 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiDA: Phonetically-Informed Data Augmentation for Robust Vietnamese Speech Translation
Jun 11, 2026Cascaded speech translation (ST) systems suffer from error propagation when Automatic Speech Recognition (ASR) outputs incorrect transcripts. We present the first systematic categorization of ASR errors for Vietnamese ST, classifying substitution errors by phonetic cause and quantifying their impact on downstream Neural Machine Translation (NMT) performance using Linear Mixed-Effects Modelling. We confirm that most ASR substitution errors arise from phonetic confusions rather than random noise, and that these phonetic errors significantly degrade ST quality. Motivated by this finding, we propose Phonetically-Informed Data Augmentation (PiDA), which generates ASR-like corruptions by substituting words with phonetically similar alternatives using phonetic word embeddings. Fine-tuning on a PiDA-augmented version of FLEURS Vietnamese-English improves translation of erroneous ASR outputs (up to +2.04 BLEU over standard fine-tuning) while also slightly improving clean-text performance.
Contrastive Training with LLM-generated Near-Misses for Robust Code-Switching Speech Recognition
Jun 05, 2026Code-switching (CS), the alternation between multiple languages within a single utterance, remains challenging for Automatic Speech Recognition (ASR). To address this issue, we propose a Point-of-Interest (POI)-aware contrastive training framework that improves recognition at CS-critical regions. We first identify CS spans by adopting POI detection method from literature, then construct acoustically plausible near-miss hypotheses by perturbing POIs in ASR N-best outputs and expanding candidates with a large language model. Hard but plausible negatives are retained through filtering with acoustic, phonemic, and textual constraints. Finally, we fine-tune Whisper-small with LoRA using a POI-weighted cross-entropy anchor objective together with a multi-negative contrastive ranking loss. Experiments on CS-FLEURS (cmn-eng) and ViMedCSS (vie-eng) show consistent reductions of over 2% in both general and CS-aware error rates compared to standard LoRA fine-tuning.
PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
May 27, 2026The rapid growth in submissions to machine learning venues has strained the scientific peer-review system and intensified interest in LLM-based automated peer reviewers. However, how good these systems are actually, especially compared to human reviewers at catching scientific gaps, remains poorly understood. In this work, we introduce PRISM (Peer Review Intelligence via Structured Multi-dimensional assessment), a benchmarking framework that evaluates review quality across four dimensions: Depth of Analysis, Novelty Assessment,Flaw Identification & Major Issues Prioritization, and Multi-dimensional Constructiveness. Unlike most existing evaluations based on surface-level metrics like ROUGE and BLEU, or unconstrained LLM-as-a-judge prompting that conflates fluency with rigor, PRISM grounds each dimension in argument mining, retrieval-augmented verification, and consensus-based scoring. We apply PRISM to benchmark five leading automated reviewer systems and human reviewers on a stratified corpus of reviews from ICLR, ICML, and NeurIPS. The results reveal that LLMs can match or beat human reviewers on individual dimensions: comparable depth of analysis, stronger novelty verification, and highly accurate critique prioritization. However, no single system consistently matches the balanced performance of the human baseline across all dimensions at once. Each exhibits a distinct specialization profile with characteristic blind spots -- failure modes that aggregate metrics miss entirely. The implication is that LLM reviewers are best understood as targeted supplements to human review, effective within specific dimensions, but unreliable as standalone replacements. Our demo and key results can be found at https://khanhthanhdev.github.io/prism-page/.
ViMedCSS: A Vietnamese Medical Code-Switching Speech Dataset & Benchmark
Feb 13, 2026Code-switching (CS), which is when Vietnamese speech uses English words like drug names or procedures, is a common phenomenon in Vietnamese medical communication. This creates challenges for Automatic Speech Recognition (ASR) systems, especially in low-resource languages like Vietnamese. Current most ASR systems struggle to recognize correctly English medical terms within Vietnamese sentences, and no benchmark addresses this challenge. In this paper, we construct a 34-hour \textbf{Vi}etnamese \textbf{Med}ical \textbf{C}ode-\textbf{S}witching \textbf{S}peech dataset (ViMedCSS) containing 16,576 utterances. Each utterance includes at least one English medical term drawn from a curated bilingual lexicon covering five medical topics. Using this dataset, we evaluate several state-of-the-art ASR models and examine different specific fine-tuning strategies for improving medical term recognition to investigate the best approach to solve in the dataset. Experimental results show that Vietnamese-optimized models perform better on general segments, while multilingual pretraining helps capture English insertions. The combination of both approaches yields the best balance between overall and code-switched accuracy. This work provides the first benchmark for Vietnamese medical code-switching and offers insights into effective domain adaptation for low-resource, multilingual ASR systems.
Improving Symbolic Translation of Language Models for Logical Reasoning
Jan 14, 2026The use of formal language for deductive logical reasoning aligns well with language models (LMs), where translating natural language (NL) into first-order logic (FOL) and employing an external solver results in a verifiable and therefore reliable reasoning system. However, smaller LMs often struggle with this translation task, frequently producing incorrect symbolic outputs due to formatting and translation errors. Existing approaches typically rely on self-iteration to correct these errors, but such methods depend heavily on the capabilities of the underlying model. To address this, we first categorize common errors and fine-tune smaller LMs using data synthesized by large language models. The evaluation is performed using the defined error categories. We introduce incremental inference, which divides inference into two stages, predicate generation and FOL translation, providing greater control over model behavior and enhancing generation quality as measured by predicate metrics. This decomposition framework also enables the use of a verification module that targets predicate-arity errors to further improve performance. Our study evaluates three families of models across four logical-reasoning datasets. The comprehensive fine-tuning, incremental inference, and verification modules reduce error rates, increase predicate coverage, and improve reasoning performance for smaller LMs, moving us closer to developing reliable and accessible symbolic-reasoning systems.
Multilingual LLM Prompting Strategies for Medical English-Vietnamese Machine Translation
Sep 19, 2025Medical English-Vietnamese machine translation (En-Vi MT) is essential for healthcare access and communication in Vietnam, yet Vietnamese remains a low-resource and under-studied language. We systematically evaluate prompting strategies for six multilingual LLMs (0.5B-9B parameters) on the MedEV dataset, comparing zero-shot, few-shot, and dictionary-augmented prompting with Meddict, an English-Vietnamese medical lexicon. Results show that model scale is the primary driver of performance: larger LLMs achieve strong zero-shot results, while few-shot prompting yields only marginal improvements. In contrast, terminology-aware cues and embedding-based example retrieval consistently improve domain-specific translation. These findings underscore both the promise and the current limitations of multilingual LLMs for medical En-Vi MT.
Logical Reasoning with Outcome Reward Models for Test-Time Scaling
Aug 27, 2025Logical reasoning is a critical benchmark for evaluating the capabilities of large language models (LLMs), as it reflects their ability to derive valid conclusions from given premises. While the combination of test-time scaling with dedicated outcome or process reward models has opened up new avenues to enhance LLMs performance in complex reasoning tasks, this space is under-explored in deductive logical reasoning. We present a set of Outcome Reward Models (ORMs) for deductive reasoning. To train the ORMs we mainly generate data using Chain-of-Thought (CoT) with single and multiple samples. Additionally, we propose a novel tactic to further expand the type of errors covered in the training dataset of the ORM. In particular, we propose an echo generation technique that leverages LLMs' tendency to reflect incorrect assumptions made in prompts to extract additional training data, covering previously unexplored error types. While a standard CoT chain may contain errors likely to be made by the reasoner, the echo strategy deliberately steers the model toward incorrect reasoning. We show that ORMs trained on CoT and echo-augmented data demonstrate improved performance on the FOLIO, JustLogic, and ProverQA datasets across four different LLMs.
ALScope: A Unified Toolkit for Deep Active Learning
Aug 06, 2025Deep Active Learning (DAL) reduces annotation costs by selecting the most informative unlabeled samples during training. As real-world applications become more complex, challenges stemming from distribution shifts (e.g., open-set recognition) and data imbalance have gained increasing attention, prompting the development of numerous DAL algorithms. However, the lack of a unified platform has hindered fair and systematic evaluation under diverse conditions. Therefore, we present a new DAL platform ALScope for classification tasks, integrating 10 datasets from computer vision (CV) and natural language processing (NLP), and 21 representative DAL algorithms, including both classical baselines and recent approaches designed to handle challenges such as distribution shifts and data imbalance. This platform supports flexible configuration of key experimental factors, ranging from algorithm and dataset choices to task-specific factors like out-of-distribution (OOD) sample ratio, and class imbalance ratio, enabling comprehensive and realistic evaluation. We conduct extensive experiments on this platform under various settings. Our findings show that: (1) DAL algorithms' performance varies significantly across domains and task settings; (2) in non-standard scenarios such as imbalanced and open-set settings, DAL algorithms show room for improvement and require further investigation; and (3) some algorithms achieve good performance, but require significantly longer selection time.
MoTime: A Dataset Suite for Multimodal Time Series Forecasting
May 21, 2025While multimodal data sources are increasingly available from real-world forecasting, most existing research remains on unimodal time series. In this work, we present MoTime, a suite of multimodal time series forecasting datasets that pair temporal signals with external modalities such as text, metadata, and images. Covering diverse domains, MoTime supports structured evaluation of modality utility under two scenarios: 1) the common forecasting task, where varying-length history is available, and 2) cold-start forecasting, where no historical data is available. Experiments show that external modalities can improve forecasting performance in both scenarios, with particularly strong benefits for short series in some datasets, though the impact varies depending on data characteristics. By making datasets and findings publicly available, we aim to support more comprehensive and realistic benchmarks in future multimodal time series forecasting research.
VerifiAgent: a Unified Verification Agent in Language Model Reasoning
Apr 01, 2025
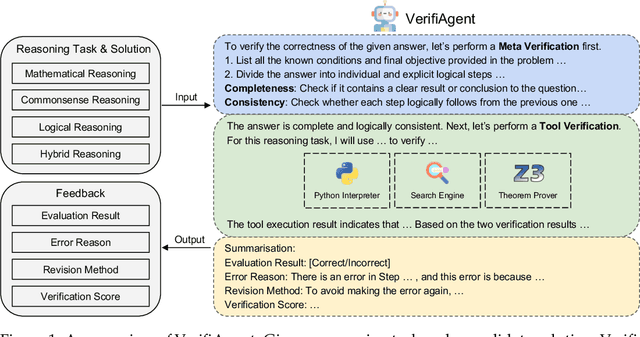
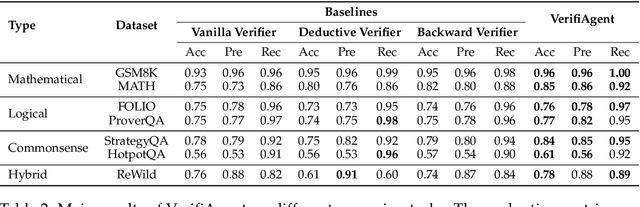
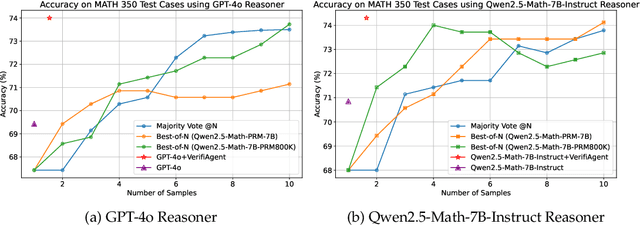
Large language models demonstrate remarkable reasoning capabilities but often produce unreliable or incorrect responses. Existing verification methods are typically model-specific or domain-restricted, requiring significant computational resources and lacking scalability across diverse reasoning tasks. To address these limitations, we propose VerifiAgent, a unified verification agent that integrates two levels of verification: meta-verification, which assesses completeness and consistency in model responses, and tool-based adaptive verification, where VerifiAgent autonomously selects appropriate verification tools based on the reasoning type, including mathematical, logical, or commonsense reasoning. This adaptive approach ensures both efficiency and robustness across different verification scenarios. Experimental results show that VerifiAgent outperforms baseline verification methods (e.g., deductive verifier, backward verifier) among all reasoning tasks. Additionally, it can further enhance reasoning accuracy by leveraging feedback from verification results. VerifiAgent can also be effectively applied to inference scaling, achieving better results with fewer generated samples and costs compared to existing process reward models in the mathematical reasoning domain. Code is available at https://github.com/Jiuzhouh/VerifiAgent