 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Spherical Transformer for Efficient Molecular Modeling
May 29, 2025



SE(3)-equivariant Graph Neural Networks (GNNs) have significantly advanced molecular system modeling by employing group representations. However, their message passing processes, which rely on tensor product-based convolutions, are limited by insufficient non-linearity and incomplete group representations, thereby restricting expressiveness. To overcome these limitations, we introduce the Equivariant Spherical Transformer (EST), a novel framework that leverages a Transformer structure within the spatial domain of group representations after Fourier transform. We theoretically and empirically demonstrate that EST can encompass the function space of tensor products while achieving superior expressiveness. Furthermore, EST's equivariant inductive bias is guaranteed through a uniform sampling strategy for the Fourier transform. Our experiments demonstrate state-of-the-art performance by EST on various molecular benchmarks, including OC20 and QM9.
Scalable Oversight for Superhuman AI via Recursive Self-Critiquing
Feb 07, 2025As AI capabilities increasingly surpass human proficiency in complex tasks, current alignment techniques including SFT and RLHF face fundamental challenges in ensuring reliable oversight. These methods rely on direct human assessment and become untenable when AI outputs exceed human cognitive thresholds. In response to this challenge, we explore two hypotheses: (1) critique of critique can be easier than critique itself, extending the widely-accepted observation that verification is easier than generation to the critique domain, as critique itself is a specialized form of generation; (2) this difficulty relationship is recursively held, suggesting that when direct evaluation is infeasible, performing high-order critiques (e.g., critique of critique of critique) offers a more tractable supervision pathway. To examine these hypotheses, we perform Human-Human, Human-AI, and AI-AI experiments across multiple tasks. Our results demonstrate encouraging evidence supporting these hypotheses and suggest that recursive self-critiquing is a promising direction for scalable oversight.
Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
Nov 18, 2024



The evolution of machine learning has increasingly prioritized the development of powerful models and more scalable supervision signals. However, the emergence of foundation models presents significant challenges in providing effective supervision signals necessary for further enhancing their capabilities. Consequently, there is an urgent need to explore novel supervision signals and technical approaches. In this paper, we propose verifier engineering, a novel post-training paradigm specifically designed for the era of foundation models. The core of verifier engineering involves leveraging a suite of automated verifiers to perform verification tasks and deliver meaningful feedback to foundation models. We systematically categorize the verifier engineering process into three essential stages: search, verify, and feedback, and provide a comprehensive review of state-of-the-art research developments within each stage. We believe that verifier engineering constitutes a fundamental pathway toward achieving Artificial General Intelligence.
Transferable Post-training via Inverse Value Learning
Oct 28, 2024



As post-training processes utilize increasingly large datasets and base models continue to grow in size, the computational demands and implementation challenges of existing algorithms are escalating significantly. In this paper, we propose modeling the changes at the logits level during post-training using a separate neural network (i.e., the value network). After training this network on a small base model using demonstrations, this network can be seamlessly integrated with other pre-trained models during inference, enables them to achieve similar capability enhancements. We systematically investigate the best practices for this paradigm in terms of pre-training weights and connection schemes. We demonstrate that the resulting value network has broad transferability across pre-trained models of different parameter sizes within the same family, models undergoing continuous pre-training within the same family, and models with different vocabularies across families. In certain cases, it can achieve performance comparable to full-parameter fine-tuning. Furthermore, we explore methods to enhance the transferability of the value model and prevent overfitting to the base model used during training.
Rethinking Reward Model Evaluation: Are We Barking up the Wrong Tree?
Oct 08, 2024



Reward Models (RMs) are crucial for aligning language models with human preferences. Currently, the evaluation of RMs depends on measuring accuracy against a validation set of manually annotated preference data. Although this method is straightforward and widely adopted, the relationship between RM accuracy and downstream policy performance remains under-explored. In this work, we conduct experiments in a synthetic setting to investigate how differences in RM measured by accuracy translate into gaps in optimized policy performance. Our findings reveal that while there is a weak positive correlation between accuracy and downstream performance, policies optimized towards RMs with similar accuracy can exhibit quite different performance. Moreover, we discover that the way of measuring accuracy significantly impacts its ability to predict the final policy performance. Through the lens of Regressional Goodhart's effect, we identify the existence of exogenous variables impacting the relationship between RM quality measured by accuracy and policy model capability. This underscores the inadequacy of relying solely on accuracy to reflect their impact on policy optimization.
On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation
Jun 18, 2024



Hallucination occurs when large language models (LLMs) exhibit behavior that deviates from the boundaries of their knowledge during the response generation process. Previous learning-based methods focus on detecting knowledge boundaries and finetuning models with instance-level feedback, but they suffer from inaccurate signals due to off-policy data sampling and coarse-grained feedback. In this paper, we introduce \textit{\b{R}einforcement \b{L}earning \b{f}or \b{H}allucination} (RLFH), a fine-grained feedback-based online reinforcement learning method for hallucination mitigation. Unlike previous learning-based methods, RLFH enables LLMs to explore the boundaries of their internal knowledge and provide on-policy, fine-grained feedback on these explorations. To construct fine-grained feedback for learning reliable generation behavior, RLFH decomposes the outcomes of large models into atomic facts, provides statement-level evaluation signals, and traces back the signals to the tokens of the original responses. Finally, RLFH adopts the online reinforcement algorithm with these token-level rewards to adjust model behavior for hallucination mitigation. For effective on-policy optimization, RLFH also introduces an LLM-based fact assessment framework to verify the truthfulness and helpfulness of atomic facts without human intervention. Experiments on HotpotQA, SQuADv2, and Biography benchmarks demonstrate that RLFH can balance their usage of internal knowledge during the generation process to eliminate the hallucination behavior of LLMs.
Towards Scalable Automated Alignment of LLMs: A Survey
Jun 03, 2024Alignment is the most critical step in building large language models (LLMs) that meet human needs. With the rapid development of LLMs gradually surpassing human capabilities, traditional alignment methods based on human-annotation are increasingly unable to meet the scalability demands. Therefore, there is an urgent need to explore new sources of automated alignment signals and technical approaches. In this paper, we systematically review the recently emerging methods of automated alignment, attempting to explore how to achieve effective, scalable, automated alignment once the capabilities of LLMs exceed those of humans. Specifically, we categorize existing automated alignment methods into 4 major categories based on the sources of alignment signals and discuss the current status and potential development of each category. Additionally, we explore the underlying mechanisms that enable automated alignment and discuss the essential factors that make automated alignment technologies feasible and effective from the fundamental role of alignment.
SoFA: Shielded On-the-fly Alignment via Priority Rule Following
Feb 27, 2024



The alignment problem in Large Language Models (LLMs) involves adapting them to the broad spectrum of human values. This requirement challenges existing alignment methods due to diversity of preferences and regulatory standards. This paper introduces a novel alignment paradigm, priority rule following, which defines rules as the primary control mechanism in each dialog, prioritizing them over user instructions. Our preliminary analysis reveals that even the advanced LLMs, such as GPT-4, exhibit shortcomings in understanding and prioritizing the rules. Therefore, we present PriorityDistill, a semi-automated approach for distilling priority following signals from LLM simulations to ensure robust rule integration and adherence. Our experiments show that this method not only effectively minimizes misalignments utilizing only one general rule but also adapts smoothly to various unseen rules, ensuring they are shielded from hijacking and that the model responds appropriately.
Principled and Efficient Transfer Learning of Deep Models via Neural Collapse
Jan 04, 2023With the ever-growing model size and the limited availability of labeled training data, transfer learning has become an increasingly popular approach in many science and engineering domains. For classification problems, this work delves into the mystery of transfer learning through an intriguing phenomenon termed neural collapse (NC), where the last-layer features and classifiers of learned deep networks satisfy: (i) the within-class variability of the features collapses to zero, and (ii) the between-class feature means are maximally and equally separated. Through the lens of NC, our findings for transfer learning are the following: (i) when pre-training models, preventing intra-class variability collapse (to a certain extent) better preserves the intrinsic structures of the input data, so that it leads to better model transferability; (ii) when fine-tuning models on downstream tasks, obtaining features with more NC on downstream data results in better test accuracy on the given task. The above results not only demystify many widely used heuristics in model pre-training (e.g., data augmentation, projection head, self-supervised learning), but also leads to more efficient and principled fine-tuning method on downstream tasks that we demonstrate through extensive experimental results.
GraphCoCo: Graph Complementary Contrastive Learning
Mar 24, 2022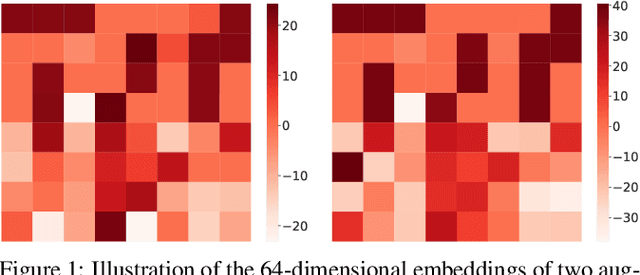
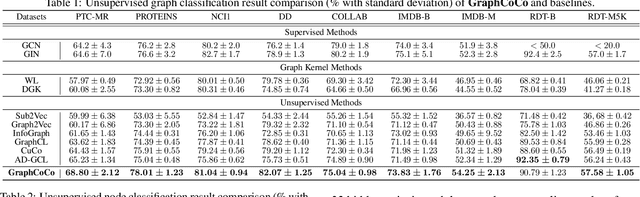
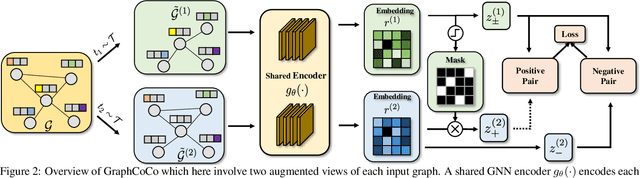
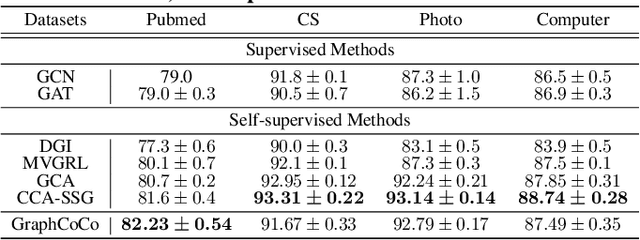
Graph Contrastive Learning (GCL) has shown promising performance in graph representation learning (GRL) without the supervision of manual annotations. GCL can generate graph-level embeddings by maximizing the Mutual Information (MI) between different augmented views of the same graph (positive pairs). However, we identify an obstacle that the optimization of InfoNCE loss only concentrates on a few embeddings dimensions, limiting the distinguishability of embeddings in downstream graph classification tasks. This paper proposes an effective graph complementary contrastive learning approach named GraphCoCo to tackle the above issue. Specifically, we set the embedding of the first augmented view as the anchor embedding to localize "highlighted" dimensions (i.e., the dimensions contribute most in similarity measurement). Then remove these dimensions in the embeddings of the second augmented view to discover neglected complementary representations. Therefore, the combination of anchor and complementary embeddings significantly improves the performance in downstream tasks. Comprehensive experiments on various benchmark datasets are conducted to demonstrate the effectiveness of GraphCoCo, and the results show that our model outperforms the state-of-the-art methods. Source code will be made publicly available.