 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODE-DITING: A Reasoning-Based Metric for Functional Alignment in Code Evaluation
May 26, 2025Trustworthy evaluation methods for code snippets play a crucial role in neural code generation. Traditional methods, which either rely on reference solutions or require executable test cases, have inherent limitation in flexibility and scalability. The recent LLM-as-Judge methodology offers a promising alternative by directly evaluating functional consistency between the problem description and the generated code. To systematically understand the landscape of these LLM-as-Judge methods, we conduct a comprehensive empirical study across three diverse datasets. Our investigation reveals the pros and cons of two categories of LLM-as-Judge methods: the methods based on general foundation models can achieve good performance but require complex prompts and lack explainability, while the methods based on reasoning foundation models provide better explainability with simpler prompts but demand substantial computational resources due to their large parameter sizes. To address these limitations, we propose CODE-DITING, a novel code evaluation method that balances accuracy, efficiency and explainability. We develop a data distillation framework that effectively transfers reasoning capabilities from DeepSeek-R1671B to our CODE-DITING 1.5B and 7B models, significantly enhancing evaluation explainability and reducing the computational cost. With the majority vote strategy in the inference process, CODE-DITING 1.5B outperforms all models with the same magnitude of parameters and achieves performance which would normally exhibit in a model with 5 times of parameter scale. CODE-DITING 7B surpasses GPT-4o and DeepSeek-V3 671B, even though it only uses 1% of the parameter volume of these large models. Further experiments show that CODEDITING is robust to preference leakage and can serve as a promising alternative for code evaluation.
Semi-pessimistic Reinforcement Learning
May 25, 2025Offline reinforcement learning (RL) aims to learn an optimal policy from pre-collected data. However, it faces challenges of distributional shift, where the learned policy may encounter unseen scenarios not covered in the offline data. Additionally, numerous applications suffer from a scarcity of labeled reward data. Relying on labeled data alone often leads to a narrow state-action distribution, further amplifying the distributional shift, and resulting in suboptimal policy learning. To address these issues, we first recognize that the volume of unlabeled data is typically substantially larger than that of labeled data. We then propose a semi-pessimistic RL method to effectively leverage abundant unlabeled data. Our approach offers several advantages. It considerably simplifies the learning process, as it seeks a lower bound of the reward function, rather than that of the Q-function or state transition function. It is highly flexible, and can be integrated with a range of model-free and model-based RL algorithms. It enjoys the guaranteed improvement when utilizing vast unlabeled data, but requires much less restrictive conditions. We compare our method with a number of alternative solutions, both analytically and numerically, and demonstrate its clear competitiveness. We further illustrate with an application to adaptive deep brain stimulation for Parkinson's disease.
Response Uncertainty and Probe Modeling: Two Sides of the Same Coin in LLM Interpretability?
May 24, 2025Probing techniques have shown promise in revealing how LLMs encode human-interpretable concepts, particularly when applied to curated datasets. However, the factors governing a dataset's suitability for effective probe training are not well-understood. This study hypothesizes that probe performance on such datasets reflects characteristics of both the LLM's generated responses and its internal feature space. Through quantitative analysis of probe performance and LLM response uncertainty across a series of tasks, we find a strong correlation: improved probe performance consistently corresponds to a reduction in response uncertainty, and vice versa. Subsequently, we delve deeper into this correlation through the lens of feature importance analysis. Our findings indicate that high LLM response variance is associated with a larger set of important features, which poses a greater challenge for probe models and often results in diminished performance. Moreover, leveraging the insights from response uncertainty analysis, we are able to identify concrete examples where LLM representations align with human knowledge across diverse domains, offering additional evidence of interpretable reasoning in LLMs.
MoTime: A Dataset Suite for Multimodal Time Series Forecasting
May 21, 2025While multimodal data sources are increasingly available from real-world forecasting, most existing research remains on unimodal time series. In this work, we present MoTime, a suite of multimodal time series forecasting datasets that pair temporal signals with external modalities such as text, metadata, and images. Covering diverse domains, MoTime supports structured evaluation of modality utility under two scenarios: 1) the common forecasting task, where varying-length history is available, and 2) cold-start forecasting, where no historical data is available. Experiments show that external modalities can improve forecasting performance in both scenarios, with particularly strong benefits for short series in some datasets, though the impact varies depending on data characteristics. By making datasets and findings publicly available, we aim to support more comprehensive and realistic benchmarks in future multimodal time series forecasting research.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025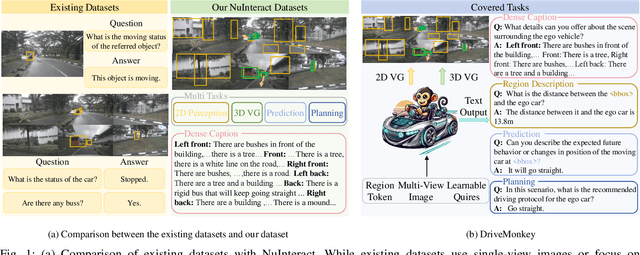

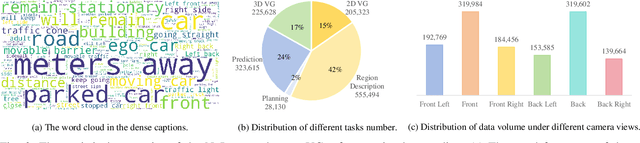
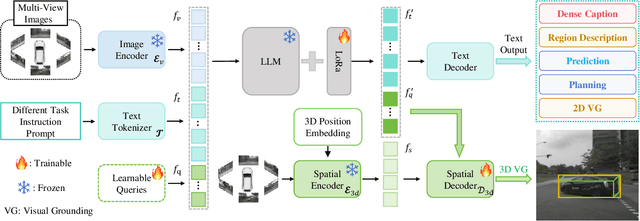
The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.
Learning Item Representations Directly from Multimodal Features for Effective Recommendation
May 08, 2025Conventional multimodal recommender systems predominantly leverage Bayesian Personalized Ranking (BPR) optimization to learn item representations by amalgamating item identity (ID) embeddings with multimodal features. Nevertheless, our empirical and theoretical findings unequivocally demonstrate a pronounced optimization gradient bias in favor of acquiring representations from multimodal features over item ID embeddings. As a consequence, item ID embeddings frequently exhibit suboptimal characteristics despite the convergence of multimodal feature parameters. Given the rich informational content inherent in multimodal features, in this paper, we propose a novel model (i.e., LIRDRec) that learns item representations directly from these features to augment recommendation performance. Recognizing that features derived from each modality may capture disparate yet correlated aspects of items, we propose a multimodal transformation mechanism, integrated with modality-specific encoders, to effectively fuse features from all modalities. Moreover, to differentiate the influence of diverse modality types, we devise a progressive weight copying fusion module within LIRDRec. This module incrementally learns the weight assigned to each modality in synthesizing the final user or item representations. Finally, we utilize the powerful visual understanding of Multimodal Large Language Models (MLLMs) to convert the item images into texts and extract semantics embeddings upon the texts via LLMs. Empirical evaluations conducted on five real-world datasets validate the superiority of our approach relative to competing baselines. It is worth noting the proposed model, equipped with embeddings extracted from MLLMs and LLMs, can further improve the recommendation accuracy of NDCG@20 by an average of 4.21% compared to the original embeddings.
AI-powered virtual eye: perspective, challenges and opportunities
May 07, 2025We envision the "virtual eye" as a next-generation, AI-powered platform that uses interconnected foundation models to simulate the eye's intricate structure and biological function across all scales. Advances in AI, imaging, and multiomics provide a fertile ground for constructing a universal, high-fidelity digital replica of the human eye. This perspective traces the evolution from early mechanistic and rule-based models to contemporary AI-driven approaches, integrating in a unified model with multimodal, multiscale, dynamic predictive capabilities and embedded feedback mechanisms. We propose a development roadmap emphasizing the roles of large-scale multimodal datasets, generative AI, foundation models, agent-based architectures, and interactive interfaces. Despite challenges in interpretability, ethics, data processing and evaluation, the virtual eye holds the potential to revolutionize personalized ophthalmic care and accelerate research into ocular health and disease.
LMDepth: Lightweight Mamba-based Monocular Depth Estimation for Real-World Deployment
May 02, 2025Monocular depth estimation provides an additional depth dimension to RGB images, making it widely applicable in various fields such as virtual reality, autonomous driving and robotic navigation. However, existing depth estimation algorithms often struggle to effectively balance performance and computational efficiency, which poses challenges for deployment on resource-constrained devices. To address this, we propose LMDepth, a lightweight Mamba-based monocular depth estimation network, designed to reconstruct high-precision depth information while maintaining low computational overhead. Specifically, we propose a modified pyramid spatial pooling module that serves as a multi-scale feature aggregator and context extractor, ensuring global spatial information for accurate depth estimation. Moreover, we integrate multiple depth Mamba blocks into the decoder. Designed with linear computations, the Mamba Blocks enable LMDepth to efficiently decode depth information from global features, providing a lightweight alternative to Transformer-based architectures that depend on complex attention mechanisms. Extensive experiments on the NYUDv2 and KITTI datasets demonstrate the effectiveness of our proposed LMDepth. Compared to previous lightweight depth estimation methods, LMDepth achieves higher performance with fewer parameters and lower computational complexity (measured by GFLOPs). We further deploy LMDepth on an embedded platform with INT8 quantization, validating its practicality for real-world edge applications.
Effective Length Extrapolation via Dimension-Wise Positional Embeddings Manipulation
Apr 26, 2025Large Language Models (LLMs) often struggle to process and generate coherent context when the number of input tokens exceeds the pre-trained length. Recent advancements in long-context extension have significantly expanded the context window of LLMs but require expensive overhead to train the large-scale models with longer context. In this work, we propose Dimension-Wise Positional Embeddings Manipulation (DPE), a training-free framework to extrapolate the context window of LLMs by diving into RoPE's different hidden dimensions. Instead of manipulating all dimensions equally, DPE detects the effective length for every dimension and finds the key dimensions for context extension. We reuse the original position indices with their embeddings from the pre-trained model and manipulate the key dimensions' position indices to their most effective lengths. In this way, DPE adjusts the pre-trained models with minimal modifications while ensuring that each dimension reaches its optimal state for extrapolation. DPE significantly surpasses well-known baselines such as YaRN and Self-Extend. DPE enables Llama3-8k 8B to support context windows of 128k tokens without continual training and integrates seamlessly with Flash Attention 2. In addition to its impressive extrapolation capability, DPE also dramatically improves the models' performance within training length, such as Llama3.1 70B, by over 18 points on popular long-context benchmarks RULER. When compared with commercial models, Llama 3.1 70B with DPE even achieves better performance than GPT-4-128K.
SOFARI-R: High-Dimensional Manifold-Based Inference for Latent Responses
Apr 24, 2025



Data reduction with uncertainty quantification plays a key role in various multi-task learning applications, where large numbers of responses and features are present. To this end, a general framework of high-dimensional manifold-based SOFAR inference (SOFARI) was introduced recently in Zheng, Zhou, Fan and Lv (2024) for interpretable multi-task learning inference focusing on the left factor vectors and singular values exploiting the latent singular value decomposition (SVD) structure. Yet, designing a valid inference procedure on the latent right factor vectors is not straightforward from that of the left ones and can be even more challenging due to asymmetry of left and right singular vectors in the response matrix. To tackle these issues, in this paper we suggest a new method of high-dimensional manifold-based SOFAR inference for latent responses (SOFARI-R), where two variants of SOFARI-R are introduced. The first variant deals with strongly orthogonal factors by coupling left singular vectors with the design matrix and then appropriately rescaling them to generate new Stiefel manifolds. The second variant handles the more general weakly orthogonal factors by employing the hard-thresholded SOFARI estimates and delicately incorporating approximation errors into the distribution. Both variants produce bias-corrected estimators for the latent right factor vectors that enjoy asymptotically normal distributions with justified asymptotic variance estimates. We demonstrate the effectiveness of the newly suggested method using extensive simulation studies and an economic application.