 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Intent Reasoning: Bringing LLM Semantics to Industrial Cross-Domain Recommendations
Jun 09, 2026Cross-domain recommendation is a core problem in content-to-e-commerce platforms. Its objective is to leverage user interactions with content to infer potential purchasing intent on the e-commerce side, thereby enhancing conversion rates and commercial value. However, in real industrial scenarios, cross-domain recommendation faces multiple challenges: significant semantic gaps exist between different domains, and user cross-domain behavior sequences are often massive in scale and rich in noise. Although large language models (LLMs) possess powerful semantic understanding and reasoning capabilities, their millisecond-level inference latency makes direct application in online recommendation systems difficult. To address these issues, this paper introduces AIR (Atomic Intent Reasoning), an LLM-driven cross-domain recommendation framework designed for industrial-grade deployment. By migrating LLM inference to the offline phase and dynamically constructing user intent representations through efficient retrieval and composition during online operations, it achieves approximately 400* inference acceleration while maintaining semantic consistency. Experimental results across multiple public datasets demonstrate that our method achieves state-of-the-art performance in cross-domain recommendation tasks. Furthermore, large-scale online A/B testing conducted in Kuaishou E-commerce's real-world business scenarios shows that our approach delivers stable and significant improvements across multiple core business metrics, including a +3.446% increase in GMV, fully validating its effectiveness and practical value in industrial-scale recommendation systems.
Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language Translation
Apr 16, 2026Many SLT systems quietly assume that brief chunks of signing map directly to spoken-language words. That assumption breaks down because signers often create meaning on the fly using context, space, and movement. We revisit SLT and argue that it is mainly a cross-modal reasoning task, not just a straightforward video-to-text conversion. We thus introduce a reasoning-driven SLT framework that uses an ordered sequence of latent thoughts as an explicit middle layer between the video and the generated text. These latent thoughts gradually extract and organize meaning over time. On top of this, we use a plan-then-ground decoding method: the model first decides what it wants to say, and then looks back at the video to find the evidence. This separation improves coherence and faithfulness. We also built and released a new large-scale gloss-free SLT dataset with stronger context dependencies and more realistic meanings. Experiments across several benchmarks show consistent gains over existing gloss-free methods. Code and data will be released upon acceptance at https://github.com/fletcherjiang/SignThought.
Train at Moving Edge: Online-Verified Prompt Selection for Efficient RL Training of Large Reasoning Model
Mar 26, 2026Reinforcement learning (RL) has become essential for post-training large language models (LLMs) in reasoning tasks. While scaling rollouts can stabilize training and enhance performance, the computational overhead is a critical issue. In algorithms like GRPO, multiple rollouts per prompt incur prohibitive costs, as a large portion of prompts provide negligible gradients and are thus of low utility. To address this problem, we investigate how to select high-utility prompts before the rollout phase. Our experimental analysis reveals that sample utility is non-uniform and evolving: the strongest learning signals concentrate at the ``learning edge", the intersection of intermediate difficulty and high uncertainty, which shifts as training proceeds. Motivated by this, we propose HIVE (History-Informed and online-VErified prompt selection), a dual-stage framework for data-efficient RL. HIVE utilizes historical reward trajectories for coarse selection and employs prompt entropy as a real-time proxy to prune instances with stale utility. By evaluating HIVE across multiple math reasoning benchmarks and models, we show that HIVE yields significant rollout efficiency without compromising performance.
Orchestration-Free Customer Service Automation: A Privacy-Preserving and Flowchart-Guided Framework
Feb 17, 2026Customer service automation has seen growing demand within digital transformation. Existing approaches either rely on modular system designs with extensive agent orchestration or employ over-simplified instruction schemas, providing limited guidance and poor generalizability. This paper introduces an orchestration-free framework using Task-Oriented Flowcharts (TOFs) to enable end-to-end automation without manual intervention. We first define the components and evaluation metrics for TOFs, then formalize a cost-efficient flowchart construction algorithm to abstract procedural knowledge from service dialogues. We emphasize local deployment of small language models and propose decentralized distillation with flowcharts to mitigate data scarcity and privacy issues in model training. Extensive experiments validate the effectiveness in various service tasks, with superior quantitative and application performance compared to strong baselines and market products. By releasing a web-based system demonstration with case studies, we aim to promote streamlined creation of future service automation.
PairEdit: Learning Semantic Variations for Exemplar-based Image Editing
Jun 09, 2025Recent advancements in text-guided image editing have achieved notable success by leveraging natural language prompts for fine-grained semantic control. However, certain editing semantics are challenging to specify precisely using textual descriptions alone. A practical alternative involves learning editing semantics from paired source-target examples. Existing exemplar-based editing methods still rely on text prompts describing the change within paired examples or learning implicit text-based editing instructions. In this paper, we introduce PairEdit, a novel visual editing method designed to effectively learn complex editing semantics from a limited number of image pairs or even a single image pair, without using any textual guidance. We propose a target noise prediction that explicitly models semantic variations within paired images through a guidance direction term. Moreover, we introduce a content-preserving noise schedule to facilitate more effective semantic learning. We also propose optimizing distinct LoRAs to disentangle the learning of semantic variations from content. Extensive qualitative and quantitative evaluations demonstrate that PairEdit successfully learns intricate semantics while significantly improving content consistency compared to baseline methods. Code will be available at https://github.com/xudonmao/PairEdit.
CADReview: Automatically Reviewing CAD Programs with Error Detection and Correction
May 28, 2025Computer-aided design (CAD) is crucial in prototyping 3D objects through geometric instructions (i.e., CAD programs). In practical design workflows, designers often engage in time-consuming reviews and refinements of these prototypes by comparing them with reference images. To bridge this gap, we introduce the CAD review task to automatically detect and correct potential errors, ensuring consistency between the constructed 3D objects and reference images. However, recent advanced multimodal large language models (MLLMs) struggle to recognize multiple geometric components and perform spatial geometric operations within the CAD program, leading to inaccurate reviews. In this paper, we propose the CAD program repairer (ReCAD) framework to effectively detect program errors and provide helpful feedback on error correction. Additionally, we create a dataset, CADReview, consisting of over 20K program-image pairs, with diverse errors for the CAD review task. Extensive experiments demonstrate that our ReCAD significantly outperforms existing MLLMs, which shows great potential in design applications.
MolGround: A Benchmark for Molecular Grounding
Apr 01, 2025Current molecular understanding approaches predominantly focus on the descriptive aspect of human perception, providing broad, topic-level insights. However, the referential aspect -- linking molecular concepts to specific structural components -- remains largely unexplored. To address this gap, we propose a molecular grounding benchmark designed to evaluate a model's referential abilities. We align molecular grounding with established conventions in NLP, cheminformatics, and molecular science, showcasing the potential of NLP techniques to advance molecular understanding within the AI for Science movement. Furthermore, we constructed the largest molecular understanding benchmark to date, comprising 79k QA pairs, and developed a multi-agent grounding prototype as proof of concept. This system outperforms existing models, including GPT-4o, and its grounding outputs have been integrated to enhance traditional tasks such as molecular captioning and ATC (Anatomical, Therapeutic, Chemical) classification.
CSIFT Based Locality-constrained Linear Coding for Image Classification
Sep 28, 2013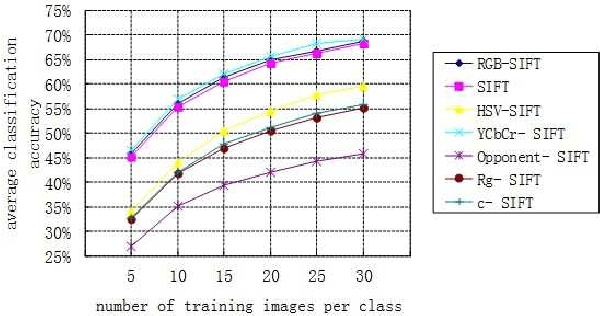
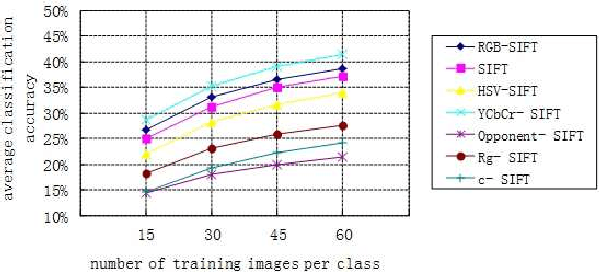
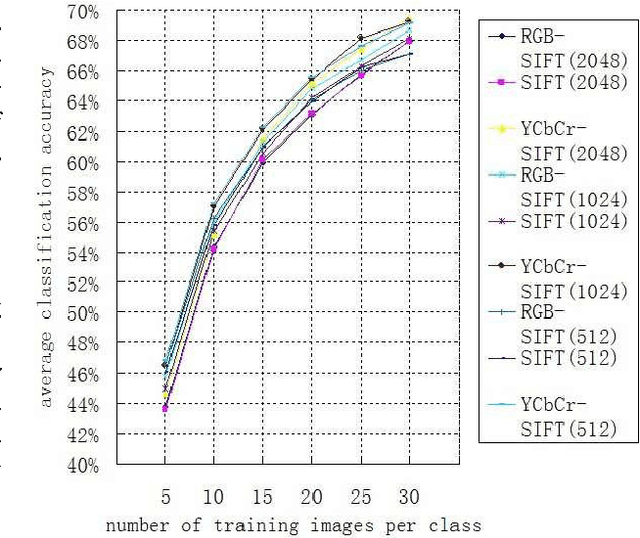
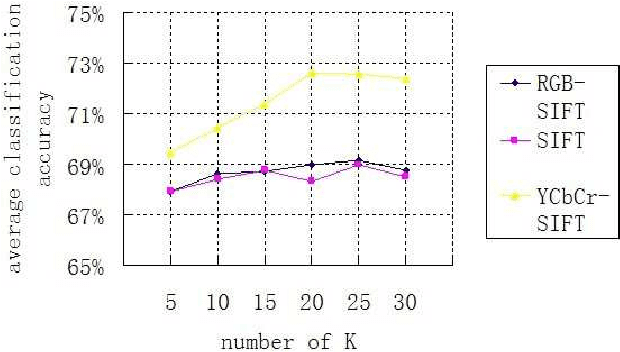
In the past decade, SIFT descriptor has been witnessed as one of the most robust local invariant feature descriptors and widely used in various vision tasks. Most traditional image classification systems depend on the luminance-based SIFT descriptors, which only analyze the gray level variations of the images. Misclassification may happen since their color contents are ignored. In this article, we concentrate on improving the performance of existing image classification algorithms by adding color information. To achieve this purpose, different kinds of colored SIFT descriptors are introduced and implemented. Locality-constrained Linear Coding (LLC), a state-of-the-art sparse coding technology, is employed to construct the image classification system for the evaluation. The real experiments are carried out on several benchmarks. With the enhancements of color SIFT, the proposed image classification system obtains approximate 3% improvement of classification accuracy on the Caltech-101 dataset and approximate 4% improvement of classification accuracy on the Caltech-256 dataset.