 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning in linear embedding space unlocks generalizable control across soft robot configurations
Jun 06, 2026Soft-bodied organisms such as octopuses and elephant trunks exhibit remarkable morphological adaptability, dynamically reconfiguring body shape and stiffness, and flexibly adjusting their control strategies to enable versatile behaviors. Inspired by these biological systems, various soft robots have emerged in recent decades, featuring diverse materials, stiffnesses, and morphologies tailored to specific tasks. Despite substantial advances in the materials and structural designs of soft robots, developing a generalizable control framework capable of rapid adaptation across diverse configurations remains a long-standing challenge. Existing controllers are limited to fixed configurations, demanding laborious configuration-specific remodelling and policy redesign for new configurations. Here, we introduce a generalizable control system that enables rapid adaptation across diverse soft robot configurations via reinforcement learning in a shared linear Koopman embedding space. By encoding robot dynamics into this embedding space, our method decouples control policies from specific morphologies, allowing real-time, model-free policy adaptation across diverse configurations without retraining from scratch. We validate our system across 33 distinct robot configurations. Our system achieves a 75 times reduction in transfer samples across configurations, while sustaining robust performance under high-speed motion, heavy payloads, and multiactuator faults, and achieving real-world skills previously unattainable in soft robotics. This work establishes a unified and adaptable control paradigm for diverse soft robot configurations, bridging mechanical reconfigurability with control flexibility, and may offer broader insights for generalizable control in complex physical systems.
Learning Predictive Control with Deep Koopman Operators for Autonomous Vehicle Motion Planning
Jun 06, 2026Model Predictive Control (MPC) is widely used for autonomous-vehicle (AV) motion planning, but its real-time applicability is often limited by the need for accurate models and online solution of nonlinear, nonconvex optimization problems in dynamic road environments. Actor-critic reinforcement learning offers a promising alternative for online policy generation, yet its policy-learning process often lacks explicit control-theoretic structure. This article proposes a learning predictive control (LPC) framework with deep Koopman operators for efficient real-time motion planning under nonconvex constraints. To address nonlinear and uncertain vehicle dynamics, a deep-Koopman-based predictor is used to lift the system into an interpretable linear observable space in a data-driven manner. Unlike traditional MPC, which computes open-loop control sequences, the proposed LPC framework yields a closed-loop state-feedback policy within each prediction interval through receding-horizon actor-critic learning. To ensure safety under nonconvex environmental constraints, LPC constructs convex local surrogate representations of obstacles and defines corresponding potential-field functions. These functions and their gradients are directly embedded into the actor-critic structure, enabling efficient, safety-aware policy learning. Extensive simulations and real-world experiments on the HongQi-EHS3 platform demonstrate favorable performance in diverse obstacle-avoidance scenarios in terms of safety, computational efficiency, and driving comfort, compared with benchmark methods such as CBF-MPC and LMPCC.
Physics-Guided Deep Unfolding for Blind Cross-Sensor Spectral Super-Resolution via Learning the Spectral Transformation Function
Jun 04, 2026Hyperspectral imaging provides rich spectral information for quantitative remote sensing, yet hyperspectral sensors remain costly and thus unavailable in many UAV deployments. Spectral super-resolution (SSR) seeks to reconstruct hyperspectral images (HSIs) from multispectral images (MSIs). Most existing SSR methods assume a fixed and known spectral response function (SRF) and are therefore limited to single-sensor settings. In practical cross-sensor scenarios, the spectral degradation from HSI to MSI is unknown and varies with sensor characteristics and scene content, which renders HSI reconstruction ill-posed. This paper proposes a physics-guided deep unfolding network, termed PGU-Net, to address blind cross-sensor SSR by jointly estimating the HSI and a learnable spectral transformation function (STF). PGU-Net unrolls an alternating optimization procedure into an end-to-end trainable architecture with stages, where each stage sequentially updates the HSI and the STF. Both modules combine learnable proximal networks with differentiable closed-form solvers, enabling physical interpretability while retaining strong representation capacity. Experiments on benchmark datasets (CAVE and NTIRE 2022) with multiple SRFs demonstrate accurate recovery of the STF (degradation operator) and improved reconstruction performance over state-of-the-art SSR methods. Furthermore, evaluations on a real UAV cross-sensor dataset (Headwall Nano HSI and DJI P4 Multispectral MSI) verify the effectiveness and robustness of PGU-Net under truly blind conditions, and suggest that the estimated STF may exhibit land-cover-related differences.
TurboAgent: An LLM-Driven Autonomous Multi-Agent Framework for Turbomachinery Aerodynamic Design
Apr 09, 2026The aerodynamic design of turbomachinery is a complex and tightly coupled multi-stage process involving geometry generation, performance prediction, optimization, and high-fidelity physical validation. Existing intelligent design approaches typically focus on individual stages or rely on loosely coupled pipelines, making fully autonomous end-to-end design challenging. To address this issue, this study proposes TurboAgent, a large language model (LLM)-driven autonomous multi-agent framework for turbomachinery aerodynamic design and optimization. The LLM serves as the core for task planning and coordination, while specialized agents handle generative design, rapid performance prediction, multi-objective optimization, and physics-based validation. The framework transforms traditional trial-and-error design into a data-driven collaborative workflow, with high-fidelity simulations retained for final verification. A transonic single-rotor compressor is used for validation. The results show strong agreement between target performance, generated designs, and CFD simulations. The coefficients of determination for mass flow rate, total pressure ratio, and isentropic efficiency all exceed 0.91, with normalized RMSE values below 8%. The optimization agent further improves isentropic efficiency by 1.61% and total pressure ratio by 3.02%. The complete workflow can be executed within approximately 30 minutes under parallel computing. These results demonstrate that TurboAgent enables an autonomous closed-loop design process from natural language requirements to final design generation, providing an efficient and scalable paradigm for turbomachinery aerodynamic design.
Diffusion Policies with Value-Conditional Optimization for Offline Reinforcement Learning
Nov 12, 2025



In offline reinforcement learning, value overestimation caused by out-of-distribution (OOD) actions significantly limits policy performance. Recently, diffusion models have been leveraged for their strong distribution-matching capabilities, enforcing conservatism through behavior policy constraints. However, existing methods often apply indiscriminate regularization to redundant actions in low-quality datasets, resulting in excessive conservatism and an imbalance between the expressiveness and efficiency of diffusion modeling. To address these issues, we propose DIffusion policies with Value-conditional Optimization (DIVO), a novel approach that leverages diffusion models to generate high-quality, broadly covered in-distribution state-action samples while facilitating efficient policy improvement. Specifically, DIVO introduces a binary-weighted mechanism that utilizes the advantage values of actions in the offline dataset to guide diffusion model training. This enables a more precise alignment with the dataset's distribution while selectively expanding the boundaries of high-advantage actions. During policy improvement, DIVO dynamically filters high-return-potential actions from the diffusion model, effectively guiding the learned policy toward better performance. This approach achieves a critical balance between conservatism and explorability in offline RL. We evaluate DIVO on the D4RL benchmark and compare it against state-of-the-art baselines. Empirical results demonstrate that DIVO achieves superior performance, delivering significant improvements in average returns across locomotion tasks and outperforming existing methods in the challenging AntMaze domain, where sparse rewards pose a major difficulty.
Versatile Distributed Maneuvering with Generalized Formations using Guiding Vector Fields
May 09, 2025



This paper presents a unified approach to realize versatile distributed maneuvering with generalized formations. Specifically, we decompose the robots' maneuvers into two independent components, i.e., interception and enclosing, which are parameterized by two independent virtual coordinates. Treating these two virtual coordinates as dimensions of an abstract manifold, we derive the corresponding singularity-free guiding vector field (GVF), which, along with a distributed coordination mechanism based on the consensus theory, guides robots to achieve various motions (i.e., versatile maneuvering), including (a) formation tracking, (b) target enclosing, and (c) circumnavigation. Additional motion parameters can generate more complex cooperative robot motions. Based on GVFs, we design a controller for a nonholonomic robot model. Besides the theoretical results, extensive simulations and experiments are performed to validate the effectiveness of the approach.
Flexible Exoskeleton Control Based on Binding Alignment Strategy and Full-arm Coordination Mechanism
Mar 03, 2025In rehabilitation, powered, and teleoperation exoskeletons, connecting the human body to the exoskeleton through binding attachments is a common configuration. However, the uncertainty of the tightness and the donning deviation of the binding attachments will affect the flexibility and comfort of the exoskeletons, especially during high-speed movement. To address this challenge, this paper presents a flexible exoskeleton control approach with binding alignment and full-arm coordination. Firstly, the sources of the force interaction caused by donning offsets are analyzed, based on which the interactive force data is classified into the major, assistant, coordination, and redundant component categories. Then, a binding alignment strategy (BAS) is proposed to reduce the donning disturbances by combining different force data. Furthermore, we propose a full-arm coordination mechanism (FCM) that focuses on two modes of arm movement intent, joint-oriented and target-oriented, to improve the flexible performance of the whole exoskeleton control during high-speed motion. In this method, we propose an algorithm to distinguish the two intentions to resolve the conflict issue of the force component. Finally, a series of experiments covering various aspects of exoskeleton performance (flexibility, adaptability, accuracy, speed, and fatigue) were conducted to demonstrate the benefits of our control framework in our full-arm exoskeleton.
Toward Scalable Multirobot Control: Fast Policy Learning in Distributed MPC
Dec 27, 2024



Distributed model predictive control (DMPC) is promising in achieving optimal cooperative control in multirobot systems (MRS). However, real-time DMPC implementation relies on numerical optimization tools to periodically calculate local control sequences online. This process is computationally demanding and lacks scalability for large-scale, nonlinear MRS. This article proposes a novel distributed learning-based predictive control (DLPC) framework for scalable multirobot control. Unlike conventional DMPC methods that calculate open-loop control sequences, our approach centers around a computationally fast and efficient distributed policy learning algorithm that generates explicit closed-loop DMPC policies for MRS without using numerical solvers. The policy learning is executed incrementally and forward in time in each prediction interval through an online distributed actor-critic implementation. The control policies are successively updated in a receding-horizon manner, enabling fast and efficient policy learning with the closed-loop stability guarantee. The learned control policies could be deployed online to MRS with varying robot scales, enhancing scalability and transferability for large-scale MRS. Furthermore, we extend our methodology to address the multirobot safe learning challenge through a force field-inspired policy learning approach. We validate our approach's effectiveness, scalability, and efficiency through extensive experiments on cooperative tasks of large-scale wheeled robots and multirotor drones. Our results demonstrate the rapid learning and deployment of DMPC policies for MRS with scales up to 10,000 units.
Learning-based Near-optimal Motion Planning for Intelligent Vehicles with Uncertain Dynamics
Aug 09, 2023Motion planning has been an important research topic in achieving safe and flexible maneuvers for intelligent vehicles. However, it remains challenging to realize efficient and optimal planning in the presence of uncertain model dynamics. In this paper, a sparse kernel-based reinforcement learning (RL) algorithm with Gaussian Process (GP) Regression (called GP-SKRL) is proposed to achieve online adaption and near-optimal motion planning performance. In this algorithm, we design an efficient sparse GP regression method to learn the uncertain dynamics. Based on the updated model, a sparse kernel-based policy iteration algorithm with an exponential barrier function is designed to learn the near-optimal planning policies with the capability to avoid dynamic obstacles. Thereby, batch-mode GP-SKRL with online adaption capability can estimate the changing system dynamics. The converged RL policies are then deployed on vehicles efficiently under a safety-aware module. As a result, the produced driving actions are safe and less conservative, and the planning performance has been noticeably improved. Extensive simulation results show that GP-SKRL outperforms several advanced motion planning methods in terms of average cumulative cost, trajectory length, and task completion time. In particular, experiments on a Hongqi E-HS3 vehicle demonstrate that superior GP-SKRL provides a practical planning solution.
Model-Based Safe Reinforcement Learning with Time-Varying State and Control Constraints: An Application to Intelligent Vehicles
Dec 18, 2021
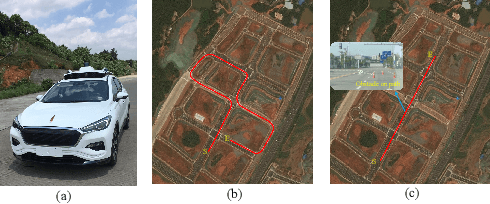
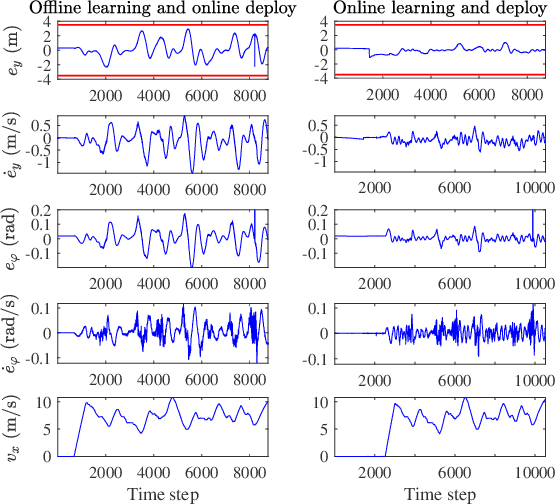
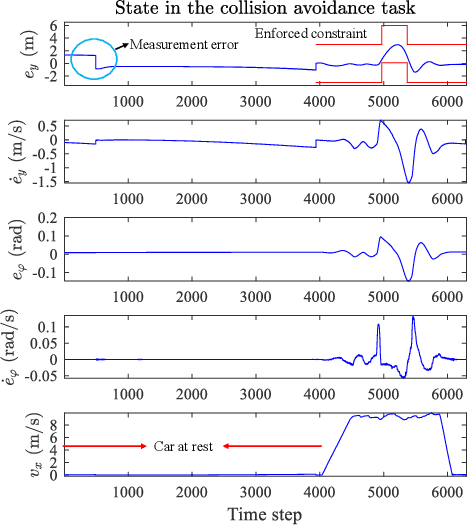
Recently, barrier function-based safe reinforcement learning (RL) with the actor-critic structure for continuous control tasks has received increasing attention. It is still challenging to learn a near-optimal control policy with safety and convergence guarantees. Also, few works have addressed the safe RL algorithm design under time-varying safety constraints. This paper proposes a model-based safe RL algorithm for optimal control of nonlinear systems with time-varying state and control constraints. In the proposed approach, we construct a novel barrier-based control policy structure that can guarantee control safety. A multi-step policy evaluation mechanism is proposed to predict the policy's safety risk under time-varying safety constraints and guide the policy to update safely. Theoretical results on stability and robustness are proven. Also, the convergence of the actor-critic learning algorithm is analyzed. The performance of the proposed algorithm outperforms several state-of-the-art RL algorithms in the simulated Safety Gym environment. Furthermore, the approach is applied to the integrated path following and collision avoidance problem for two real-world intelligent vehicles. A differential-drive vehicle and an Ackermann-drive one are used to verify the offline deployment performance and the online learning performance, respectively. Our approach shows an impressive sim-to-real transfer capability and a satisfactory online control performance in the experiment.