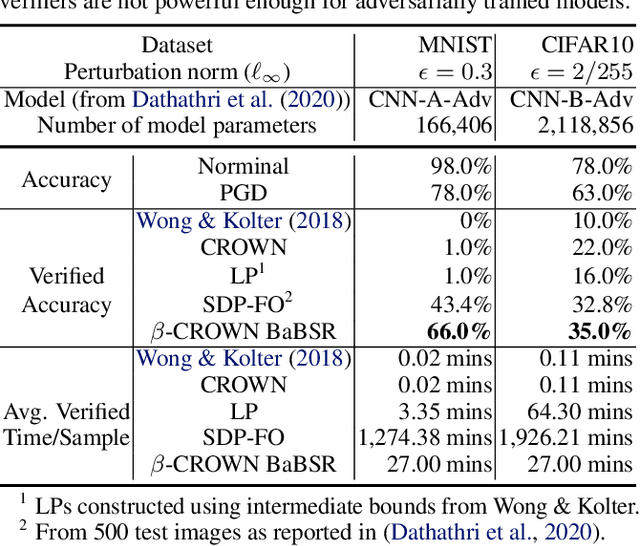
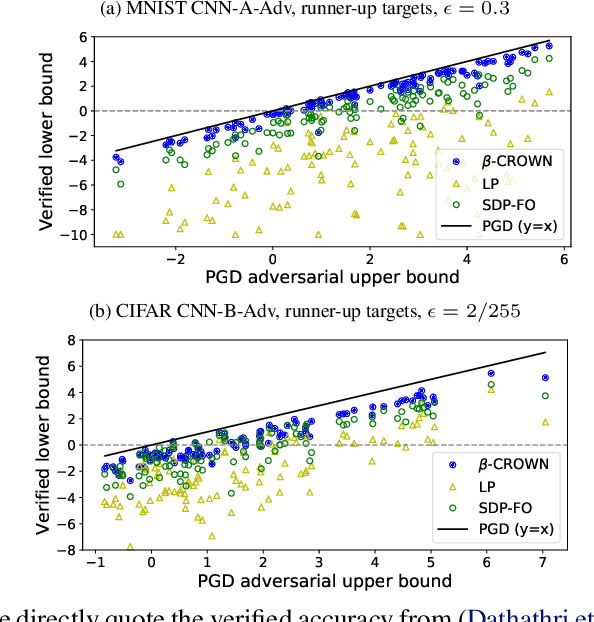
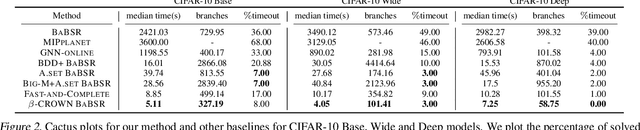
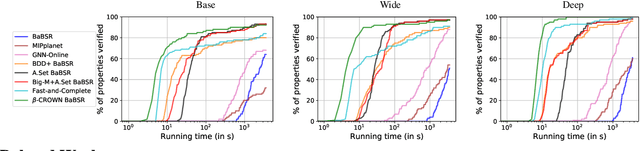
Recent works in neural network verification show that cheap incomplete verifiers such as CROWN, based upon bound propagations, can effectively be used in Branch-and-Bound (BaB) methods to accelerate complete verification, achieving significant speedups compared to expensive linear programming (LP) based techniques. However, they cannot fully handle the per-neuron split constraints introduced by BaB like LP verifiers do, leading to looser bounds and hurting their verification efficiency. In this work, we develop $\beta$-CROWN, a new bound propagation based method that can fully encode per-neuron splits via optimizable parameters $\beta$. When the optimizable parameters are jointly optimized in intermediate layers, $\beta$-CROWN has the potential of producing better bounds than typical LP verifiers with neuron split constraints, while being efficiently parallelizable on GPUs. Applied to the complete verification setting, $\beta$-CROWN is close to three orders of magnitude faster than LP-based BaB methods for robustness verification, and also over twice faster than state-of-the-art GPU-based complete verifiers with similar timeout rates. By terminating BaB early, our method can also be used for incomplete verification. Compared to the state-of-the-art semidefinite-programming (SDP) based verifier, we show a substantial leap forward by greatly reducing the gap between verified accuracy and empirical adversarial attack accuracy, from 35% (SDP) to 12% on an adversarially trained MNIST network ($\epsilon=0.3$), while being 47 times faster. Our code is available at https://github.com/KaidiXu/Beta-CROWN