 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Equivalence and Learning Dynamics in Delayed MARL
May 05, 2026We formally establish the equivalence between Observation Delay (OD) and Action Delay (AD) in cooperative partially observable multi-agent systems using observation-action histories. We show that both systems generate identical admissible joint-policy sets, and their induced state-action-observation trajectories are identical in distribution, leading to identical optimal solutions in Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs). This formally generalizes existing infinite-horizon single-agent results to any-horizon partially observable cooperative multi-agent problems with decentralized policy execution, and allows any mixed-delay configuration to be reduced to a pure OD system. We further prove that in Transition-Independent MDPs (TI-MDPs), the observation-action history reduces to a tractable minimal local augmented state. However, we show through numerical experiments that although the optimal solution spaces are structurally isomorphic, the practical learning dynamics are fundamentally different. First, using the minimal local augmented state, the equivalence no longer holds when transitions are not independent. Second, operational constraints and causal credit-assignment errors in Temporal Difference (TD) algorithms induce different learning behaviors across regimes. Finally, leveraging this structural equivalence to bypass these learning challenges, we demonstrate successful multi-agent zero-shot policy transfer from OD to AD, paving the way for unified, efficient solution methods in complex delayed systems.
Reinforcement Learning and Regret Bounds for Admission Control
Jun 07, 2024The expected regret of any reinforcement learning algorithm is lower bounded by $\Omega\left(\sqrt{DXAT}\right)$ for undiscounted returns, where $D$ is the diameter of the Markov decision process, $X$ the size of the state space, $A$ the size of the action space and $T$ the number of time steps. However, this lower bound is general. A smaller regret can be obtained by taking into account some specific knowledge of the problem structure. In this article, we consider an admission control problem to an $M/M/c/S$ queue with $m$ job classes and class-dependent rewards and holding costs. Queuing systems often have a diameter that is exponential in the buffer size $S$, making the previous lower bound prohibitive for any practical use. We propose an algorithm inspired by UCRL2, and use the structure of the problem to upper bound the expected total regret by $O(S\log T + \sqrt{mT \log T})$ in the finite server case. In the infinite server case, we prove that the dependence of the regret on $S$ disappears.
Deep learning-based person re-identification methods: A survey and outlook of recent works
Oct 16, 2021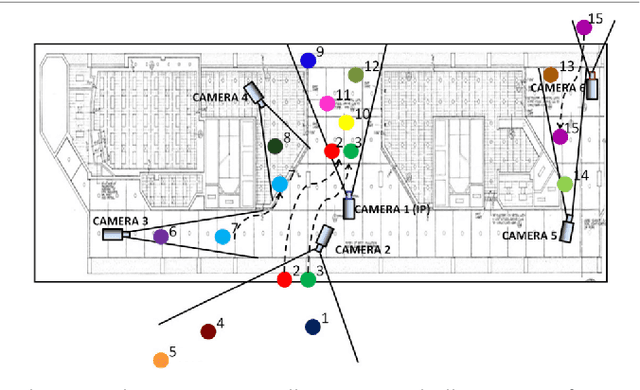
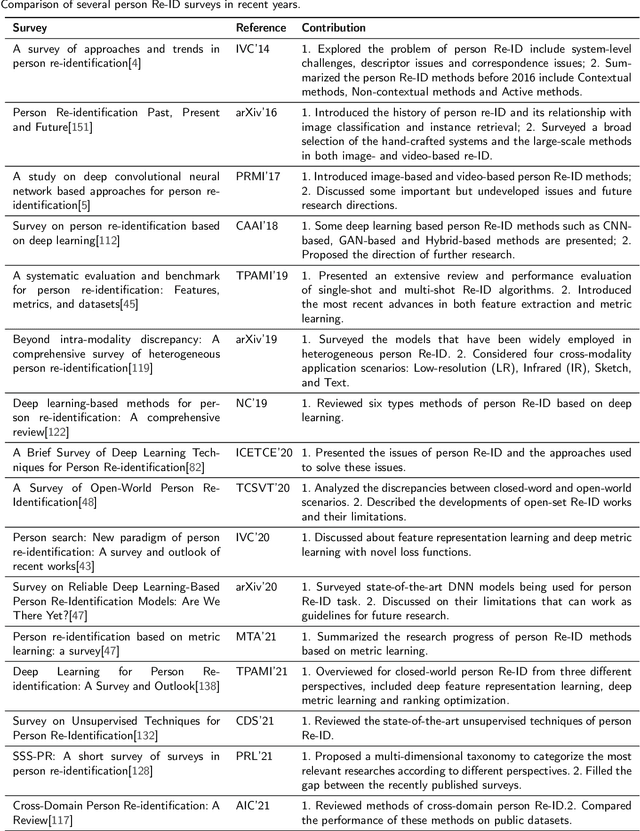
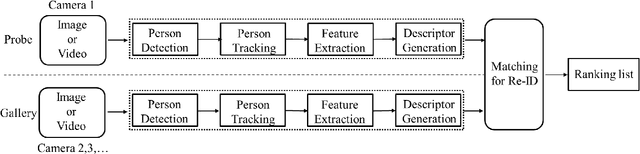

In recent years, with the increasing demand for public safety and the rapid development of intelligent surveillance networks, person re-identification (Re-ID) has become one of the hot research topics in the field of computer vision. The main research goal of person Re-ID is to retrieve persons with the same identity from different cameras. However, traditional person Re-ID methods require manual marking of person targets, which consumes a lot of labor cost. With the widespread application of deep neural networks in the field of computer vision, a large number of deep learning-based person Re-ID methods have emerged. Therefore, this paper is to facilitate researchers to better understand the latest research results and the future trends in the field. Firstly, we summarize the main study of several recently published person re-identification surveys and try to fill the gaps between them. Secondly, We propose a multi-dimensional taxonomy to categorize the most current deep learning-based person Re-ID methods according to different characteristics, including methods for deep metric learning, local feature learning, generate adversarial networks, sequence feature learning and graph convolutional networks. Furthermore, we subdivide the above five categories according to their technique types, discussing and comparing the experimental performance of part subcategories. Finally, we conclude this paper and discuss future research directions for person Re-ID.