 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverTwin: Solving Inverse Problems via Differentiable Radio Frequency Digital Twin
Aug 19, 2025Digital twins (DTs), virtual simulated replicas of physical scenes, are transforming various industries. However, their potential in radio frequency (RF) sensing applications has been limited by the unidirectional nature of conventional RF simulators. In this paper, we present InverTwin, an optimization-driven framework that creates RF digital twins by enabling bidirectional interaction between virtual and physical realms. InverTwin overcomes the fundamental differentiability challenges of RF optimization problems through novel design components, including path-space differentiation to address discontinuity in complex simulation functions, and a radar surrogate model to mitigate local non-convexity caused by RF signal periodicity. These techniques enable smooth gradient propagation and robust optimization of the DT model. Our implementation and experiments demonstrate InverTwin's versatility and effectiveness in augmenting both data-driven and model-driven RF sensing systems for DT reconstruction.
On computing and the complexity of computing higher-order $U$-statistics, exactly
Aug 18, 2025Higher-order $U$-statistics abound in fields such as statistics, machine learning, and computer science, but are known to be highly time-consuming to compute in practice. Despite their widespread appearance, a comprehensive study of their computational complexity is surprisingly lacking. This paper aims to fill that gap by presenting several results related to the computational aspect of $U$-statistics. First, we derive a useful decomposition from an $m$-th order $U$-statistic to a linear combination of $V$-statistics with orders not exceeding $m$, which are generally more feasible to compute. Second, we explore the connection between exactly computing $V$-statistics and Einstein summation, a tool often used in computational mathematics, quantum computing, and quantum information sciences for accelerating tensor computations. Third, we provide an optimistic estimate of the time complexity for exactly computing $U$-statistics, based on the treewidth of a particular graph associated with the $U$-statistic kernel. The above ingredients lead to a new, much more runtime-efficient algorithm of exactly computing general higher-order $U$-statistics. We also wrap our new algorithm into an open-source Python package called $\texttt{u-stats}$. We demonstrate via three statistical applications that $\texttt{u-stats}$ achieves impressive runtime performance compared to existing benchmarks. This paper aspires to achieve two goals: (1) to capture the interest of researchers in both statistics and other related areas further to advance the algorithmic development of $U$-statistics, and (2) to offer the package $\texttt{u-stats}$ as a valuable tool for practitioners, making the implementation of methods based on higher-order $U$-statistics a more delightful experience.
LET-US: Long Event-Text Understanding of Scenes
Aug 10, 2025Event cameras output event streams as sparse, asynchronous data with microsecond-level temporal resolution, enabling visual perception with low latency and a high dynamic range. While existing Multimodal Large Language Models (MLLMs) have achieved significant success in understanding and analyzing RGB video content, they either fail to interpret event streams effectively or remain constrained to very short sequences. In this paper, we introduce LET-US, a framework for long event-stream--text comprehension that employs an adaptive compression mechanism to reduce the volume of input events while preserving critical visual details. LET-US thus establishes a new frontier in cross-modal inferential understanding over extended event sequences. To bridge the substantial modality gap between event streams and textual representations, we adopt a two-stage optimization paradigm that progressively equips our model with the capacity to interpret event-based scenes. To handle the voluminous temporal information inherent in long event streams, we leverage text-guided cross-modal queries for feature reduction, augmented by hierarchical clustering and similarity computation to distill the most representative event features. Moreover, we curate and construct a large-scale event-text aligned dataset to train our model, achieving tighter alignment of event features within the LLM embedding space. We also develop a comprehensive benchmark covering a diverse set of tasks -- reasoning, captioning, classification, temporal localization and moment retrieval. Experimental results demonstrate that LET-US outperforms prior state-of-the-art MLLMs in both descriptive accuracy and semantic comprehension on long-duration event streams. All datasets, codes, and models will be publicly available.
KG-Augmented Executable CoT for Mathematical Coding
Aug 06, 2025In recent years, large language models (LLMs) have excelled in natural language processing tasks but face significant challenges in complex reasoning tasks such as mathematical reasoning and code generation. To address these limitations, we propose KG-Augmented Executable Chain-of-Thought (KGA-ECoT), a novel framework that enhances code generation through knowledge graphs and improves mathematical reasoning via executable code. KGA-ECoT decomposes problems into a Structured Task Graph, leverages efficient GraphRAG for precise knowledge retrieval from mathematical libraries, and generates verifiable code to ensure computational accuracy. Evaluations on multiple mathematical reasoning benchmarks demonstrate that KGA-ECoT significantly outperforms existing prompting methods, achieving absolute accuracy improvements ranging from several to over ten percentage points. Further analysis confirms the critical roles of GraphRAG in enhancing code quality and external code execution in ensuring precision. These findings collectively establish KGA-ECoT as a robust and highly generalizable framework for complex mathematical reasoning tasks.
CogDual: Enhancing Dual Cognition of LLMs via Reinforcement Learning with Implicit Rule-Based Rewards
Jul 23, 2025



Role-Playing Language Agents (RPLAs) have emerged as a significant application direction for Large Language Models (LLMs). Existing approaches typically rely on prompt engineering or supervised fine-tuning to enable models to imitate character behaviors in specific scenarios, but often neglect the underlying \emph{cognitive} mechanisms driving these behaviors. Inspired by cognitive psychology, we introduce \textbf{CogDual}, a novel RPLA adopting a \textit{cognize-then-respond } reasoning paradigm. By jointly modeling external situational awareness and internal self-awareness, CogDual generates responses with improved character consistency and contextual alignment. To further optimize the performance, we employ reinforcement learning with two general-purpose reward schemes designed for open-domain text generation. Extensive experiments on the CoSER benchmark, as well as Cross-MR and LifeChoice, demonstrate that CogDual consistently outperforms existing baselines and generalizes effectively across diverse role-playing tasks.
Rex-Thinker: Grounded Object Referring via Chain-of-Thought Reasoning
Jun 04, 2025Object referring aims to detect all objects in an image that match a given natural language description. We argue that a robust object referring model should be grounded, meaning its predictions should be both explainable and faithful to the visual content. Specifically, it should satisfy two key properties: 1) Verifiable, by producing interpretable reasoning that justifies its predictions and clearly links them to visual evidence; and 2) Trustworthy, by learning to abstain when no object in the image satisfies the given expression. However, most methods treat referring as a direct bounding box prediction task, offering limited interpretability and struggling to reject expressions with no matching object. In this work, we propose Rex-Thinker, a model that formulates object referring as an explicit CoT reasoning task. Given a referring expression, we first identify all candidate object instances corresponding to the referred object category. Rex-Thinker then performs step-by-step reasoning over each candidate to assess whether it matches the given expression, before making a final prediction. To support this paradigm, we construct a large-scale CoT-style referring dataset named HumanRef-CoT by prompting GPT-4o on the HumanRef dataset. Each reasoning trace follows a structured planning, action, and summarization format, enabling the model to learn decomposed, interpretable reasoning over object candidates. We then train Rex-Thinker in two stages: a cold-start supervised fine-tuning phase to teach the model how to perform structured reasoning, followed by GRPO-based RL learning to improve accuracy and generalization. Experiments show that our approach outperforms standard baselines in both precision and interpretability on in-domain evaluation, while also demonstrating improved ability to reject hallucinated outputs and strong generalization in out-of-domain settings.
LCB-CV-UNet: Enhanced Detector for High Dynamic Range Radar Signals
May 29, 2025We propose the LCB-CV-UNet to tackle performance degradation caused by High Dynamic Range (HDR) radar signals. Initially, a hardware-efficient, plug-and-play module named Logarithmic Connect Block (LCB) is proposed as a phase coherence preserving solution to address the inherent challenges in handling HDR features. Then, we propose the Dual Hybrid Dataset Construction method to generate a semi-synthetic dataset, approximating typical HDR signal scenarios with adjustable target distributions. Simulation results show about 1% total detection probability improvement with under 0.9% computational complexity added compared with the baseline. Furthermore, it excels 5% over the baseline at the range in 11-13 dB signal-to-noise ratio typical for urban targets. Finally, the real experiment validates the practicality of our model.
Ctrl-DNA: Controllable Cell-Type-Specific Regulatory DNA Design via Constrained RL
May 26, 2025Designing regulatory DNA sequences that achieve precise cell-type-specific gene expression is crucial for advancements in synthetic biology, gene therapy and precision medicine. Although transformer-based language models (LMs) can effectively capture patterns in regulatory DNA, their generative approaches often struggle to produce novel sequences with reliable cell-specific activity. Here, we introduce Ctrl-DNA, a novel constrained reinforcement learning (RL) framework tailored for designing regulatory DNA sequences with controllable cell-type specificity. By formulating regulatory sequence design as a biologically informed constrained optimization problem, we apply RL to autoregressive genomic LMs, enabling the models to iteratively refine sequences that maximize regulatory activity in targeted cell types while constraining off-target effects. Our evaluation on human promoters and enhancers demonstrates that Ctrl-DNA consistently outperforms existing generative and RL-based approaches, generating high-fitness regulatory sequences and achieving state-of-the-art cell-type specificity. Moreover, Ctrl-DNA-generated sequences capture key cell-type-specific transcription factor binding sites (TFBS), short DNA motifs recognized by regulatory proteins that control gene expression, demonstrating the biological plausibility of the generated sequences.
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

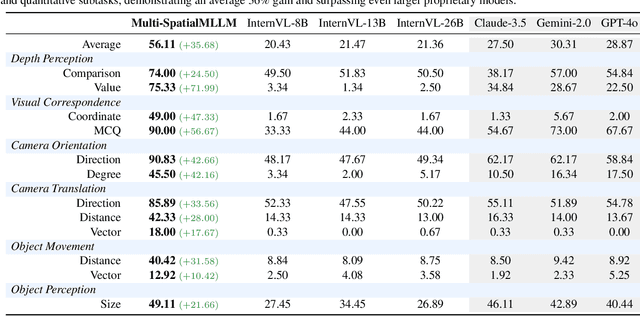
Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training
May 20, 2025Mixture-of-Experts (MoE) architectures within Large Reasoning Models (LRMs) have achieved impressive reasoning capabilities by selectively activating experts to facilitate structured cognitive processes. Despite notable advances, existing reasoning models often suffer from cognitive inefficiencies like overthinking and underthinking. To address these limitations, we introduce a novel inference-time steering methodology called Reinforcing Cognitive Experts (RICE), designed to improve reasoning performance without additional training or complex heuristics. Leveraging normalized Pointwise Mutual Information (nPMI), we systematically identify specialized experts, termed ''cognitive experts'' that orchestrate meta-level reasoning operations characterized by tokens like ''<think>''. Empirical evaluations with leading MoE-based LRMs (DeepSeek-R1 and Qwen3-235B) on rigorous quantitative and scientific reasoning benchmarks demonstrate noticeable and consistent improvements in reasoning accuracy, cognitive efficiency, and cross-domain generalization. Crucially, our lightweight approach substantially outperforms prevalent reasoning-steering techniques, such as prompt design and decoding constraints, while preserving the model's general instruction-following skills. These results highlight reinforcing cognitive experts as a promising, practical, and interpretable direction to enhance cognitive efficiency within advanced reasoning models.