 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquisition through My Eyes and Steps: A Joint Predictive Agent Model in Egocentric Worlds
Feb 09, 2025This paper addresses the task of learning an agent model behaving like humans, which can jointly perceive, predict, and act in egocentric worlds. Previous methods usually train separate models for these three abilities, leading to information silos among them, which prevents these abilities from learning from each other and collaborating effectively. In this paper, we propose a joint predictive agent model, named EgoAgent, that simultaneously learns to represent the world, predict future states, and take reasonable actions with a single transformer. EgoAgent unifies the representational spaces of the three abilities by mapping them all into a sequence of continuous tokens. Learnable query tokens are appended to obtain current states, future states, and next actions. With joint supervision, our agent model establishes the internal relationship among these three abilities and effectively mimics the human inference and learning processes. Comprehensive evaluations of EgoAgent covering image classification, egocentric future state prediction, and 3D human motion prediction tasks demonstrate the superiority of our method. The code and trained model will be released for reproducibility.
MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training
Jan 13, 2025



Image matching, which aims to identify corresponding pixel locations between images, is crucial in a wide range of scientific disciplines, aiding in image registration, fusion, and analysis. In recent years, deep learning-based image matching algorithms have dramatically outperformed humans in rapidly and accurately finding large amounts of correspondences. However, when dealing with images captured under different imaging modalities that result in significant appearance changes, the performance of these algorithms often deteriorates due to the scarcity of annotated cross-modal training data. This limitation hinders applications in various fields that rely on multiple image modalities to obtain complementary information. To address this challenge, we propose a large-scale pre-training framework that utilizes synthetic cross-modal training signals, incorporating diverse data from various sources, to train models to recognize and match fundamental structures across images. This capability is transferable to real-world, unseen cross-modality image matching tasks. Our key finding is that the matching model trained with our framework achieves remarkable generalizability across more than eight unseen cross-modality registration tasks using the same network weight, substantially outperforming existing methods, whether designed for generalization or tailored for specific tasks. This advancement significantly enhances the applicability of image matching technologies across various scientific disciplines and paves the way for new applications in multi-modality human and artificial intelligence analysis and beyond.
LiDAR-RT: Gaussian-based Ray Tracing for Dynamic LiDAR Re-simulation
Dec 19, 2024



This paper targets the challenge of real-time LiDAR re-simulation in dynamic driving scenarios. Recent approaches utilize neural radiance fields combined with the physical modeling of LiDAR sensors to achieve high-fidelity re-simulation results. Unfortunately, these methods face limitations due to high computational demands in large-scale scenes and cannot perform real-time LiDAR rendering. To overcome these constraints, we propose LiDAR-RT, a novel framework that supports real-time, physically accurate LiDAR re-simulation for driving scenes. Our primary contribution is the development of an efficient and effective rendering pipeline, which integrates Gaussian primitives and hardware-accelerated ray tracing technology. Specifically, we model the physical properties of LiDAR sensors using Gaussian primitives with learnable parameters and incorporate scene graphs to handle scene dynamics. Building upon this scene representation, our framework first constructs a bounding volume hierarchy (BVH), then casts rays for each pixel and generates novel LiDAR views through a differentiable rendering algorithm. Importantly, our framework supports realistic rendering with flexible scene editing operations and various sensor configurations. Extensive experiments across multiple public benchmarks demonstrate that our method outperforms state-of-the-art methods in terms of rendering quality and efficiency. Our project page is at https://zju3dv.github.io/lidar-rt.
EnvGS: Modeling View-Dependent Appearance with Environment Gaussian
Dec 19, 2024



Reconstructing complex reflections in real-world scenes from 2D images is essential for achieving photorealistic novel view synthesis. Existing methods that utilize environment maps to model reflections from distant lighting often struggle with high-frequency reflection details and fail to account for near-field reflections. In this work, we introduce EnvGS, a novel approach that employs a set of Gaussian primitives as an explicit 3D representation for capturing reflections of environments. These environment Gaussian primitives are incorporated with base Gaussian primitives to model the appearance of the whole scene. To efficiently render these environment Gaussian primitives, we developed a ray-tracing-based renderer that leverages the GPU's RT core for fast rendering. This allows us to jointly optimize our model for high-quality reconstruction while maintaining real-time rendering speeds. Results from multiple real-world and synthetic datasets demonstrate that our method produces significantly more detailed reflections, achieving the best rendering quality in real-time novel view synthesis.
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
Dec 18, 2024Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.
Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
Dec 17, 2024Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Dec 17, 2024



This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
Representing Long Volumetric Video with Temporal Gaussian Hierarchy
Dec 12, 2024

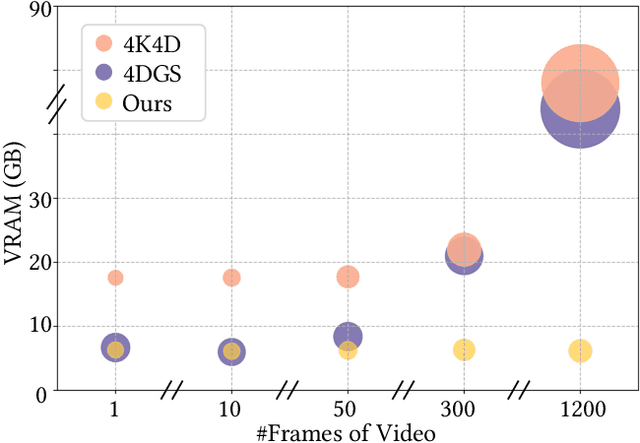
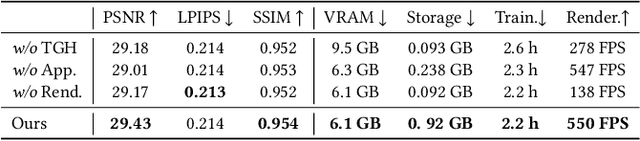
This paper aims to address the challenge of reconstructing long volumetric videos from multi-view RGB videos. Recent dynamic view synthesis methods leverage powerful 4D representations, like feature grids or point cloud sequences, to achieve high-quality rendering results. However, they are typically limited to short (1~2s) video clips and often suffer from large memory footprints when dealing with longer videos. To solve this issue, we propose a novel 4D representation, named Temporal Gaussian Hierarchy, to compactly model long volumetric videos. Our key observation is that there are generally various degrees of temporal redundancy in dynamic scenes, which consist of areas changing at different speeds. Motivated by this, our approach builds a multi-level hierarchy of 4D Gaussian primitives, where each level separately describes scene regions with different degrees of content change, and adaptively shares Gaussian primitives to represent unchanged scene content over different temporal segments, thus effectively reducing the number of Gaussian primitives. In addition, the tree-like structure of the Gaussian hierarchy allows us to efficiently represent the scene at a particular moment with a subset of Gaussian primitives, leading to nearly constant GPU memory usage during the training or rendering regardless of the video length. Extensive experimental results demonstrate the superiority of our method over alternative methods in terms of training cost, rendering speed, and storage usage. To our knowledge, this work is the first approach capable of efficiently handling minutes of volumetric video data while maintaining state-of-the-art rendering quality. Our project page is available at: https://zju3dv.github.io/longvolcap.
World-Grounded Human Motion Recovery via Gravity-View Coordinates
Sep 10, 2024



We present a novel method for recovering world-grounded human motion from monocular video. The main challenge lies in the ambiguity of defining the world coordinate system, which varies between sequences. Previous approaches attempt to alleviate this issue by predicting relative motion in an autoregressive manner, but are prone to accumulating errors. Instead, we propose estimating human poses in a novel Gravity-View (GV) coordinate system, which is defined by the world gravity and the camera view direction. The proposed GV system is naturally gravity-aligned and uniquely defined for each video frame, largely reducing the ambiguity of learning image-pose mapping. The estimated poses can be transformed back to the world coordinate system using camera rotations, forming a global motion sequence. Additionally, the per-frame estimation avoids error accumulation in the autoregressive methods. Experiments on in-the-wild benchmarks demonstrate that our method recovers more realistic motion in both the camera space and world-grounded settings, outperforming state-of-the-art methods in both accuracy and speed. The code is available at https://zju3dv.github.io/gvhmr/.
MSFMamba: Multi-Scale Feature Fusion State Space Model for Multi-Source Remote Sensing Image Classification
Aug 26, 2024In multi-source remote sensing image classification field, remarkable progress has been made by convolutional neural network and Transformer. However, existing methods are still limited due to the inherent local reductive bias. Recently, Mamba-based methods built upon the State Space Model have shown great potential for long-range dependency modeling with linear complexity, but it has rarely been explored for the multi-source remote sensing image classification task. To this end, we propose Multi-Scale Feature Fusion Mamba (MSFMamba) network for hyperspectral image (HSI) and LiDAR/SAR data joint classification. Specifically, MSFMamba mainly comprises three parts: Multi-Scale Spatial Mamba (MSpa-Mamba) block, Spectral Mamba (Spe-Mamba) block, and Fusion Mamba (Fus-Mamba) block. Specifically, to solve the feature redundancy in multiple canning routes, the MSpa-Mamba block incorporates the multi-scale strategy to minimize the computational redundancy and alleviate the feature redundancy of SSM. In addition, Spe-Mamba is designed for spectral feature exploration, which is essential for HSI feature modeling. Moreover, to alleviate the heterogeneous gap between HSI and LiDAR/SAR data, we design Fus-Mamba block for multi-source feature fusion. The original Mamba is extended to accommodate dual inputs, and cross-modal feature interaction is enhanced. Extensive experimental results on three multi-source remote sensing datasets demonstrate the superiority performance of the proposed MSFMamba over the state-of-the-art models. Source codes of MSFMamba will be made public available at https://github.com/summitgao/MSFMamba .