 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA2D-MORL: Pareto Ascent Directional Decomposition based Multi-Objective Reinforcement Learning
Mar 20, 2026Multi-objective reinforcement learning (MORL) provides an effective solution for decision-making problems involving conflicting objectives. However, achieving high-quality approximations to the Pareto policy set remains challenging, especially in complex tasks with continuous or high-dimensional state-action space. In this paper, we propose the Pareto Ascent Directional Decomposition based Multi-Objective Reinforcement Learning (PA2D-MORL) method, which constructs an efficient scheme for multi-objective problem decomposition and policy improvement, leading to a superior approximation of Pareto policy set. The proposed method leverages Pareto ascent direction to select the scalarization weights and computes the multi-objective policy gradient, which determines the policy optimization direction and ensures joint improvement on all objectives. Meanwhile, multiple policies are selectively optimized under an evolutionary framework to approximate the Pareto frontier from different directions. Additionally, a Pareto adaptive fine-tuning approach is applied to enhance the density and spread of the Pareto frontier approximation. Experiments on various multi-objective robot control tasks show that the proposed method clearly outperforms the current state-of-the-art algorithm in terms of both quality and stability of the outcomes.
* AAAI 2024
MO-MIX: Multi-Objective Multi-Agent Cooperative Decision-Making With Deep Reinforcement Learning
Feb 28, 2026Deep reinforcement learning (RL) has been applied extensively to solve complex decision-making problems. In many real-world scenarios, tasks often have several conflicting objectives and may require multiple agents to cooperate, which are the multi-objective multi-agent decision-making problems. However, only few works have been conducted on this intersection. Existing approaches are limited to separate fields and can only handle multi-agent decision-making with a single objective, or multi-objective decision-making with a single agent. In this paper, we propose MO-MIX to solve the multi-objective multi-agent reinforcement learning (MOMARL) problem. Our approach is based on the centralized training with decentralized execution (CTDE) framework. A weight vector representing preference over the objectives is fed into the decentralized agent network as a condition for local action-value function estimation, while a mixing network with parallel architecture is used to estimate the joint action-value function. In addition, an exploration guide approach is applied to improve the uniformity of the final non-dominated solutions. Experiments demonstrate that the proposed method can effectively solve the multi-objective multi-agent cooperative decision-making problem and generate an approximation of the Pareto set. Our approach not only significantly outperforms the baseline method in all four kinds of evaluation metrics, but also requires less computational cost.
* 15 pages, 10 figures, published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
DACESR: Degradation-Aware Conditional Embedding for Real-World Image Super-Resolution
Feb 27, 2026Multimodal large models have shown excellent ability in addressing image super-resolution in real-world scenarios by leveraging language class as condition information, yet their abilities in degraded images remain limited. In this paper, we first revisit the capabilities of the Recognize Anything Model (RAM) for degraded images by calculating text similarity. We find that directly using contrastive learning to fine-tune RAM in the degraded space is difficult to achieve acceptable results. To address this issue, we employ a degradation selection strategy to propose a Real Embedding Extractor (REE), which achieves significant recognition performance gain on degraded image content through contrastive learning. Furthermore, we use a Conditional Feature Modulator (CFM) to incorporate the high-level information of REE for a powerful Mamba-based network, which can leverage effective pixel information to restore image textures and produce visually pleasing results. Extensive experiments demonstrate that the REE can effectively help image super-resolution networks balance fidelity and perceptual quality, highlighting the great potential of Mamba in real-world applications. The source code of this work will be made publicly available at: https://github.com/nathan66666/DACESR.git
RIDER: 3D RNA Inverse Design with Reinforcement Learning-Guided Diffusion
Feb 18, 2026The inverse design of RNA three-dimensional (3D) structures is crucial for engineering functional RNAs in synthetic biology and therapeutics. While recent deep learning approaches have advanced this field, they are typically optimized and evaluated using native sequence recovery, which is a limited surrogate for structural fidelity, since different sequences can fold into similar 3D structures and high recovery does not necessarily indicate correct folding. To address this limitation, we propose RIDER, an RNA Inverse DEsign framework with Reinforcement learning that directly optimizes for 3D structural similarity. First, we develop and pre-train a GNN-based generative diffusion model conditioned on the target 3D structure, achieving a 9% improvement in native sequence recovery over state-of-the-art methods. Then, we fine-tune the model with an improved policy gradient algorithm using four task-specific reward functions based on 3D self-consistency metrics. Experimental results show that RIDER improves structural similarity by over 100% across all metrics and discovers designs that are distinct from native sequences.
Beyond Monotonicity: Revisiting Factorization Principles in Multi-Agent Q-Learning
Nov 12, 2025Value decomposition is a central approach in multi-agent reinforcement learning (MARL), enabling centralized training with decentralized execution by factorizing the global value function into local values. To ensure individual-global-max (IGM) consistency, existing methods either enforce monotonicity constraints, which limit expressive power, or adopt softer surrogates at the cost of algorithmic complexity. In this work, we present a dynamical systems analysis of non-monotonic value decomposition, modeling learning dynamics as continuous-time gradient flow. We prove that, under approximately greedy exploration, all zero-loss equilibria violating IGM consistency are unstable saddle points, while only IGM-consistent solutions are stable attractors of the learning dynamics. Extensive experiments on both synthetic matrix games and challenging MARL benchmarks demonstrate that unconstrained, non-monotonic factorization reliably recovers IGM-optimal solutions and consistently outperforms monotonic baselines. Additionally, we investigate the influence of temporal-difference targets and exploration strategies, providing actionable insights for the design of future value-based MARL algorithms.
Decentralized Multi-agent Reinforcement Learning based State-of-Charge Balancing Strategy for Distributed Energy Storage System
Aug 29, 2023



This paper develops a Decentralized Multi-Agent Reinforcement Learning (Dec-MARL) method to solve the SoC balancing problem in the distributed energy storage system (DESS). First, the SoC balancing problem is formulated into a finite Markov decision process with action constraints derived from demand balance, which can be solved by Dec-MARL. Specifically, the first-order average consensus algorithm is utilized to expand the observations of the DESS state in a fully-decentralized way, and the initial actions (i.e., output power) are decided by the agents (i.e., energy storage units) according to these observations. In order to get the final actions in the allowable range, a counterfactual demand balance algorithm is proposed to balance the total demand and the initial actions. Next, the agents execute the final actions and get local rewards from the environment, and the DESS steps into the next state. Finally, through the first-order average consensus algorithm, the agents get the average reward and the expended observation of the next state for later training. By the above procedure, Dec-MARL reveals outstanding performance in a fully-decentralized system without any expert experience or constructing any complicated model. Besides, it is flexible and can be extended to other decentralized multi-agent systems straightforwardly. Extensive simulations have validated the effectiveness and efficiency of Dec-MARL.
AutoPCF: Efficient Product Carbon Footprint Accounting with Large Language Models
Aug 11, 2023The product carbon footprint (PCF) is crucial for decarbonizing the supply chain, as it measures the direct and indirect greenhouse gas emissions caused by all activities during the product's life cycle. However, PCF accounting often requires expert knowledge and significant time to construct life cycle models. In this study, we test and compare the emergent ability of five large language models (LLMs) in modeling the 'cradle-to-gate' life cycles of products and generating the inventory data of inputs and outputs, revealing their limitations as a generalized PCF knowledge database. By utilizing LLMs, we propose an automatic AI-driven PCF accounting framework, called AutoPCF, which also applies deep learning algorithms to automatically match calculation parameters, and ultimately calculate the PCF. The results of estimating the carbon footprint for three case products using the AutoPCF framework demonstrate its potential in achieving automatic modeling and estimation of PCF with a large reduction in modeling time from days to minutes.
IMKGA-SM: Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling
Jan 11, 2023



Multimodal knowledge graph link prediction aims to improve the accuracy and efficiency of link prediction tasks for multimodal data. However, for complex multimodal information and sparse training data, it is usually difficult to achieve interpretability and high accuracy simultaneously for most methods. To address this difficulty, a new model is developed in this paper, namely Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling (IMKGA-SM). First, a multi-modal fine-grained fusion method is proposed, and Vgg16 and Optical Character Recognition (OCR) techniques are adopted to effectively extract text information from images and images. Then, the knowledge graph link prediction task is modelled as an offline reinforcement learning Markov decision model, which is then abstracted into a unified sequence framework. An interactive perception-based reward expectation mechanism and a special causal masking mechanism are designed, which "converts" the query into an inference path. Then, an autoregressive dynamic gradient adjustment mechanism is proposed to alleviate the insufficient problem of multimodal optimization. Finally, two datasets are adopted for experiments, and the popular SOTA baselines are used for comparison. The results show that the developed IMKGA-SM achieves much better performance than SOTA baselines on multimodal link prediction datasets of different sizes.
Model-Based Safe Reinforcement Learning with Time-Varying State and Control Constraints: An Application to Intelligent Vehicles
Dec 18, 2021
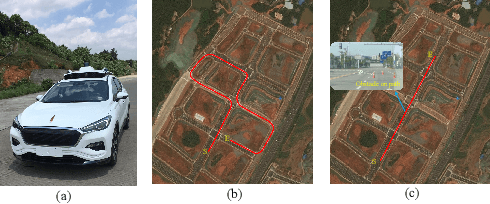
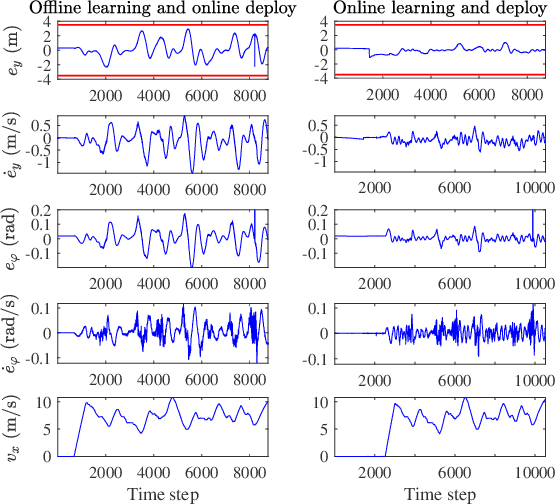
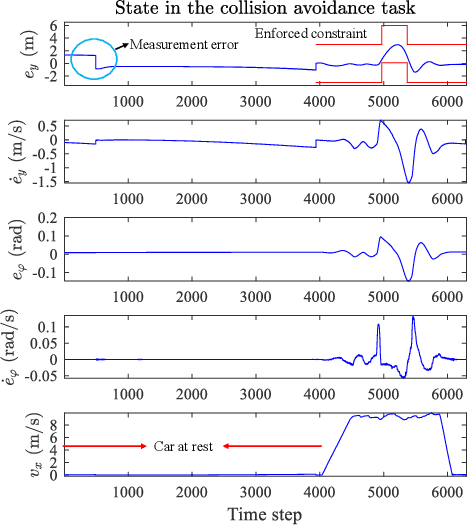
Recently, barrier function-based safe reinforcement learning (RL) with the actor-critic structure for continuous control tasks has received increasing attention. It is still challenging to learn a near-optimal control policy with safety and convergence guarantees. Also, few works have addressed the safe RL algorithm design under time-varying safety constraints. This paper proposes a model-based safe RL algorithm for optimal control of nonlinear systems with time-varying state and control constraints. In the proposed approach, we construct a novel barrier-based control policy structure that can guarantee control safety. A multi-step policy evaluation mechanism is proposed to predict the policy's safety risk under time-varying safety constraints and guide the policy to update safely. Theoretical results on stability and robustness are proven. Also, the convergence of the actor-critic learning algorithm is analyzed. The performance of the proposed algorithm outperforms several state-of-the-art RL algorithms in the simulated Safety Gym environment. Furthermore, the approach is applied to the integrated path following and collision avoidance problem for two real-world intelligent vehicles. A differential-drive vehicle and an Ackermann-drive one are used to verify the offline deployment performance and the online learning performance, respectively. Our approach shows an impressive sim-to-real transfer capability and a satisfactory online control performance in the experiment.
Q-learning for Optimal Control of Continuous-time Systems
Oct 11, 2014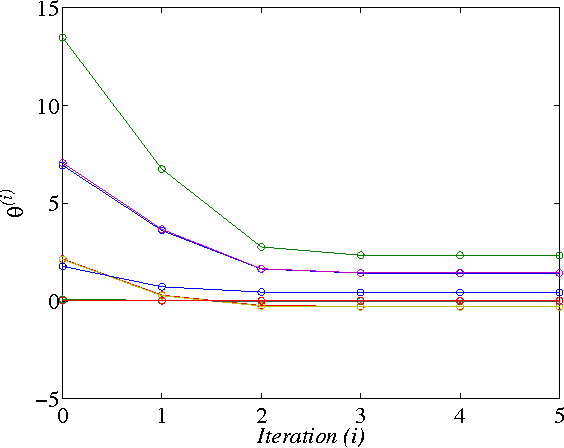
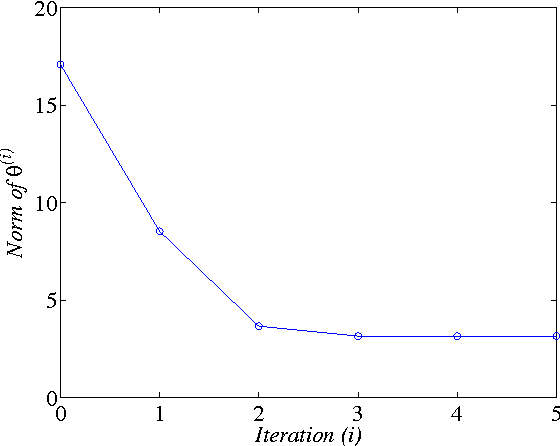
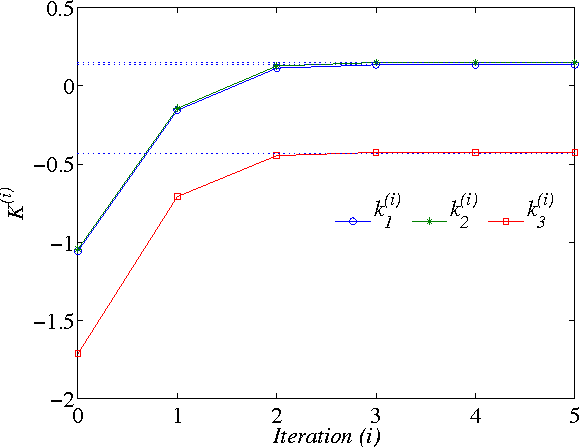
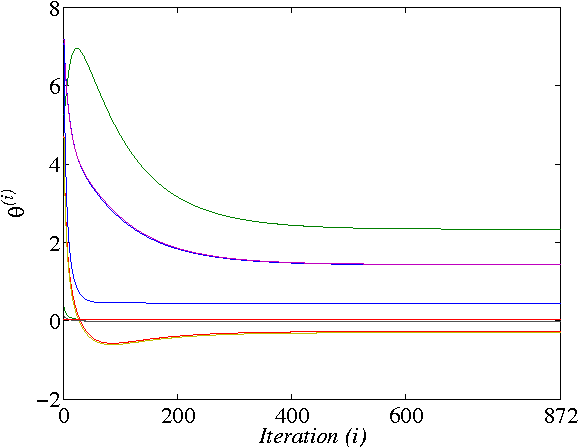
In this paper, two Q-learning (QL) methods are proposed and their convergence theories are established for addressing the model-free optimal control problem of general nonlinear continuous-time systems. By introducing the Q-function for continuous-time systems, policy iteration based QL (PIQL) and value iteration based QL (VIQL) algorithms are proposed for learning the optimal control policy from real system data rather than using mathematical system model. It is proved that both PIQL and VIQL methods generate a nonincreasing Q-function sequence, which converges to the optimal Q-function. For implementation of the QL algorithms, the method of weighted residuals is applied to derived the parameters update rule. The developed PIQL and VIQL algorithms are essentially off-policy reinforcement learning approachs, where the system data can be collected arbitrary and thus the exploration ability is increased. With the data collected from the real system, the QL methods learn the optimal control policy offline, and then the convergent control policy will be employed to real system. The effectiveness of the developed QL algorithms are verified through computer simulation.