 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHorizon: Towards Long-context Medical Video Understanding in the Wild
May 07, 2026Medical multimodal large language models (MLLMs) have advanced image understanding and short-video analysis, but real clinical review often requires full-procedure video understanding. Unlike general long videos, medical procedures contain highly redundant anatomical views, while decisive evidence is temporally sparse, spatially subtle, and context dependent. Existing benchmarks often assume this evidence has already been localized through images, short clips, or pre-segmented videos, leaving the retrieval-before-reasoning problem under-tested. We introduce MedHorizon, an in-the-wild benchmark for long-context medical video understanding. MedHorizon preserves 759 hours of full-length clinical procedures and provides 1,253 evidence-grounded multiple-choice questionsthat jointly evaluate sparse evidence understanding and multi-hop clinical reasoning. Its evidence is extremely sparse, with only 0.166% evidence frames on average, requiring models to search noisy procedural streams before interpreting and aggregating findings. We evaluate representative general-domain, medical-domain, and long-video MLLMs. The best model reaches only 41.1% accuracy, showing that current systems remain far from robust full-procedure understanding. Further analysis yields four key findings: performance does not scale reliably with more frames, evidence retrieval and clinical interpretation remain primary bottlenecks; these bottlenecks are rooted in weak procedural reasoning and attention drift under redundancy, and generic sampling methods only partially balances local detail with global coverage. MedHorizon provides a rigorous testbed for MLLMs that retrieve sparse evidence and reason over complete clinical workflows.
See Further, Think Deeper: Advancing VLM's Reasoning Ability with Low-level Visual Cues and Reflection
Apr 27, 2026Recent advances in Vision-Language Models (VLMs) have benefited from Reinforcement Learning (RL) for enhanced reasoning. However, existing methods still face critical limitations, including the lack of low-level visual information and effective visual feedback. To address these problems, this paper proposes a unified multimodal interleaved reasoning framework \textbf{ForeSight}, which enables VLMs to \textbf{See Further} with low-level visual cues and \textbf{Think Deeper} with effective visual feedback. First, it introduces a set of low-level visual tools to integrate essential visual information into the reasoning chain, mitigating the neglect of fine-grained visual features. Second, a mask-based visual feedback mechanism is elaborated to incorporate visual reflection into the thinking process, enabling the model to dynamically re-examine and update its answers. Driven by RL, ForeSight learns to autonomously decide on tool invocation and answer verification, with the final answer accuracy as the reward signal. To evaluate the performance of the proposed framework, we construct a new dataset, Character and Grounding SalBench (CG-SalBench), based on the SalBench dataset. Experimental results demonstrate that the ForeSight-7B model significantly outperforms other models with the same parameter scale, and even surpasses the current SOTA closed-source models on certain metrics.
M$^{2}$GRPO: Mamba-based Multi-Agent Group Relative Policy Optimization for Biomimetic Underwater Robots Pursuit
Apr 21, 2026Traditional policy learning methods in cooperative pursuit face fundamental challenges in biomimetic underwater robots, where long-horizon decision making, partial observability, and inter-robot coordination require both expressiveness and stability. To address these issues, a novel framework called Mamba-based multi-agent group relative policy optimization (M$^{2}$GRPO) is proposed, which integrates a selective state-space Mamba policy with group-relative policy optimization under the centralized-training and decentralized-execution (CTDE) paradigm. Specifically, the Mamba-based policy leverages observation history to capture long-horizon temporal dependencies and exploits attention-based relational features to encode inter-agent interactions, producing bounded continuous actions through normalized Gaussian sampling. To further improve credit assignment without sacrificing stability, the group-relative advantages are obtained by normalizing rewards across agents within each episode and optimized through a multi-agent extension of GRPO, significantly reducing the demand for training resources while enabling stable and scalable policy updates. Extensive simulations and real-world pool experiments across team scales and evader strategies demonstrate that M$^{2}$GRPO consistently outperforms MAPPO and recurrent baselines in both pursuit success rate and capture efficiency. Overall, the proposed framework provides a practical and scalable solution for cooperative underwater pursuit with biomimetic robot systems.
UC-OWOD: Unknown-Classified Open World Object Detection
Jul 23, 2022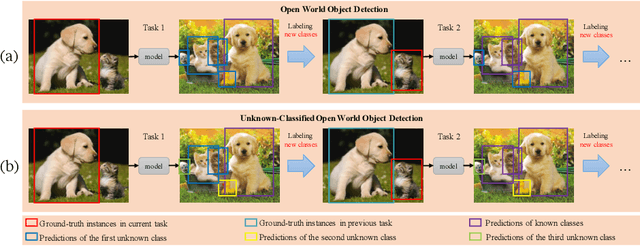
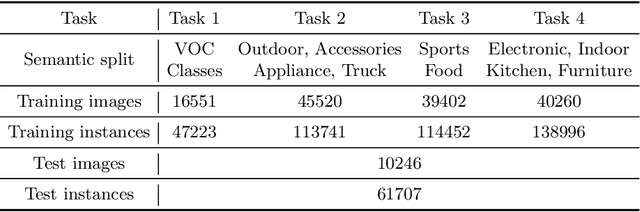
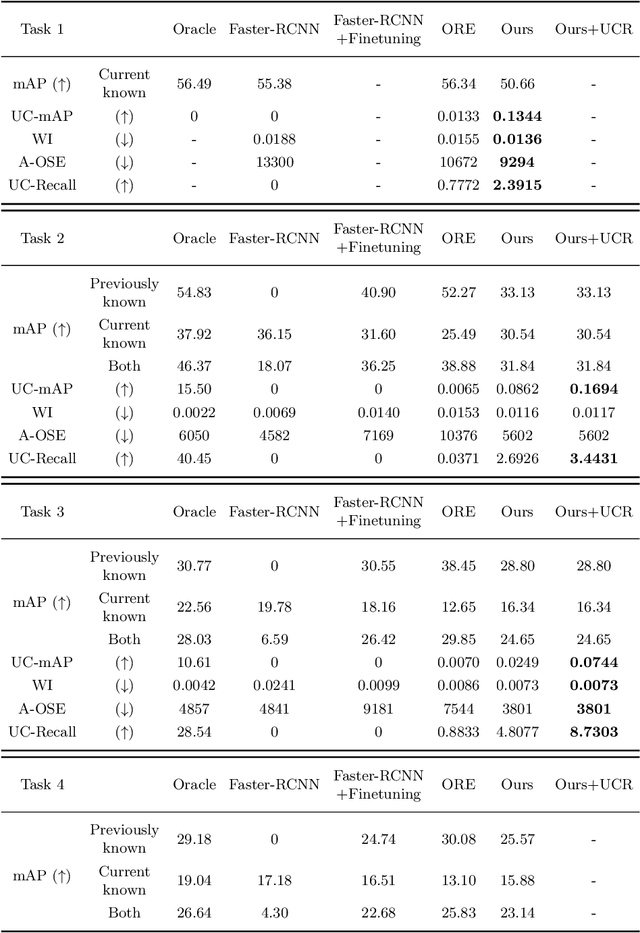

Open World Object Detection (OWOD) is a challenging computer vision problem that requires detecting unknown objects and gradually learning the identified unknown classes. However, it cannot distinguish unknown instances as multiple unknown classes. In this work, we propose a novel OWOD problem called Unknown-Classified Open World Object Detection (UC-OWOD). UC-OWOD aims to detect unknown instances and classify them into different unknown classes. Besides, we formulate the problem and devise a two-stage object detector to solve UC-OWOD. First, unknown label-aware proposal and unknown-discriminative classification head are used to detect known and unknown objects. Then, similarity-based unknown classification and unknown clustering refinement modules are constructed to distinguish multiple unknown classes. Moreover, two novel evaluation protocols are designed to evaluate unknown-class detection. Abundant experiments and visualizations prove the effectiveness of the proposed method. Code is available at https://github.com/JohnWuzh/UC-OWOD.