 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based SLAM Benchmark for High-Speed Maneuvers
Apr 27, 2026Event-based cameras are bio-inspired sensors with pixels that independently and asynchronously respond to brightness changes at microsecond resolution, offering the potential to handle visual tasks in high-speed maneuvering scenarios. Existing event-based approaches, although successful in mitigating motion blur caused by high-speed maneuvers, suffer from many limitations. Some of them highlight a success of pose tracking for a fronto-parallel fast shaking camera closed to the structure, while others assume pure (optionally aggressive) three-degree-of-freedom rotations. The former requires persistent local map visibility within the field of view (FOV), whereas the latter fails to generalize to six-degree-of-freedom (6-DoF) motions where both linear and angular velocities may be large. Consequently, current successes do not fully demonstrate that event-based state estimation under arbitrary aggressive maneuvers is a fully solved problem. To quantitatively assess the extent to which the potential of event cameras has been unlocked, we conduct a thorough analysis of state-of-the-art (SOTA) event-based visual odometry (VO)/visual-inertial odometry (VIO) methods and report shortcomings in current public datasets. Furthermore, we introduce a benchmarking framework for event-based state estimation, called EvSLAM, characterized by sufficient variation in data collection platforms, diverse extreme lighting scenarios, and a wide scope of challenging motion patterns under a clear and rigorous definition of high-speed maneuvers for mobile robots, along with a novel evaluation metric designed to fairly assess the operational limits of event-based solutions. This framework benchmarks state-of-the-art methods, yielding insights into optimal architectures and persistent challenges.
GESS: Multi-cue Guided Local Feature Learning via Geometric and Semantic Synergy
Apr 07, 2026Robust local feature detection and description are foundational tasks in computer vision. Existing methods primarily rely on single appearance cues for modeling, leading to unstable keypoints and insufficient descriptor discriminability. In this paper, we propose a multi-cue guided local feature learning framework that leverages semantic and geometric cues to synergistically enhance detection robustness and descriptor discriminability. Specifically, we construct a joint semantic-normal prediction head and a depth stability prediction head atop a lightweight backbone. The former leverages a shared 3D vector field to deeply couple semantic and normal cues, thereby resolving optimization interference from heterogeneous inconsistencies. The latter quantifies the reliability of local regions from a geometric consistency perspective, providing deterministic guidance for robust keypoint selection. Based on these predictions, we introduce the Semantic-Depth Aware Keypoint (SDAK) mechanism for feature detection. By coupling semantic reliability with depth stability, SDAK reweights keypoint responses to suppress spurious features in unreliable regions. For descriptor construction, we design a Unified Triple-Cue Fusion (UTCF) module, which employs a semantic-scheduled gating mechanism to adaptively inject multi-attribute features, improving descriptor discriminability. Extensive experiments on four benchmarks validate the effectiveness of the proposed framework. The source code and pre-trained model will be available at: https://github.com/yiyscut/GESS.git.
TAPFormer: Robust Arbitrary Point Tracking via Transient Asynchronous Fusion of Frames and Events
Mar 05, 2026Tracking any point (TAP) is a fundamental yet challenging task in computer vision, requiring high precision and long-term motion reasoning. Recent attempts to combine RGB frames and event streams have shown promise, yet they typically rely on synchronous or non-adaptive fusion, leading to temporal misalignment and severe degradation when one modality fails. We introduce TAPFormer, a transformer-based framework that performs asynchronous temporal-consistent fusion of frames and events for robust and high-frequency arbitrary point tracking. Our key innovation is a Transient Asynchronous Fusion (TAF) mechanism, which explicitly models the temporal evolution between discrete frames through continuous event updates, bridging the gap between low-rate frames and high-rate events. In addition, a Cross-modal Locally Weighted Fusion (CLWF) module adaptively adjusts spatial attention according to modality reliability, yielding stable and discriminative features even under blur or low light. To evaluate our approach under realistic conditions, we construct a novel real-world frame-event TAP dataset under diverse illumination and motion conditions. Our method outperforms existing point trackers, achieving a 28.2% improvement in average pixel error within threshold. Moreover, on standard point tracking benchmarks, our tracker consistently achieves the best performance. Project website: tapformer.github.io
Grasp Like Humans: Learning Generalizable Multi-Fingered Grasping from Human Proprioceptive Sensorimotor Integration
Sep 10, 2025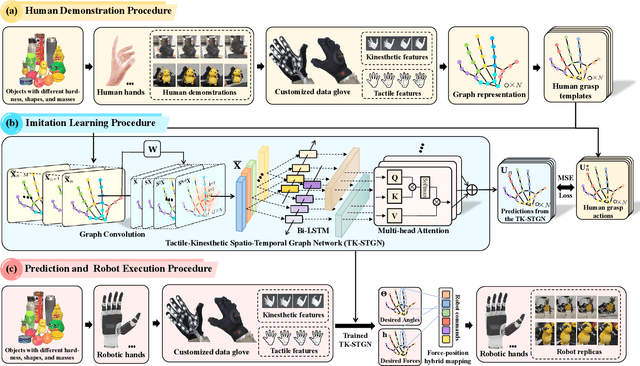
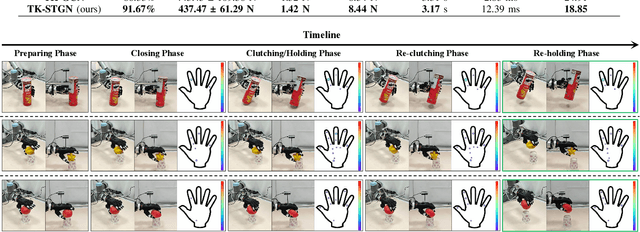

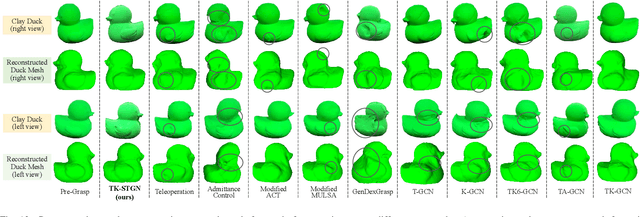
Tactile and kinesthetic perceptions are crucial for human dexterous manipulation, enabling reliable grasping of objects via proprioceptive sensorimotor integration. For robotic hands, even though acquiring such tactile and kinesthetic feedback is feasible, establishing a direct mapping from this sensory feedback to motor actions remains challenging. In this paper, we propose a novel glove-mediated tactile-kinematic perception-prediction framework for grasp skill transfer from human intuitive and natural operation to robotic execution based on imitation learning, and its effectiveness is validated through generalized grasping tasks, including those involving deformable objects. Firstly, we integrate a data glove to capture tactile and kinesthetic data at the joint level. The glove is adaptable for both human and robotic hands, allowing data collection from natural human hand demonstrations across different scenarios. It ensures consistency in the raw data format, enabling evaluation of grasping for both human and robotic hands. Secondly, we establish a unified representation of multi-modal inputs based on graph structures with polar coordinates. We explicitly integrate the morphological differences into the designed representation, enhancing the compatibility across different demonstrators and robotic hands. Furthermore, we introduce the Tactile-Kinesthetic Spatio-Temporal Graph Networks (TK-STGN), which leverage multidimensional subgraph convolutions and attention-based LSTM layers to extract spatio-temporal features from graph inputs to predict node-based states for each hand joint. These predictions are then mapped to final commands through a force-position hybrid mapping.
Fully Spiking Neural Networks for Unified Frame-Event Object Tracking
May 27, 2025The integration of image and event streams offers a promising approach for achieving robust visual object tracking in complex environments. However, current fusion methods achieve high performance at the cost of significant computational overhead and struggle to efficiently extract the sparse, asynchronous information from event streams, failing to leverage the energy-efficient advantages of event-driven spiking paradigms. To address this challenge, we propose the first fully Spiking Frame-Event Tracking framework called SpikeFET. This network achieves synergistic integration of convolutional local feature extraction and Transformer-based global modeling within the spiking paradigm, effectively fusing frame and event data. To overcome the degradation of translation invariance caused by convolutional padding, we introduce a Random Patchwork Module (RPM) that eliminates positional bias through randomized spatial reorganization and learnable type encoding while preserving residual structures. Furthermore, we propose a Spatial-Temporal Regularization (STR) strategy that overcomes similarity metric degradation from asymmetric features by enforcing spatio-temporal consistency among temporal template features in latent space. Extensive experiments across multiple benchmarks demonstrate that the proposed framework achieves superior tracking accuracy over existing methods while significantly reducing power consumption, attaining an optimal balance between performance and efficiency. The code will be released.
A Plug-and-Play Learning-based IMU Bias Factor for Robust Visual-Inertial Odometry
Mar 16, 2025



The bias of low-cost Inertial Measurement Units (IMU) is a critical factor affecting the performance of Visual-Inertial Odometry (VIO). In particular, when visual tracking encounters errors, the optimized bias results may deviate significantly from the true values, adversely impacting the system's stability and localization precision. In this paper, we propose a novel plug-and-play framework featuring the Inertial Prior Network (IPNet), which is designed to accurately estimate IMU bias. Recognizing the substantial impact of initial bias errors in low-cost inertial devices on system performance, our network directly leverages raw IMU data to estimate the mean bias, eliminating the dependency on historical estimates in traditional recursive predictions and effectively preventing error propagation. Furthermore, we introduce an iterative approach to calculate the mean value of the bias for network training, addressing the lack of bias labels in many visual-inertial datasets. The framework is evaluated on two public datasets and one self-collected dataset. Extensive experiments demonstrate that our method significantly enhances both localization precision and robustness, with the ATE-RMSE metric improving on average by 46\%. The source code and video will be available at \textcolor{red}{https://github.com/yiyscut/VIO-IPNet.git}.
Uncertainty-Aware Normal-Guided Gaussian Splatting for Surface Reconstruction from Sparse Image Sequences
Mar 14, 20253D Gaussian Splatting (3DGS) has achieved impressive rendering performance in novel view synthesis. However, its efficacy diminishes considerably in sparse image sequences, where inherent data sparsity amplifies geometric uncertainty during optimization. This often leads to convergence at suboptimal local minima, resulting in noticeable structural artifacts in the reconstructed scenes.To mitigate these issues, we propose Uncertainty-aware Normal-Guided Gaussian Splatting (UNG-GS), a novel framework featuring an explicit Spatial Uncertainty Field (SUF) to quantify geometric uncertainty within the 3DGS pipeline. UNG-GS enables high-fidelity rendering and achieves high-precision reconstruction without relying on priors. Specifically, we first integrate Gaussian-based probabilistic modeling into the training of 3DGS to optimize the SUF, providing the model with adaptive error tolerance. An uncertainty-aware depth rendering strategy is then employed to weight depth contributions based on the SUF, effectively reducing noise while preserving fine details. Furthermore, an uncertainty-guided normal refinement method adjusts the influence of neighboring depth values in normal estimation, promoting robust results. Extensive experiments demonstrate that UNG-GS significantly outperforms state-of-the-art methods in both sparse and dense sequences. The code will be open-source.
Toward Scalable Multirobot Control: Fast Policy Learning in Distributed MPC
Dec 27, 2024



Distributed model predictive control (DMPC) is promising in achieving optimal cooperative control in multirobot systems (MRS). However, real-time DMPC implementation relies on numerical optimization tools to periodically calculate local control sequences online. This process is computationally demanding and lacks scalability for large-scale, nonlinear MRS. This article proposes a novel distributed learning-based predictive control (DLPC) framework for scalable multirobot control. Unlike conventional DMPC methods that calculate open-loop control sequences, our approach centers around a computationally fast and efficient distributed policy learning algorithm that generates explicit closed-loop DMPC policies for MRS without using numerical solvers. The policy learning is executed incrementally and forward in time in each prediction interval through an online distributed actor-critic implementation. The control policies are successively updated in a receding-horizon manner, enabling fast and efficient policy learning with the closed-loop stability guarantee. The learned control policies could be deployed online to MRS with varying robot scales, enhancing scalability and transferability for large-scale MRS. Furthermore, we extend our methodology to address the multirobot safe learning challenge through a force field-inspired policy learning approach. We validate our approach's effectiveness, scalability, and efficiency through extensive experiments on cooperative tasks of large-scale wheeled robots and multirotor drones. Our results demonstrate the rapid learning and deployment of DMPC policies for MRS with scales up to 10,000 units.
Tracking Any Point with Frame-Event Fusion Network at High Frame Rate
Sep 18, 2024



Tracking any point based on image frames is constrained by frame rates, leading to instability in high-speed scenarios and limited generalization in real-world applications. To overcome these limitations, we propose an image-event fusion point tracker, FE-TAP, which combines the contextual information from image frames with the high temporal resolution of events, achieving high frame rate and robust point tracking under various challenging conditions. Specifically, we designed an Evolution Fusion module (EvoFusion) to model the image generation process guided by events. This module can effectively integrate valuable information from both modalities operating at different frequencies. To achieve smoother point trajectories, we employed a transformer-based refinement strategy that updates the point's trajectories and features iteratively. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches, particularly improving expected feature age by 24$\%$ on EDS datasets. Finally, we qualitatively validated the robustness of our algorithm in real driving scenarios using our custom-designed high-resolution image-event synchronization device. Our source code will be released at https://github.com/ljx1002/FE-TAP.
TD-NeRF: Novel Truncated Depth Prior for Joint Camera Pose and Neural Radiance Field Optimization
May 11, 2024



The reliance on accurate camera poses is a significant barrier to the widespread deployment of Neural Radiance Fields (NeRF) models for 3D reconstruction and SLAM tasks. The existing method introduces monocular depth priors to jointly optimize the camera poses and NeRF, which fails to fully exploit the depth priors and neglects the impact of their inherent noise. In this paper, we propose Truncated Depth NeRF (TD-NeRF), a novel approach that enables training NeRF from unknown camera poses - by jointly optimizing learnable parameters of the radiance field and camera poses. Our approach explicitly utilizes monocular depth priors through three key advancements: 1) we propose a novel depth-based ray sampling strategy based on the truncated normal distribution, which improves the convergence speed and accuracy of pose estimation; 2) to circumvent local minima and refine depth geometry, we introduce a coarse-to-fine training strategy that progressively improves the depth precision; 3) we propose a more robust inter-frame point constraint that enhances robustness against depth noise during training. The experimental results on three datasets demonstrate that TD-NeRF achieves superior performance in the joint optimization of camera pose and NeRF, surpassing prior works, and generates more accurate depth geometry. The implementation of our method has been released at https://github.com/nubot-nudt/TD-NeRF.