 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Bounds for a Diffusion Model-Based Drift Estimator
Jun 01, 2026Parameter estimation in stochastic differential equations is a classical statistical problem of much importance in many scientific fields. Recent work of Tapia Costa et al. (2026) introduced a novel technique for estimating the drift when the diffusion parameter is known, using discrete samples from multiple trajectories. Their method treats drift estimation as a denoising problem, and leverages tools from (conditional) score-matching diffusion models. Although their experiments showed promising results across different drift classes, the question of theoretical guarantees for their estimator was left unanswered. In this note, we address this gap by exploiting techniques from diffusion model theory. More concretely, we derive an explicit risk bound for the time-averaged mean-squared error of said drift estimator. Our bound decomposes the risk into the (i) Euler-Maruyama discretization, (ii) score/denoiser approximation, (iii) noise initialization, and (iv) sampling variance, revealing the trade-offs between the different hyperparameters and sources of error in the estimator.
Semi-pessimistic Reinforcement Learning
May 25, 2025Offline reinforcement learning (RL) aims to learn an optimal policy from pre-collected data. However, it faces challenges of distributional shift, where the learned policy may encounter unseen scenarios not covered in the offline data. Additionally, numerous applications suffer from a scarcity of labeled reward data. Relying on labeled data alone often leads to a narrow state-action distribution, further amplifying the distributional shift, and resulting in suboptimal policy learning. To address these issues, we first recognize that the volume of unlabeled data is typically substantially larger than that of labeled data. We then propose a semi-pessimistic RL method to effectively leverage abundant unlabeled data. Our approach offers several advantages. It considerably simplifies the learning process, as it seeks a lower bound of the reward function, rather than that of the Q-function or state transition function. It is highly flexible, and can be integrated with a range of model-free and model-based RL algorithms. It enjoys the guaranteed improvement when utilizing vast unlabeled data, but requires much less restrictive conditions. We compare our method with a number of alternative solutions, both analytically and numerically, and demonstrate its clear competitiveness. We further illustrate with an application to adaptive deep brain stimulation for Parkinson's disease.
A note on generalization bounds for losses with finite moments
Mar 25, 2024
This paper studies the truncation method from Alquier [1] to derive high-probability PAC-Bayes bounds for unbounded losses with heavy tails. Assuming that the $p$-th moment is bounded, the resulting bounds interpolate between a slow rate $1 / \sqrt{n}$ when $p=2$, and a fast rate $1 / n$ when $p \to \infty$ and the loss is essentially bounded. Moreover, the paper derives a high-probability PAC-Bayes bound for losses with a bounded variance. This bound has an exponentially better dependence on the confidence parameter and the dependency measure than previous bounds in the literature. Finally, the paper extends all results to guarantees in expectation and single-draw PAC-Bayes. In order to so, it obtains analogues of the PAC-Bayes fast rate bound for bounded losses from [2] in these settings.
A Note on the Convergence of Denoising Diffusion Probabilistic Models
Dec 10, 2023
Diffusion models are one of the most important families of deep generative models. In this note, we derive a quantitative upper bound on the Wasserstein distance between the data-generating distribution and the distribution learned by a diffusion model. Unlike previous works in this field, our result does not make assumptions on the learned score function. Moreover, our bound holds for arbitrary data-generating distributions on bounded instance spaces, even those without a density w.r.t. the Lebesgue measure, and the upper bound does not suffer from exponential dependencies. Our main result builds upon the recent work of Mbacke et al. (2023) and our proofs are elementary.
Semi-Counterfactual Risk Minimization Via Neural Networks
Sep 28, 2022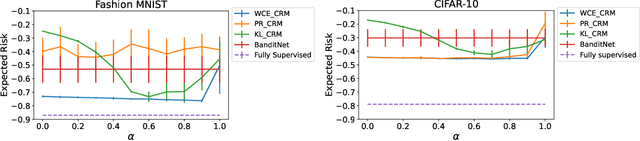

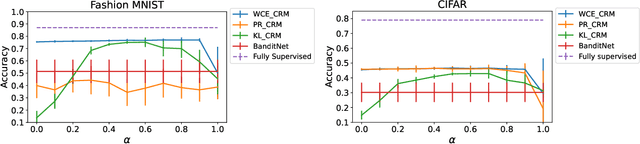
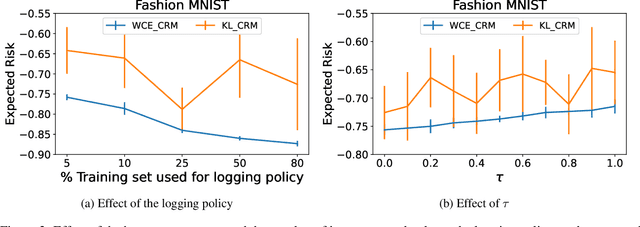
Counterfactual risk minimization is a framework for offline policy optimization with logged data which consists of context, action, propensity score, and reward for each sample point. In this work, we build on this framework and propose a learning method for settings where the rewards for some samples are not observed, and so the logged data consists of a subset of samples with unknown rewards and a subset of samples with known rewards. This setting arises in many application domains, including advertising and healthcare. While reward feedback is missing for some samples, it is possible to leverage the unknown-reward samples in order to minimize the risk, and we refer to this setting as semi-counterfactual risk minimization. To approach this kind of learning problem, we derive new upper bounds on the true risk under the inverse propensity score estimator. We then build upon these bounds to propose a regularized counterfactual risk minimization method, where the regularization term is based on the logged unknown-rewards dataset only; hence it is reward-independent. We also propose another algorithm based on generating pseudo-rewards for the logged unknown-rewards dataset. Experimental results with neural networks and benchmark datasets indicate that these algorithms can leverage the logged unknown-rewards dataset besides the logged known-reward dataset.
Progress in Self-Certified Neural Networks
Nov 23, 2021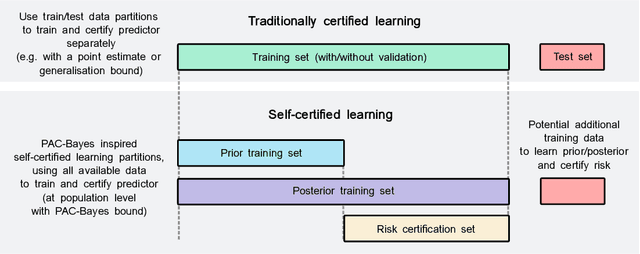
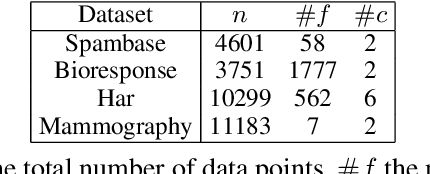
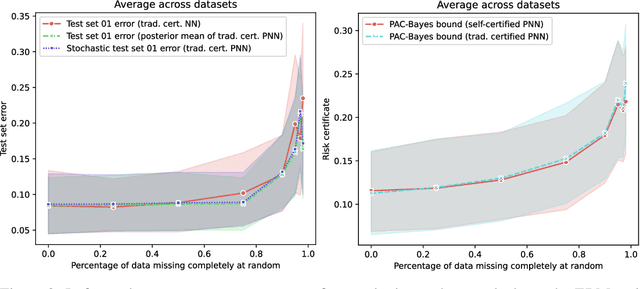
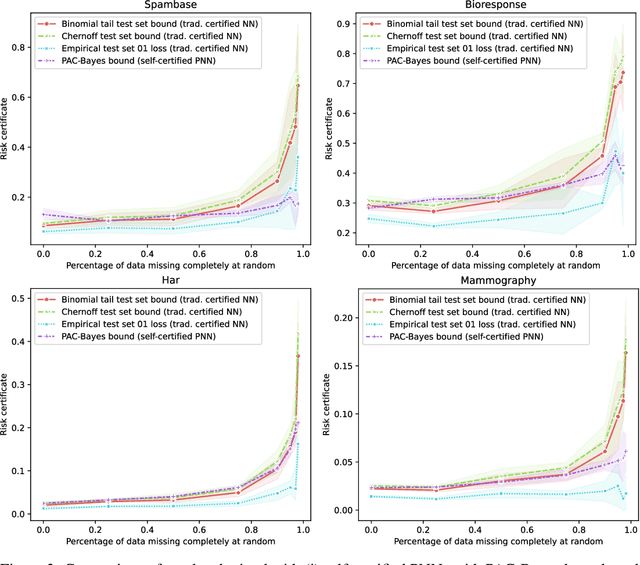
A learning method is self-certified if it uses all available data to simultaneously learn a predictor and certify its quality with a tight statistical certificate that is valid on unseen data. Recent work has shown that neural network models trained by optimising PAC-Bayes bounds lead not only to accurate predictors, but also to tight risk certificates, bearing promise towards achieving self-certified learning. In this context, learning and certification strategies based on PAC-Bayes bounds are especially attractive due to their ability to leverage all data to learn a posterior and simultaneously certify its risk with a tight numerical certificate. In this paper, we assess the progress towards self-certification in probabilistic neural networks learnt by PAC-Bayes inspired objectives. We empirically compare (on 4 classification datasets) classical test set bounds for deterministic predictors and a PAC-Bayes bound for randomised self-certified predictors. We first show that both of these generalisation bounds are not too far from out-of-sample test set errors. We then show that in data starvation regimes, holding out data for the test set bounds adversely affects generalisation performance, while self-certified strategies based on PAC-Bayes bounds do not suffer from this drawback, proving that they might be a suitable choice for the small data regime. We also find that probabilistic neural networks learnt by PAC-Bayes inspired objectives lead to certificates that can be surprisingly competitive with commonly used test set bounds.
* arXiv admin note: substantial text overlap with arXiv:2109.10304
Learning PAC-Bayes Priors for Probabilistic Neural Networks
Sep 21, 2021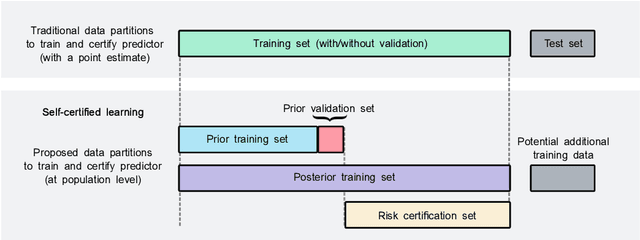
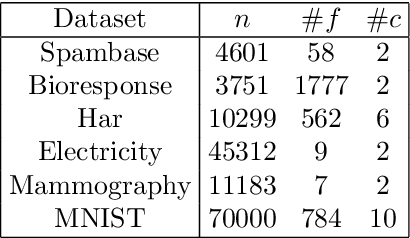
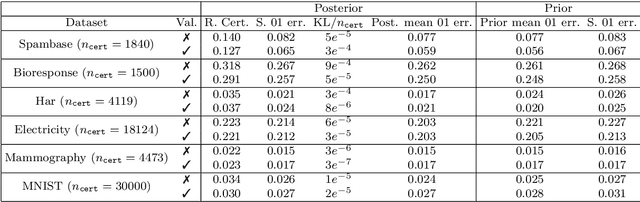
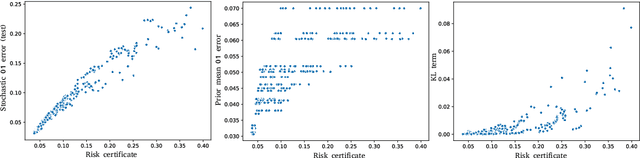
Recent works have investigated deep learning models trained by optimising PAC-Bayes bounds, with priors that are learnt on subsets of the data. This combination has been shown to lead not only to accurate classifiers, but also to remarkably tight risk certificates, bearing promise towards self-certified learning (i.e. use all the data to learn a predictor and certify its quality). In this work, we empirically investigate the role of the prior. We experiment on 6 datasets with different strategies and amounts of data to learn data-dependent PAC-Bayes priors, and we compare them in terms of their effect on test performance of the learnt predictors and tightness of their risk certificate. We ask what is the optimal amount of data which should be allocated for building the prior and show that the optimum may be dataset dependent. We demonstrate that using a small percentage of the prior-building data for validation of the prior leads to promising results. We include a comparison of underparameterised and overparameterised models, along with an empirical study of different training objectives and regularisation strategies to learn the prior distribution.
On the Role of Optimization in Double Descent: A Least Squares Study
Jul 27, 2021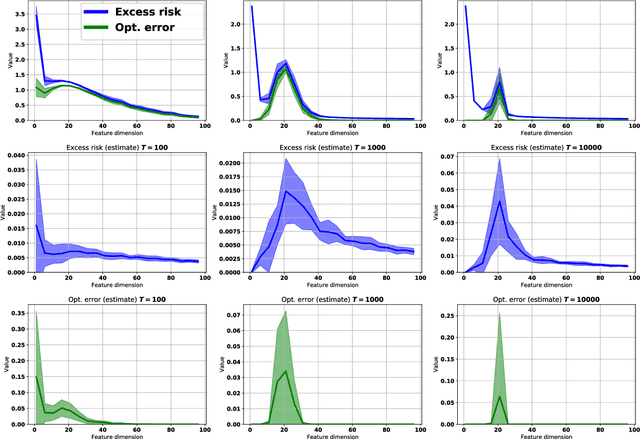
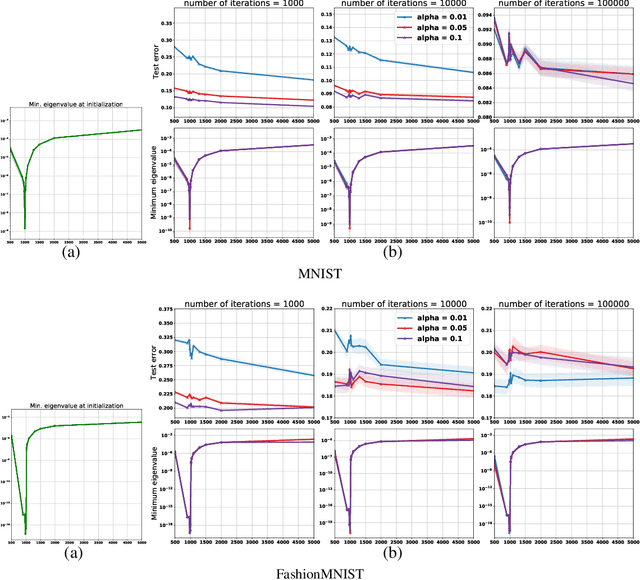
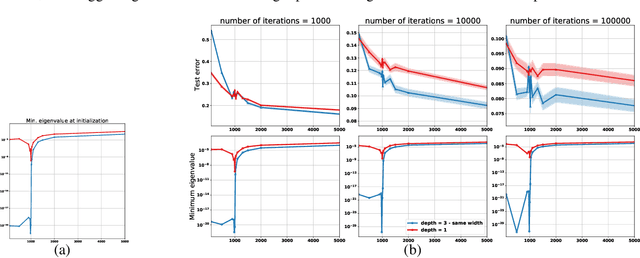
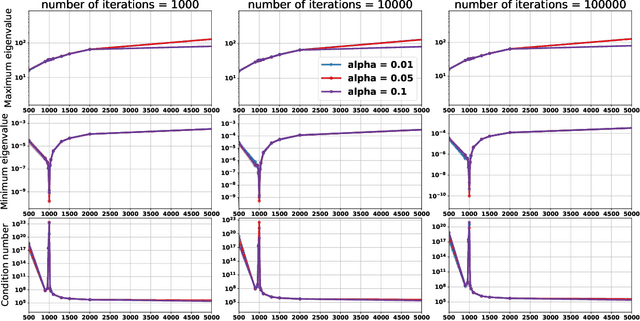
Empirically it has been observed that the performance of deep neural networks steadily improves as we increase model size, contradicting the classical view on overfitting and generalization. Recently, the double descent phenomena has been proposed to reconcile this observation with theory, suggesting that the test error has a second descent when the model becomes sufficiently overparameterized, as the model size itself acts as an implicit regularizer. In this paper we add to the growing body of work in this space, providing a careful study of learning dynamics as a function of model size for the least squares scenario. We show an excess risk bound for the gradient descent solution of the least squares objective. The bound depends on the smallest non-zero eigenvalue of the covariance matrix of the input features, via a functional form that has the double descent behavior. This gives a new perspective on the double descent curves reported in the literature. Our analysis of the excess risk allows to decouple the effect of optimization and generalization error. In particular, we find that in case of noiseless regression, double descent is explained solely by optimization-related quantities, which was missed in studies focusing on the Moore-Penrose pseudoinverse solution. We believe that our derivation provides an alternative view compared to existing work, shedding some light on a possible cause of this phenomena, at least in the considered least squares setting. We empirically explore if our predictions hold for neural networks, in particular whether the covariance of intermediary hidden activations has a similar behavior as the one predicted by our derivations.
A note on a confidence bound of Kuzborskij and Szepesvári
Jan 12, 2021In an interesting recent work, Kuzborskij and Szepesv\'ari derived a confidence bound for functions of independent random variables, which is based on an inequality that relates concentration to squared perturbations of the chosen function. Kuzborskij and Szepesv\'ari also established the PAC-Bayes-ification of their confidence bound. Two important aspects of their work are that the random variables could be of unbounded range, and not necessarily of an identical distribution. The purpose of this note is to advertise/discuss these interesting results, with streamlined proofs. This expository note is written for persons who, metaphorically speaking, enjoy the "featured movie" but prefer to skip the preview sequence.
Upper and Lower Bounds on the Performance of Kernel PCA
Dec 18, 2020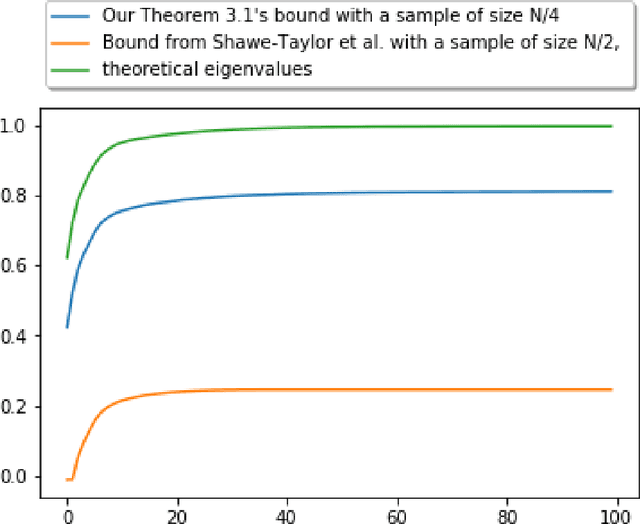
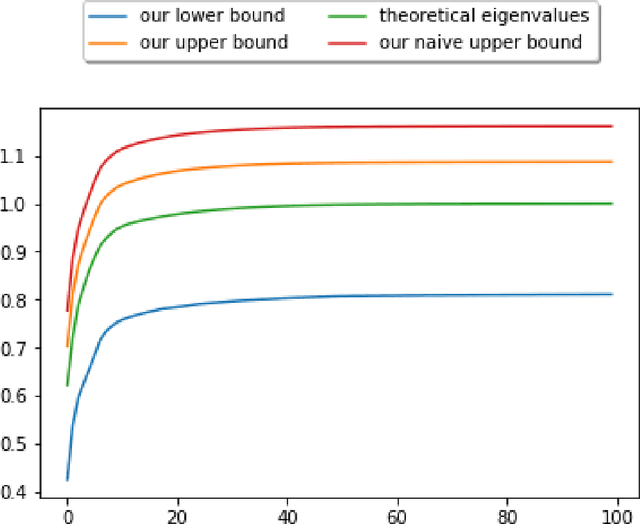
Principal Component Analysis (PCA) is a popular method for dimension reduction and has attracted an unfailing interest for decades. Recently, kernel PCA has emerged as an extension of PCA but, despite its use in practice, a sound theoretical understanding of kernel PCA is missing. In this paper, we contribute lower and upper bounds on the efficiency of kernel PCA, involving the empirical eigenvalues of the kernel Gram matrix. Two bounds are for fixed estimators, and two are for randomized estimators through the PAC-Bayes theory. We control how much information is captured by kernel PCA on average, and we dissect the bounds to highlight strengths and limitations of the kernel PCA algorithm. Therefore, we contribute to the better understanding of kernel PCA. Our bounds are briefly illustrated on a toy numerical example.