 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniRoam: World Wandering via Long-Horizon Panoramic Video Generation
Mar 31, 2026Modeling scenes using video generation models has garnered growing research interest in recent years. However, most existing approaches rely on perspective video models that synthesize only limited observations of a scene, leading to issues of completeness and global consistency. We propose OmniRoam, a controllable panoramic video generation framework that exploits the rich per-frame scene coverage and inherent long-term spatial and temporal consistency of panoramic representation, enabling long-horizon scene wandering. Our framework begins with a preview stage, where a trajectory-controlled video generation model creates a quick overview of the scene from a given input image or video. Then, in the refine stage, this video is temporally extended and spatially upsampled to produce long-range, high-resolution videos, thus enabling high-fidelity world wandering. To train our model, we introduce two panoramic video datasets that incorporate both synthetic and real-world captured videos. Experiments show that our framework consistently outperforms state-of-the-art methods in terms of visual quality, controllability, and long-term scene consistency, both qualitatively and quantitatively. We further showcase several extensions of this framework, including real-time video generation and 3D reconstruction. Code is available at https://github.com/yuhengliu02/OmniRoam.
Data-Chain Backdoor: Do You Trust Diffusion Models as Generative Data Supplier?
Dec 12, 2025The increasing use of generative models such as diffusion models for synthetic data augmentation has greatly reduced the cost of data collection and labeling in downstream perception tasks. However, this new data source paradigm may introduce important security concerns. This work investigates backdoor propagation in such emerging generative data supply chains, namely Data-Chain Backdoor (DCB). Specifically, we find that open-source diffusion models can become hidden carriers of backdoors. Their strong distribution-fitting ability causes them to memorize and reproduce backdoor triggers during generation, which are subsequently inherited by downstream models, resulting in severe security risks. This threat is particularly concerning under clean-label attack scenarios, as it remains effective while having negligible impact on the utility of the synthetic data. Furthermore, we discover an Early-Stage Trigger Manifestation (ESTM) phenomenon: backdoor trigger patterns tend to surface more explicitly in the early, high-noise stages of the diffusion model's reverse generation process before being subtly integrated into the final samples. Overall, this work reveals a previously underexplored threat in generative data pipelines and provides initial insights toward mitigating backdoor risks in synthetic data generation.
Ignoring Directionality Leads to Compromised Graph Neural Network Explanations
Jun 05, 2025Graph Neural Networks (GNNs) are increasingly used in critical domains, where reliable explanations are vital for supporting human decision-making. However, the common practice of graph symmetrization discards directional information, leading to significant information loss and misleading explanations. Our analysis demonstrates how this practice compromises explanation fidelity. Through theoretical and empirical studies, we show that preserving directional semantics significantly improves explanation quality, ensuring more faithful insights for human decision-makers. These findings highlight the need for direction-aware GNN explainability in security-critical applications.
Rethinking Gradient-based Adversarial Attacks on Point Cloud Classification
May 28, 2025Gradient-based adversarial attacks have become a dominant approach for evaluating the robustness of point cloud classification models. However, existing methods often rely on uniform update rules that fail to consider the heterogeneous nature of point clouds, resulting in excessive and perceptible perturbations. In this paper, we rethink the design of gradient-based attacks by analyzing the limitations of conventional gradient update mechanisms and propose two new strategies to improve both attack effectiveness and imperceptibility. First, we introduce WAAttack, a novel framework that incorporates weighted gradients and an adaptive step-size strategy to account for the non-uniform contribution of points during optimization. This approach enables more targeted and subtle perturbations by dynamically adjusting updates according to the local structure and sensitivity of each point. Second, we propose SubAttack, a complementary strategy that decomposes the point cloud into subsets and focuses perturbation efforts on structurally critical regions. Together, these methods represent a principled rethinking of gradient-based adversarial attacks for 3D point cloud classification. Extensive experiments demonstrate that our approach outperforms state-of-the-art baselines in generating highly imperceptible adversarial examples. Code will be released upon paper acceptance.
Causal Self-supervised Pretrained Frontend with Predictive Code for Speech Separation
Apr 03, 2025



Speech separation (SS) seeks to disentangle a multi-talker speech mixture into single-talker speech streams. Although SS can be generally achieved using offline methods, such a processing paradigm is not suitable for real-time streaming applications. Causal separation models, which rely only on past and present information, offer a promising solution for real-time streaming. However, these models typically suffer from notable performance degradation due to the absence of future context. In this paper, we introduce a novel frontend that is designed to mitigate the mismatch between training and run-time inference by implicitly incorporating future information into causal models through predictive patterns. The pretrained frontend employs a transformer decoder network with a causal convolutional encoder as the backbone and is pretrained in a self-supervised manner with two innovative pretext tasks: autoregressive hybrid prediction and contextual knowledge distillation. These tasks enable the model to capture predictive patterns directly from mixtures in a self-supervised manner. The pretrained frontend subsequently serves as a feature extractor to generate high-quality predictive patterns. Comprehensive evaluations on synthetic and real-world datasets validated the effectiveness of the proposed pretrained frontend.
Controllable 3D Outdoor Scene Generation via Scene Graphs
Mar 10, 2025Three-dimensional scene generation is crucial in computer vision, with applications spanning autonomous driving, gaming and the metaverse. Current methods either lack user control or rely on imprecise, non-intuitive conditions. In this work, we propose a method that uses, scene graphs, an accessible, user friendly control format to generate outdoor 3D scenes. We develop an interactive system that transforms a sparse scene graph into a dense BEV (Bird's Eye View) Embedding Map, which guides a conditional diffusion model to generate 3D scenes that match the scene graph description. During inference, users can easily create or modify scene graphs to generate large-scale outdoor scenes. We create a large-scale dataset with paired scene graphs and 3D semantic scenes to train the BEV embedding and diffusion models. Experimental results show that our approach consistently produces high-quality 3D urban scenes closely aligned with the input scene graphs. To the best of our knowledge, this is the first approach to generate 3D outdoor scenes conditioned on scene graphs.
Speech Separation with Pretrained Frontend to Minimize Domain Mismatch
Nov 05, 2024



Speech separation seeks to separate individual speech signals from a speech mixture. Typically, most separation models are trained on synthetic data due to the unavailability of target reference in real-world cocktail party scenarios. As a result, there exists a domain gap between real and synthetic data when deploying speech separation models in real-world applications. In this paper, we propose a self-supervised domain-invariant pretrained (DIP) frontend that is exposed to mixture data without the need for target reference speech. The DIP frontend utilizes a Siamese network with two innovative pretext tasks, mixture predictive coding (MPC) and mixture invariant coding (MIC), to capture shared contextual cues between real and synthetic unlabeled mixtures. Subsequently, we freeze the DIP frontend as a feature extractor when training the downstream speech separation models on synthetic data. By pretraining the DIP frontend with the contextual cues, we expect that the speech separation skills learned from synthetic data can be effectively transferred to real data. To benefit from the DIP frontend, we introduce a novel separation pipeline to align the feature resolution of the separation models. We evaluate the speech separation quality on standard benchmarks and real-world datasets. The results confirm the superiority of our DIP frontend over existing speech separation models. This study underscores the potential of large-scale pretraining to enhance the quality and intelligibility of speech separation in real-world applications.
* IEEE/ACM Transactions on Audio, Speech, and Language Processing
Enhancing Sampling Protocol for Robust Point Cloud Classification
Aug 22, 2024Established sampling protocols for 3D point cloud learning, such as Farthest Point Sampling (FPS) and Fixed Sample Size (FSS), have long been recognized and utilized. However, real-world data often suffer from corrputions such as sensor noise, which violates the benignness assumption of point cloud in current protocols. Consequently, they are notably vulnerable to noise, posing significant safety risks in critical applications like autonomous driving. To address these issues, we propose an enhanced point cloud sampling protocol, PointDR, which comprises two components: 1) Downsampling for key point identification and 2) Resampling for flexible sample size. Furthermore, differentiated strategies are implemented for training and inference processes. Particularly, an isolation-rated weight considering local density is designed for the downsampling method, assisting it in performing random key points selection in the training phase and bypassing noise in the inference phase. A local-geometry-preserved upsampling is incorporated into resampling, facilitating it to maintain a stochastic sample size in the training stage and complete insufficient data in the inference. It is crucial to note that the proposed protocol is free of model architecture altering and extra learning, thus minimal efforts are demanded for its replacement of the existing one. Despite the simplicity, it substantially improves the robustness of point cloud learning, showcased by outperforming the state-of-the-art methods on multiple benchmarks of corrupted point cloud classification. The code will be available upon the paper's acceptance.
Pyramid Diffusion for Fine 3D Large Scene Generation
Nov 20, 2023
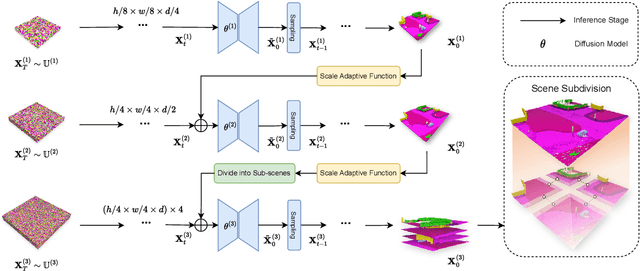
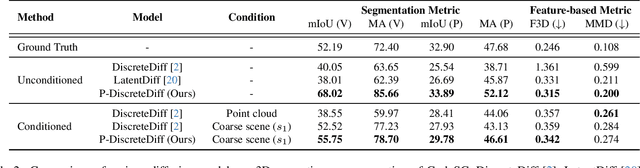

Directly transferring the 2D techniques to 3D scene generation is challenging due to significant resolution reduction and the scarcity of comprehensive real-world 3D scene datasets. To address these issues, our work introduces the Pyramid Discrete Diffusion model (PDD) for 3D scene generation. This novel approach employs a multi-scale model capable of progressively generating high-quality 3D scenes from coarse to fine. In this way, the PDD can generate high-quality scenes within limited resource constraints and does not require additional data sources. To the best of our knowledge, we are the first to adopt the simple but effective coarse-to-fine strategy for 3D large scene generation. Our experiments, covering both unconditional and conditional generation, have yielded impressive results, showcasing the model's effectiveness and robustness in generating realistic and detailed 3D scenes. Our code will be available to the public.
Gradient-based adaptive wavelet de-noising method for photoacoustic imaging in vivo
Jul 25, 2023Photoacoustic imaging (PAI) has been applied to many biomedical applications over the past decades. However, the received PA signal usually suffers from poor signal-to-noise ratio (SNR). Conventional solution of employing higher-power laser, or doing long-time signal averaging, may raise the system cost, time consumption, and tissue damage. Another strategy is de-noising algorithm design. In this paper, we propose a new de-noising method, termed gradient-based adaptive wavelet de-noising, which sets the energy gradient mutation point of low-frequency wavelet components as the threshold. We conducted simulation, ex vivo and in vivo experiments to validate the performance of the algorithm. The quality of de-noised PA image/signal by our proposed algorithm has improved by 20%-40%, in comparison to the traditional signal denoising algorithms, which produces better contrast and clearer details. The proposed de-noising method provides potential to improve the SNR of PA signal under single-shot low-power laser illumination for biomedical applications in vivo.