 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKolmogorov-Arnold Attention: Is Learnable Attention Better For Vision Transformers?
Mar 13, 2025



Kolmogorov-Arnold networks (KANs) are a remarkable innovation consisting of learnable activation functions with the potential to capture more complex relationships from data. Although KANs are useful in finding symbolic representations and continual learning of one-dimensional functions, their effectiveness in diverse machine learning (ML) tasks, such as vision, remains questionable. Presently, KANs are deployed by replacing multilayer perceptrons (MLPs) in deep network architectures, including advanced architectures such as vision Transformers (ViTs). In this paper, we are the first to design a general learnable Kolmogorov-Arnold Attention (KArAt) for vanilla ViTs that can operate on any choice of basis. However, the computing and memory costs of training them motivated us to propose a more modular version, and we designed particular learnable attention, called Fourier-KArAt. Fourier-KArAt and its variants either outperform their ViT counterparts or show comparable performance on CIFAR-10, CIFAR-100, and ImageNet-1K datasets. We dissect these architectures' performance and generalization capacity by analyzing their loss landscapes, weight distributions, optimizer path, attention visualization, and spectral behavior, and contrast them with vanilla ViTs. The goal of this paper is not to produce parameter- and compute-efficient attention, but to encourage the community to explore KANs in conjunction with more advanced architectures that require a careful understanding of learnable activations. Our open-source code and implementation details are available on: https://subhajitmaity.me/KArAt
A Survey on Enhancing Causal Reasoning Ability of Large Language Models
Mar 12, 2025Large language models (LLMs) have recently shown remarkable performance in language tasks and beyond. However, due to their limited inherent causal reasoning ability, LLMs still face challenges in handling tasks that require robust causal reasoning ability, such as health-care and economic analysis. As a result, a growing body of research has focused on enhancing the causal reasoning ability of LLMs. Despite the booming research, there lacks a survey to well review the challenges, progress and future directions in this area. To bridge this significant gap, we systematically review literature on how to strengthen LLMs' causal reasoning ability in this paper. We start from the introduction of background and motivations of this topic, followed by the summarisation of key challenges in this area. Thereafter, we propose a novel taxonomy to systematically categorise existing methods, together with detailed comparisons within and between classes of methods. Furthermore, we summarise existing benchmarks and evaluation metrics for assessing LLMs' causal reasoning ability. Finally, we outline future research directions for this emerging field, offering insights and inspiration to researchers and practitioners in the area.
Symbolic Neural Ordinary Differential Equations
Mar 11, 2025



Differential equations are widely used to describe complex dynamical systems with evolving parameters in nature and engineering. Effectively learning a family of maps from the parameter function to the system dynamics is of great significance. In this study, we propose a novel learning framework of symbolic continuous-depth neural networks, termed Symbolic Neural Ordinary Differential Equations (SNODEs), to effectively and accurately learn the underlying dynamics of complex systems. Specifically, our learning framework comprises three stages: initially, pre-training a predefined symbolic neural network via a gradient flow matching strategy; subsequently, fine-tuning this network using Neural ODEs; and finally, constructing a general neural network to capture residuals. In this process, we apply the SNODEs framework to partial differential equation systems through Fourier analysis, achieving resolution-invariant modeling. Moreover, this framework integrates the strengths of symbolism and connectionism, boasting a universal approximation theorem while significantly enhancing interpretability and extrapolation capabilities relative to state-of-the-art baseline methods. We demonstrate this through experiments on several representative complex systems. Therefore, our framework can be further applied to a wide range of scientific problems, such as system bifurcation and control, reconstruction and forecasting, as well as the discovery of new equations.
A Zero-shot Learning Method Based on Large Language Models for Multi-modal Knowledge Graph Embedding
Mar 10, 2025



Zero-shot learning (ZL) is crucial for tasks involving unseen categories, such as natural language processing, image classification, and cross-lingual transfer. Current applications often fail to accurately infer and handle new relations or entities involving unseen categories, severely limiting their scalability and practicality in open-domain scenarios. ZL learning faces the challenge of effectively transferring semantic information of unseen categories in multi-modal knowledge graph (MMKG) embedding representation learning. In this paper, we propose ZSLLM, a framework for zero-shot embedding learning of MMKGs using large language models (LLMs). We leverage textual modality information of unseen categories as prompts to fully utilize the reasoning capabilities of LLMs, enabling semantic information transfer across different modalities for unseen categories. Through model-based learning, the embedding representation of unseen categories in MMKG is enhanced. Extensive experiments conducted on multiple real-world datasets demonstrate the superiority of our approach compared to state-of-the-art methods.
Controllable 3D Outdoor Scene Generation via Scene Graphs
Mar 10, 2025Three-dimensional scene generation is crucial in computer vision, with applications spanning autonomous driving, gaming and the metaverse. Current methods either lack user control or rely on imprecise, non-intuitive conditions. In this work, we propose a method that uses, scene graphs, an accessible, user friendly control format to generate outdoor 3D scenes. We develop an interactive system that transforms a sparse scene graph into a dense BEV (Bird's Eye View) Embedding Map, which guides a conditional diffusion model to generate 3D scenes that match the scene graph description. During inference, users can easily create or modify scene graphs to generate large-scale outdoor scenes. We create a large-scale dataset with paired scene graphs and 3D semantic scenes to train the BEV embedding and diffusion models. Experimental results show that our approach consistently produces high-quality 3D urban scenes closely aligned with the input scene graphs. To the best of our knowledge, this is the first approach to generate 3D outdoor scenes conditioned on scene graphs.
Seesaw: High-throughput LLM Inference via Model Re-sharding
Mar 09, 2025To improve the efficiency of distributed large language model (LLM) inference, various parallelization strategies, such as tensor and pipeline parallelism, have been proposed. However, the distinct computational characteristics inherent in the two stages of LLM inference-prefilling and decoding-render a single static parallelization strategy insufficient for the effective optimization of both stages. In this work, we present Seesaw, an LLM inference engine optimized for throughput-oriented tasks. The key idea behind Seesaw is dynamic model re-sharding, a technique that facilitates the dynamic reconfiguration of parallelization strategies across stages, thereby maximizing throughput at both phases. To mitigate re-sharding overhead and optimize computational efficiency, we employ tiered KV cache buffering and transition-minimizing scheduling. These approaches work synergistically to reduce the overhead caused by frequent stage transitions while ensuring maximum batching efficiency. Our evaluation demonstrates that Seesaw achieves a throughput increase of up to 1.78x (1.36x on average) compared to vLLM, the most widely used state-of-the-art LLM inference engine.
A Novel Trustworthy Video Summarization Algorithm Through a Mixture of LoRA Experts
Mar 08, 2025With the exponential growth of user-generated content on video-sharing platforms, the challenge of facilitating efficient searching and browsing of videos has garnered significant attention. To enhance users' ability to swiftly locate and review pertinent videos, the creation of concise and informative video summaries has become increasingly important. Video-llama is an effective tool for generating video summarization, but it cannot effectively unify and optimize the modeling of temporal and spatial features and requires a lot of computational resources and time. Therefore, we propose MiLoRA-ViSum to more efficiently capture complex temporal dynamics and spatial relationships inherent in video data and to control the number of parameters for training. By extending traditional Low-Rank Adaptation (LoRA) into a sophisticated mixture-of-experts paradigm, MiLoRA-ViSum incorporates a dual temporal-spatial adaptation mechanism tailored specifically for video summarization tasks. This approach dynamically integrates specialized LoRA experts, each fine-tuned to address distinct temporal or spatial dimensions. Extensive evaluations of the VideoXum and ActivityNet datasets demonstrate that MiLoRA-ViSum achieves the best summarization performance compared to state-of-the-art models, while maintaining significantly lower computational costs. The proposed mixture-of-experts strategy, combined with the dual adaptation mechanism, highlights the model's potential to enhance video summarization capabilities, particularly in large-scale applications requiring both efficiency and precision.
RetinalGPT: A Retinal Clinical Preference Conversational Assistant Powered by Large Vision-Language Models
Mar 06, 2025Recently, Multimodal Large Language Models (MLLMs) have gained significant attention for their remarkable ability to process and analyze non-textual data, such as images, videos, and audio. Notably, several adaptations of general-domain MLLMs to the medical field have been explored, including LLaVA-Med. However, these medical adaptations remain insufficiently advanced in understanding and interpreting retinal images. In contrast, medical experts emphasize the importance of quantitative analyses for disease detection and interpretation. This underscores a gap between general-domain and medical-domain MLLMs: while general-domain MLLMs excel in broad applications, they lack the specialized knowledge necessary for precise diagnostic and interpretative tasks in the medical field. To address these challenges, we introduce \textit{RetinalGPT}, a multimodal conversational assistant for clinically preferred quantitative analysis of retinal images. Specifically, we achieve this by compiling a large retinal image dataset, developing a novel data pipeline, and employing customized visual instruction tuning to enhance both retinal analysis and enrich medical knowledge. In particular, RetinalGPT outperforms MLLM in the generic domain by a large margin in the diagnosis of retinal diseases in 8 benchmark retinal datasets. Beyond disease diagnosis, RetinalGPT features quantitative analyses and lesion localization, representing a pioneering step in leveraging LLMs for an interpretable and end-to-end clinical research framework. The code is available at https://github.com/Retinal-Research/RetinalGPT
Q&C: When Quantization Meets Cache in Efficient Image Generation
Mar 04, 2025



Quantization and cache mechanisms are typically applied individually for efficient Diffusion Transformers (DiTs), each demonstrating notable potential for acceleration. However, the promoting effect of combining the two mechanisms on efficient generation remains under-explored. Through empirical investigation, we find that the combination of quantization and cache mechanisms for DiT is not straightforward, and two key challenges lead to severe catastrophic performance degradation: (i) the sample efficacy of calibration datasets in post-training quantization (PTQ) is significantly eliminated by cache operation; (ii) the combination of the above mechanisms introduces more severe exposure bias within sampling distribution, resulting in amplified error accumulation in the image generation process. In this work, we take advantage of these two acceleration mechanisms and propose a hybrid acceleration method by tackling the above challenges, aiming to further improve the efficiency of DiTs while maintaining excellent generation capability. Concretely, a temporal-aware parallel clustering (TAP) is designed to dynamically improve the sample selection efficacy for the calibration within PTQ for different diffusion steps. A variance compensation (VC) strategy is derived to correct the sampling distribution. It mitigates exposure bias through an adaptive correction factor generation. Extensive experiments have shown that our method has accelerated DiTs by 12.7x while preserving competitive generation capability. The code will be available at https://github.com/xinding-sys/Quant-Cache.
CADDreamer: CAD object Generation from Single-view Images
Feb 28, 2025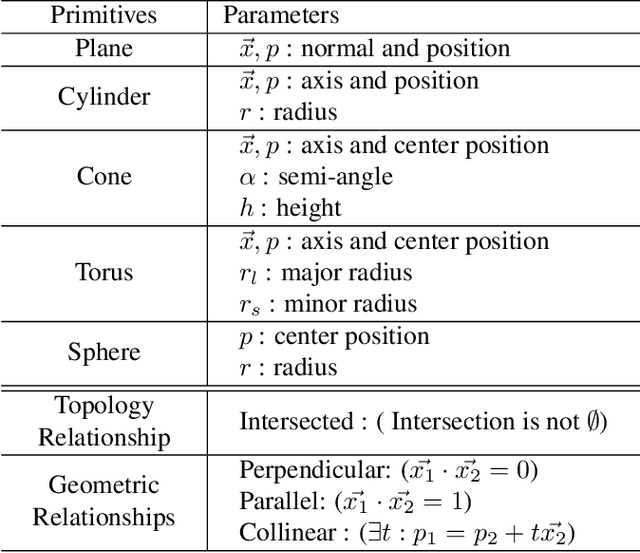
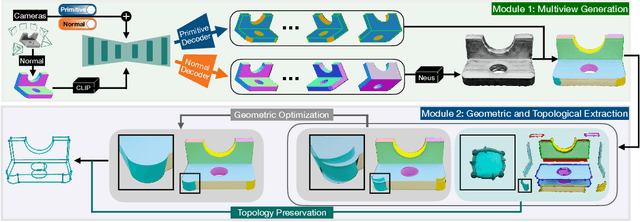

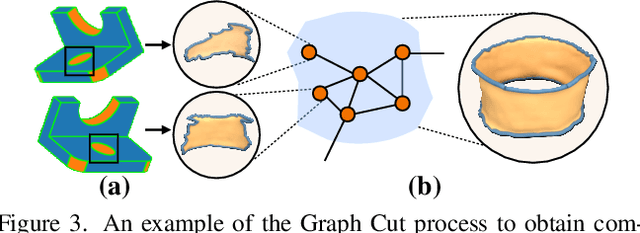
Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.