 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGARDEN: Gravity-Aligned Reconstruction of Disentangled ENvironments from RGB images
Jun 02, 2026Converting multi-view RGB observations into simulation-ready 3D environments remains challenging because current reconstruction pipelines produce monolithic scene representations without explicit physical structure. They are typically defined up to an arbitrary global rotation and entangle rigid foreground objects with background geometry, which hinders stable physical interaction. Existing solutions often recover interactivity by replacing reconstructed objects with retrieved CAD assets, but this introduces a slow retrieval-and-replacement stage and weakens scene-specific geometric fidelity. We propose GARDEN, an RGB-only framework that reformulates reconstruction as physically-grounded scene factorization and outputs a structured hybrid scene representation. The key idea is to use gravity as a universal physical prior: we first align the reconstruction to a unified Gravity-View frame to resolve gauge ambiguity, then recover object-centric rigid meshes with accurate 6-DoF placement, and finally remove duplicate object geometry from the background through conditional 3D point classification. The resulting representation combines explicit rigid bodies with a decoupled background, enabling direct physics simulation while preserving visual realism. Experiments on both simulated and real multi-view scenes show that GARDEN improves object placement reliability, disentanglement quality, and rendering-simulation efficiency compared with retrieval-based baselines.
Natural Human Motion Recovery by Aligning High-Order Temporal Dynamics from Monocular Videos
May 26, 2026Human motion recovered from monocular videos often appears overly smooth or dynamically inconsistent, even when joint positions are numerically accurate. We observe that this limitation stems from the absence of reliable high-order temporal cues -- velocity and acceleration -- which are essential for reconstructing motion that exhibits realistic momentum, timing, and high-frequency detail. We introduce HTD-Refine, a post-processing framework that augments existing Human Motion Recovery (HMR) pipelines using explicitly estimated high-order temporal dynamics. At the core of our system is PVA-Net, a temporal transformer that infers per-joint 2D positions, 3D velocities, and 3D accelerations directly from a monocular video. These predicted dynamics serve as soft yet informative constraints in a global optimization procedure that refines world-space trajectories, significantly reducing jitter, suppressing over-smoothing, and restoring physically plausible motion. Extensive experiments on challenging in-the-wild benchmarks show that HTD-Refine consistently improves state-of-the-art HMR methods, yielding more accurate global trajectories and substantially more natural motion dynamics. Our results highlight the critical role of high-order temporal modeling in advancing monocular human motion recovery.
Advancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training
Jan 13, 2025



Image matching, which aims to identify corresponding pixel locations between images, is crucial in a wide range of scientific disciplines, aiding in image registration, fusion, and analysis. In recent years, deep learning-based image matching algorithms have dramatically outperformed humans in rapidly and accurately finding large amounts of correspondences. However, when dealing with images captured under different imaging modalities that result in significant appearance changes, the performance of these algorithms often deteriorates due to the scarcity of annotated cross-modal training data. This limitation hinders applications in various fields that rely on multiple image modalities to obtain complementary information. To address this challenge, we propose a large-scale pre-training framework that utilizes synthetic cross-modal training signals, incorporating diverse data from various sources, to train models to recognize and match fundamental structures across images. This capability is transferable to real-world, unseen cross-modality image matching tasks. Our key finding is that the matching model trained with our framework achieves remarkable generalizability across more than eight unseen cross-modality registration tasks using the same network weight, substantially outperforming existing methods, whether designed for generalization or tailored for specific tasks. This advancement significantly enhances the applicability of image matching technologies across various scientific disciplines and paves the way for new applications in multi-modality human and artificial intelligence analysis and beyond.
Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
Dec 17, 2024Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.
World-Grounded Human Motion Recovery via Gravity-View Coordinates
Sep 10, 2024



We present a novel method for recovering world-grounded human motion from monocular video. The main challenge lies in the ambiguity of defining the world coordinate system, which varies between sequences. Previous approaches attempt to alleviate this issue by predicting relative motion in an autoregressive manner, but are prone to accumulating errors. Instead, we propose estimating human poses in a novel Gravity-View (GV) coordinate system, which is defined by the world gravity and the camera view direction. The proposed GV system is naturally gravity-aligned and uniquely defined for each video frame, largely reducing the ambiguity of learning image-pose mapping. The estimated poses can be transformed back to the world coordinate system using camera rotations, forming a global motion sequence. Additionally, the per-frame estimation avoids error accumulation in the autoregressive methods. Experiments on in-the-wild benchmarks demonstrate that our method recovers more realistic motion in both the camera space and world-grounded settings, outperforming state-of-the-art methods in both accuracy and speed. The code is available at https://zju3dv.github.io/gvhmr/.
Generating Human Motion in 3D Scenes from Text Descriptions
May 13, 2024



Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
Learning Human Mesh Recovery in 3D Scenes
Jun 06, 2023We present a novel method for recovering the absolute pose and shape of a human in a pre-scanned scene given a single image. Unlike previous methods that perform sceneaware mesh optimization, we propose to first estimate absolute position and dense scene contacts with a sparse 3D CNN, and later enhance a pretrained human mesh recovery network by cross-attention with the derived 3D scene cues. Joint learning on images and scene geometry enables our method to reduce the ambiguity caused by depth and occlusion, resulting in more reasonable global postures and contacts. Encoding scene-aware cues in the network also allows the proposed method to be optimization-free, and opens up the opportunity for real-time applications. The experiments show that the proposed network is capable of recovering accurate and physically-plausible meshes by a single forward pass and outperforms state-of-the-art methods in terms of both accuracy and speed.
Long-term Visual Localization with Mobile Sensors
Apr 16, 2023



Despite the remarkable advances in image matching and pose estimation, image-based localization of a camera in a temporally-varying outdoor environment is still a challenging problem due to huge appearance disparity between query and reference images caused by illumination, seasonal and structural changes. In this work, we propose to leverage additional sensors on a mobile phone, mainly GPS, compass, and gravity sensor, to solve this challenging problem. We show that these mobile sensors provide decent initial poses and effective constraints to reduce the searching space in image matching and final pose estimation. With the initial pose, we are also able to devise a direct 2D-3D matching network to efficiently establish 2D-3D correspondences instead of tedious 2D-2D matching in existing systems. As no public dataset exists for the studied problem, we collect a new dataset that provides a variety of mobile sensor data and significant scene appearance variations, and develop a system to acquire ground-truth poses for query images. We benchmark our method as well as several state-of-the-art baselines and demonstrate the effectiveness of the proposed approach. The code and dataset will be released publicly.
LoFTR: Detector-Free Local Feature Matching with Transformers
Apr 01, 2021
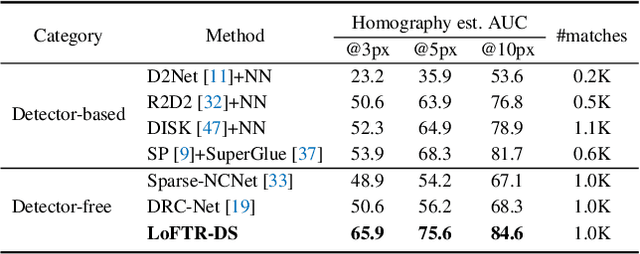
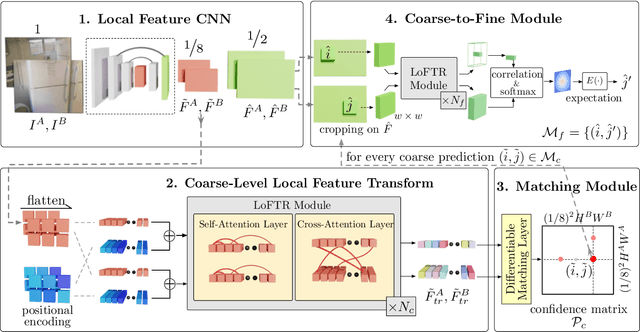
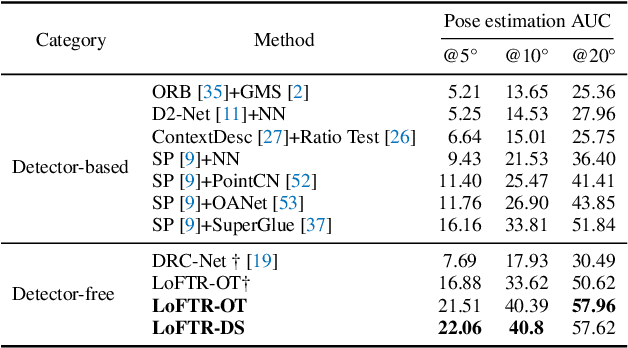
We present a novel method for local image feature matching. Instead of performing image feature detection, description, and matching sequentially, we propose to first establish pixel-wise dense matches at a coarse level and later refine the good matches at a fine level. In contrast to dense methods that use a cost volume to search correspondences, we use self and cross attention layers in Transformer to obtain feature descriptors that are conditioned on both images. The global receptive field provided by Transformer enables our method to produce dense matches in low-texture areas, where feature detectors usually struggle to produce repeatable interest points. The experiments on indoor and outdoor datasets show that LoFTR outperforms state-of-the-art methods by a large margin. LoFTR also ranks first on two public benchmarks of visual localization among the published methods.