 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACMA: Language-Aligning Contrastive Learning with Meta-Actions for Embodied Instruction Following
Oct 18, 2023



End-to-end Transformers have demonstrated an impressive success rate for Embodied Instruction Following when the environment has been seen in training. However, they tend to struggle when deployed in an unseen environment. This lack of generalizability is due to the agent's insensitivity to subtle changes in natural language instructions. To mitigate this issue, we propose explicitly aligning the agent's hidden states with the instructions via contrastive learning. Nevertheless, the semantic gap between high-level language instructions and the agent's low-level action space remains an obstacle. Therefore, we further introduce a novel concept of meta-actions to bridge the gap. Meta-actions are ubiquitous action patterns that can be parsed from the original action sequence. These patterns represent higher-level semantics that are intuitively aligned closer to the instructions. When meta-actions are applied as additional training signals, the agent generalizes better to unseen environments. Compared to a strong multi-modal Transformer baseline, we achieve a significant 4.5% absolute gain in success rate in unseen environments of ALFRED Embodied Instruction Following. Additional analysis shows that the contrastive objective and meta-actions are complementary in achieving the best results, and the resulting agent better aligns its states with corresponding instructions, making it more suitable for real-world embodied agents. The code is available at: https://github.com/joeyy5588/LACMA.
Image is First-order Norm+Linear Autoregressive
May 25, 2023This paper reveals that every image can be understood as a first-order norm+linear autoregressive process, referred to as FINOLA, where norm+linear denotes the use of normalization before the linear model. We demonstrate that images of size 256$\times$256 can be reconstructed from a compressed vector using autoregression up to a 16$\times$16 feature map, followed by upsampling and convolution. This discovery sheds light on the underlying partial differential equations (PDEs) governing the latent feature space. Additionally, we investigate the application of FINOLA for self-supervised learning through a simple masked prediction technique. By encoding a single unmasked quadrant block, we can autoregressively predict the surrounding masked region. Remarkably, this pre-trained representation proves effective for image classification and object detection tasks, even in lightweight networks, without requiring fine-tuning. The code will be made publicly available.
ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System
Apr 29, 2023



Existing deep video models are limited by specific tasks, fixed input-output spaces, and poor generalization capabilities, making it difficult to deploy them in real-world scenarios. In this paper, we present our vision for multimodal and versatile video understanding and propose a prototype system, \system. Our system is built upon a tracklet-centric paradigm, which treats tracklets as the basic video unit and employs various Video Foundation Models (ViFMs) to annotate their properties e.g., appearance, motion, \etc. All the detected tracklets are stored in a database and interact with the user through a database manager. We have conducted extensive case studies on different types of in-the-wild videos, which demonstrates the effectiveness of our method in answering various video-related problems. Our project is available at https://www.wangjunke.info/ChatVideo/
OmniTracker: Unifying Object Tracking by Tracking-with-Detection
Mar 21, 2023Object tracking (OT) aims to estimate the positions of target objects in a video sequence. Depending on whether the initial states of target objects are specified by provided annotations in the first frame or the categories, OT could be classified as instance tracking (e.g., SOT and VOS) and category tracking (e.g., MOT, MOTS, and VIS) tasks. Combing the advantages of the best practices developed in both communities, we propose a novel tracking-with-detection paradigm, where tracking supplements appearance priors for detection and detection provides tracking with candidate bounding boxes for association. Equipped with such a design, a unified tracking model, OmniTracker, is further presented to resolve all the tracking tasks with a fully shared network architecture, model weights, and inference pipeline. Extensive experiments on 7 tracking datasets, including LaSOT, TrackingNet, DAVIS16-17, MOT17, MOTS20, and YTVIS19, demonstrate that OmniTracker achieves on-par or even better results than both task-specific and unified tracking models.
Layer Grafted Pre-training: Bridging Contrastive Learning And Masked Image Modeling For Label-Efficient Representations
Feb 27, 2023



Recently, both Contrastive Learning (CL) and Mask Image Modeling (MIM) demonstrate that self-supervision is powerful to learn good representations. However, naively combining them is far from success. In this paper, we start by making the empirical observation that a naive joint optimization of CL and MIM losses leads to conflicting gradient directions - more severe as the layers go deeper. This motivates us to shift the paradigm from combining loss at the end, to choosing the proper learning method per network layer. Inspired by experimental observations, we find that MIM and CL are suitable to lower and higher layers, respectively. We hence propose to combine them in a surprisingly simple, "sequential cascade" fashion: early layers are first trained under one MIM loss, on top of which latter layers continue to be trained under another CL loss. The proposed Layer Grafted Pre-training learns good visual representations that demonstrate superior label efficiency in downstream applications, in particular yielding strong few-shot performance besides linear evaluation. For instance, on ImageNet-1k, Layer Grafted Pre-training yields 65.5% Top-1 accuracy in terms of 1% few-shot learning with ViT-B/16, which improves MIM and CL baselines by 14.4% and 2.1% with no bells and whistles. The code is available at https://github.com/VITA-Group/layerGraftedPretraining_ICLR23.git.
Generalized Decoding for Pixel, Image, and Language
Dec 21, 2022



We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.
Look Before You Match: Instance Understanding Matters in Video Object Segmentation
Dec 13, 2022



Exploring dense matching between the current frame and past frames for long-range context modeling, memory-based methods have demonstrated impressive results in video object segmentation (VOS) recently. Nevertheless, due to the lack of instance understanding ability, the above approaches are oftentimes brittle to large appearance variations or viewpoint changes resulted from the movement of objects and cameras. In this paper, we argue that instance understanding matters in VOS, and integrating it with memory-based matching can enjoy the synergy, which is intuitively sensible from the definition of VOS task, \ie, identifying and segmenting object instances within the video. Towards this goal, we present a two-branch network for VOS, where the query-based instance segmentation (IS) branch delves into the instance details of the current frame and the VOS branch performs spatial-temporal matching with the memory bank. We employ the well-learned object queries from IS branch to inject instance-specific information into the query key, with which the instance-augmented matching is further performed. In addition, we introduce a multi-path fusion block to effectively combine the memory readout with multi-scale features from the instance segmentation decoder, which incorporates high-resolution instance-aware features to produce final segmentation results. Our method achieves state-of-the-art performance on DAVIS 2016/2017 val (92.6% and 87.1%), DAVIS 2017 test-dev (82.8%), and YouTube-VOS 2018/2019 val (86.3% and 86.3%), outperforming alternative methods by clear margins.
Masked Video Distillation: Rethinking Masked Feature Modeling for Self-supervised Video Representation Learning
Dec 08, 2022Benefiting from masked visual modeling, self-supervised video representation learning has achieved remarkable progress. However, existing methods focus on learning representations from scratch through reconstructing low-level features like raw pixel RGB values. In this paper, we propose masked video distillation (MVD), a simple yet effective two-stage masked feature modeling framework for video representation learning: firstly we pretrain an image (or video) model by recovering low-level features of masked patches, then we use the resulting features as targets for masked feature modeling. For the choice of teacher models, we observe that students taught by video teachers perform better on temporally-heavy video tasks, while image teachers transfer stronger spatial representations for spatially-heavy video tasks. Visualization analysis also indicates different teachers produce different learned patterns for students. Motivated by this observation, to leverage the advantage of different teachers, we design a spatial-temporal co-teaching method for MVD. Specifically, we distill student models from both video teachers and image teachers by masked feature modeling. Extensive experimental results demonstrate that video transformers pretrained with spatial-temporal co-teaching outperform models distilled with a single teacher on a multitude of video datasets. Our MVD with vanilla ViT achieves state-of-the-art performance compared with previous supervised or self-supervised methods on several challenging video downstream tasks. For example, with the ViT-Large model, our MVD achieves 86.4% and 75.9% Top-1 accuracy on Kinetics-400 and Something-Something-v2, outperforming VideoMAE by 1.2% and 1.6% respectively. Code will be available at \url{https://github.com/ruiwang2021/mvd}.
Self-Supervised Learning based on Heat Equation
Nov 23, 2022This paper presents a new perspective of self-supervised learning based on extending heat equation into high dimensional feature space. In particular, we remove time dependence by steady-state condition, and extend the remaining 2D Laplacian from x--y isotropic to linear correlated. Furthermore, we simplify it by splitting x and y axes as two first-order linear differential equations. Such simplification explicitly models the spatial invariance along horizontal and vertical directions separately, supporting prediction across image blocks. This introduces a very simple masked image modeling (MIM) method, named QB-Heat. QB-Heat leaves a single block with size of quarter image unmasked and extrapolates other three masked quarters linearly. It brings MIM to CNNs without bells and whistles, and even works well for pre-training light-weight networks that are suitable for both image classification and object detection without fine-tuning. Compared with MoCo-v2 on pre-training a Mobile-Former with 5.8M parameters and 285M FLOPs, QB-Heat is on par in linear probing on ImageNet, but clearly outperforms in non-linear probing that adds a transformer block before linear classifier (65.6% vs. 52.9%). When transferring to object detection with frozen backbone, QB-Heat outperforms MoCo-v2 and supervised pre-training on ImageNet by 7.9 and 4.5 AP respectively. This work provides an insightful hypothesis on the invariance within visual representation over different shapes and textures: the linear relationship between horizontal and vertical derivatives. The code will be publicly released.
Video Mobile-Former: Video Recognition with Efficient Global Spatial-temporal Modeling
Aug 25, 2022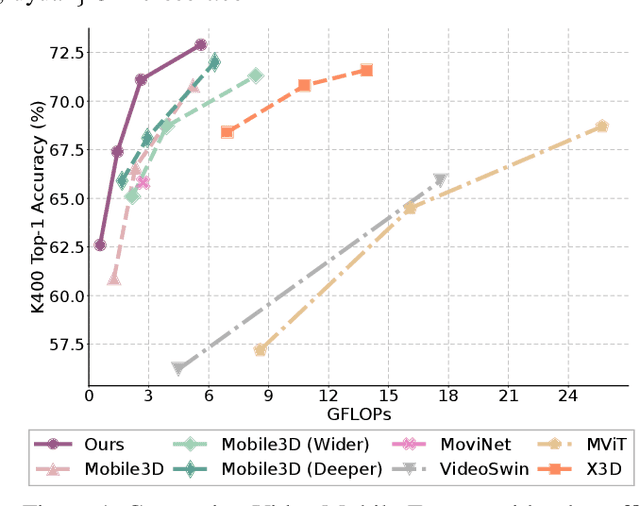
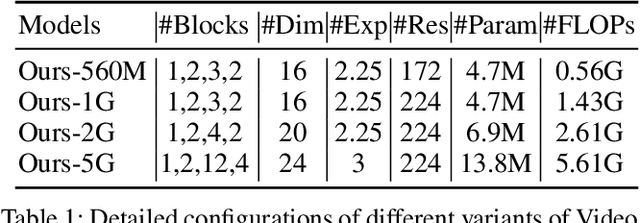
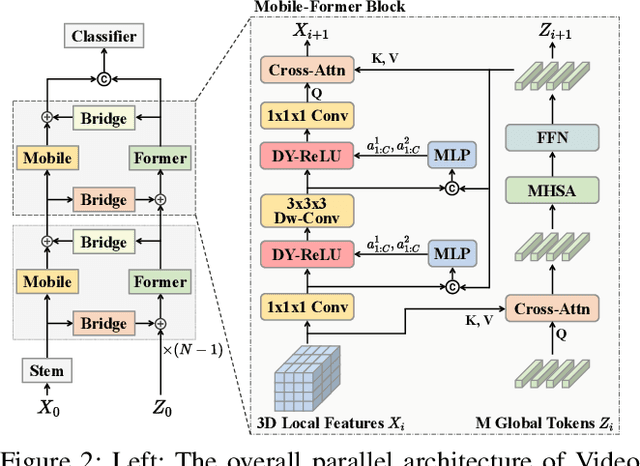
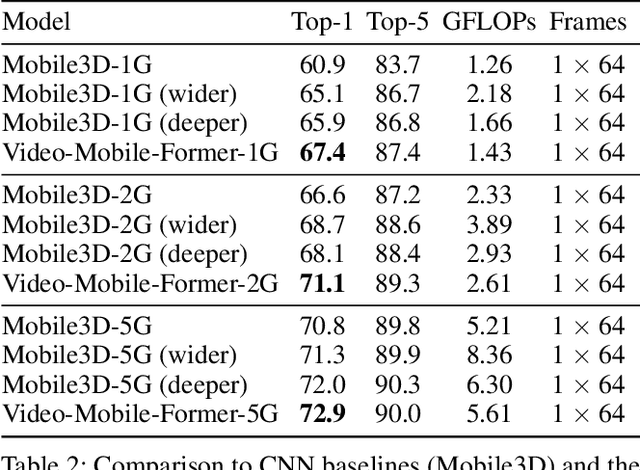
Transformer-based models have achieved top performance on major video recognition benchmarks. Benefiting from the self-attention mechanism, these models show stronger ability of modeling long-range dependencies compared to CNN-based models. However, significant computation overheads, resulted from the quadratic complexity of self-attention on top of a tremendous number of tokens, limit the use of existing video transformers in applications with limited resources like mobile devices. In this paper, we extend Mobile-Former to Video Mobile-Former, which decouples the video architecture into a lightweight 3D-CNNs for local context modeling and a Transformer modules for global interaction modeling in a parallel fashion. To avoid significant computational cost incurred by computing self-attention between the large number of local patches in videos, we propose to use very few global tokens (e.g., 6) for a whole video in Transformers to exchange information with 3D-CNNs with a cross-attention mechanism. Through efficient global spatial-temporal modeling, Video Mobile-Former significantly improves the video recognition performance of alternative lightweight baselines, and outperforms other efficient CNN-based models at the low FLOP regime from 500M to 6G total FLOPs on various video recognition tasks. It is worth noting that Video Mobile-Former is the first Transformer-based video model which constrains the computational budget within 1G FLOPs.