 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Complete Anatomy of the Madden-Julian Oscillation Revealed by Artificial Intelligence
Dec 14, 2025Accurately defining the life cycle of the Madden-Julian Oscillation (MJO), the dominant mode of intraseasonal climate variability, remains a foundational challenge due to its propagating nature. The established linear-projection method (RMM index) often conflates mathematical artifacts with physical states, while direct clustering in raw data space is confounded by a "propagation penalty." Here, we introduce an "AI-for-theory" paradigm to objectively discover the MJO's intrinsic structure. We develop a deep learning model, PhysAnchor-MJO-AE, to learn a latent representation where vector distance corresponds to physical-feature similarity, enabling objective clustering of MJO dynamical states. Clustering these "MJO fingerprints" reveals the first complete, six-phase anatomical map of its life cycle. This taxonomy refines and critically completes the classical view by objectively isolating two long-hypothesized transitional phases: organizational growth over the Indian Ocean and the northward shift over the Philippine Sea. Derived from this anatomy, we construct a new physics-coherent monitoring framework that decouples location and intensity diagnostics. This framework reduces the rates of spurious propagation and convective misplacement by over an order of magnitude compared to the classical index. Our work transforms AI from a forecasting tool into a discovery microscope, establishing a reproducible template for extracting fundamental dynamical constructs from complex systems.
NeuralOGCM: Differentiable Ocean Modeling with Learnable Physics
Dec 12, 2025High-precision scientific simulation faces a long-standing trade-off between computational efficiency and physical fidelity. To address this challenge, we propose NeuralOGCM, an ocean modeling framework that fuses differentiable programming with deep learning. At the core of NeuralOGCM is a fully differentiable dynamical solver, which leverages physics knowledge as its core inductive bias. The learnable physics integration captures large-scale, deterministic physical evolution, and transforms key physical parameters (e.g., diffusion coefficients) into learnable parameters, enabling the model to autonomously optimize its physical core via end-to-end training. Concurrently, a deep neural network learns to correct for subgrid-scale processes and discretization errors not captured by the physics model. Both components work in synergy, with their outputs integrated by a unified ODE solver. Experiments demonstrate that NeuralOGCM maintains long-term stability and physical consistency, significantly outperforming traditional numerical models in speed and pure AI baselines in accuracy. Our work paves a new path for building fast, stable, and physically-plausible models for scientific computing.
Multi-Intent Spoken Language Understanding: Methods, Trends, and Challenges
Dec 12, 2025Multi-intent spoken language understanding (SLU) involves two tasks: multiple intent detection and slot filling, which jointly handle utterances containing more than one intent. Owing to this characteristic, which closely reflects real-world applications, the task has attracted increasing research attention, and substantial progress has been achieved. However, there remains a lack of a comprehensive and systematic review of existing studies on multi-intent SLU. To this end, this paper presents a survey of recent advances in multi-intent SLU. We provide an in-depth overview of previous research from two perspectives: decoding paradigms and modeling approaches. On this basis, we further compare the performance of representative models and analyze their strengths and limitations. Finally, we discuss the current challenges and outline promising directions for future research. We hope this survey will offer valuable insights and serve as a useful reference for advancing research in multi-intent SLU.
Advancing Ocean State Estimation with efficient and scalable AI
Nov 08, 2025Accurate and efficient global ocean state estimation remains a grand challenge for Earth system science, hindered by the dual bottlenecks of computational scalability and degraded data fidelity in traditional data assimilation (DA) and deep learning (DL) approaches. Here we present an AI-driven Data Assimilation Framework for Ocean (ADAF-Ocean) that directly assimilates multi-source and multi-scale observations, ranging from sparse in-situ measurements to 4 km satellite swaths, without any interpolation or data thinning. Inspired by Neural Processes, ADAF-Ocean learns a continuous mapping from heterogeneous inputs to ocean states, preserving native data fidelity. Through AI-driven super-resolution, it reconstructs 0.25$^\circ$ mesoscale dynamics from coarse 1$^\circ$ fields, which ensures both efficiency and scalability, with just 3.7\% more parameters than the 1$^\circ$ configuration. When coupled with a DL forecasting system, ADAF-Ocean extends global forecast skill by up to 20 days compared to baselines without assimilation. This framework establishes a computationally viable and scientifically rigorous pathway toward real-time, high-resolution Earth system monitoring.
NeuralOM: Neural Ocean Model for Subseasonal-to-Seasonal Simulation
May 27, 2025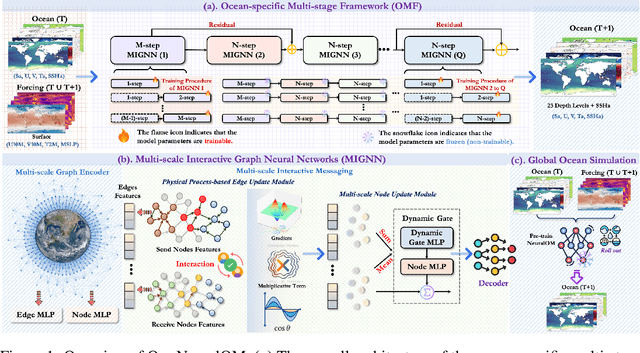
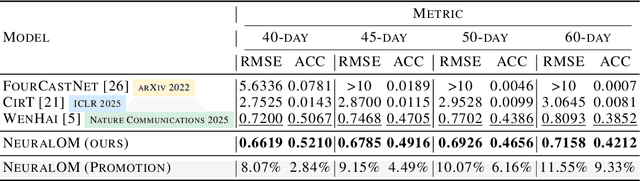
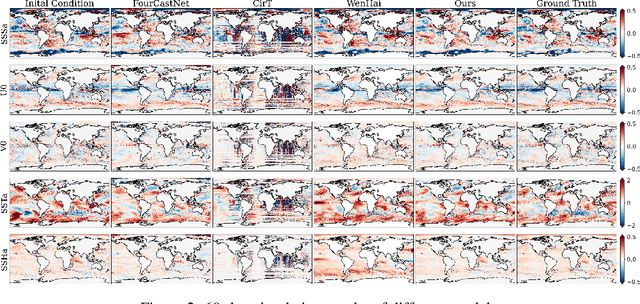
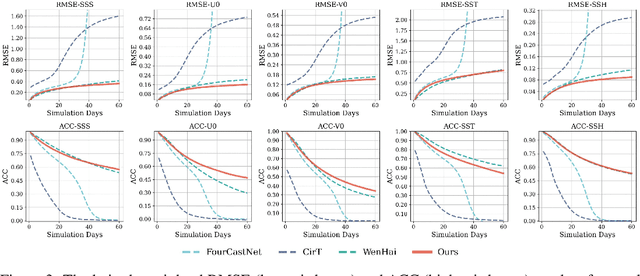
Accurate Subseasonal-to-Seasonal (S2S) ocean simulation is critically important for marine research, yet remains challenging due to its substantial thermal inertia and extended time delay. Machine learning (ML)-based models have demonstrated significant advancements in simulation accuracy and computational efficiency compared to traditional numerical methods. Nevertheless, a significant limitation of current ML models for S2S ocean simulation is their inadequate incorporation of physical consistency and the slow-changing properties of the ocean system. In this work, we propose a neural ocean model (NeuralOM) for S2S ocean simulation with a multi-scale interactive graph neural network to emulate diverse physical phenomena associated with ocean systems effectively. Specifically, we propose a multi-stage framework tailored to model the ocean's slowly changing nature. Additionally, we introduce a multi-scale interactive messaging module to capture complex dynamical behaviors, such as gradient changes and multiplicative coupling relationships inherent in ocean dynamics. Extensive experimental evaluations confirm that our proposed NeuralOM outperforms state-of-the-art models in S2S and extreme event simulation. The codes are available at https://github.com/YuanGao-YG/NeuralOM.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
Turb-L1: Achieving Long-term Turbulence Tracing By Tackling Spectral Bias
May 25, 2025



Accurately predicting the long-term evolution of turbulence is crucial for advancing scientific understanding and optimizing engineering applications. However, existing deep learning methods face significant bottlenecks in long-term autoregressive prediction, which exhibit excessive smoothing and fail to accurately track complex fluid dynamics. Our extensive experimental and spectral analysis of prevailing methods provides an interpretable explanation for this shortcoming, identifying Spectral Bias as the core obstacle. Concretely, spectral bias is the inherent tendency of models to favor low-frequency, smooth features while overlooking critical high-frequency details during training, thus reducing fidelity and causing physical distortions in long-term predictions. Building on this insight, we propose Turb-L1, an innovative turbulence prediction method, which utilizes a Hierarchical Dynamics Synthesis mechanism within a multi-grid architecture to explicitly overcome spectral bias. It accurately captures cross-scale interactions and preserves the fidelity of high-frequency dynamics, enabling reliable long-term tracking of turbulence evolution. Extensive experiments on the 2D turbulence benchmark show that Turb-L1 demonstrates excellent performance: (I) In long-term predictions, it reduces Mean Squared Error (MSE) by $80.3\%$ and increases Structural Similarity (SSIM) by over $9\times$ compared to the SOTA baseline, significantly improving prediction fidelity. (II) It effectively overcomes spectral bias, accurately reproducing the full enstrophy spectrum and maintaining physical realism in high-wavenumber regions, thus avoiding the spectral distortions or spurious energy accumulation seen in other methods.
EarthSynth: Generating Informative Earth Observation with Diffusion Models
May 17, 2025Remote sensing image (RSI) interpretation typically faces challenges due to the scarcity of labeled data, which limits the performance of RSI interpretation tasks. To tackle this challenge, we propose EarthSynth, a diffusion-based generative foundation model that enables synthesizing multi-category, cross-satellite labeled Earth observation for downstream RSI interpretation tasks. To the best of our knowledge, EarthSynth is the first to explore multi-task generation for remote sensing. EarthSynth, trained on the EarthSynth-180K dataset, employs the Counterfactual Composition training strategy to improve training data diversity and enhance category control. Furthermore, a rule-based method of R-Filter is proposed to filter more informative synthetic data for downstream tasks. We evaluate our EarthSynth on scene classification, object detection, and semantic segmentation in open-world scenarios, offering a practical solution for advancing RSI interpretation.
How to systematically develop an effective AI-based bias correction model?
Apr 21, 2025



This study introduces ReSA-ConvLSTM, an artificial intelligence (AI) framework for systematic bias correction in numerical weather prediction (NWP). We propose three innovations by integrating dynamic climatological normalization, ConvLSTM with temporal causality constraints, and residual self-attention mechanisms. The model establishes a physics-aware nonlinear mapping between ECMWF forecasts and ERA5 reanalysis data. Using 41 years (1981-2021) of global atmospheric data, the framework reduces systematic biases in 2-m air temperature (T2m), 10-m winds (U10/V10), and sea-level pressure (SLP), achieving up to 20% RMSE reduction over 1-7 day forecasts compared to operational ECMWF outputs. The lightweight architecture (10.6M parameters) enables efficient generalization to multiple variables and downstream applications, reducing retraining time by 85% for cross-variable correction while improving ocean model skill through bias-corrected boundary conditions. The ablation experiments demonstrate that our innovations significantly improve the model's correction performance, suggesting that incorporating variable characteristics into the model helps enhance forecasting skills.
A Physics-guided Multimodal Transformer Path to Weather and Climate Sciences
Apr 19, 2025With the rapid development of machine learning in recent years, many problems in meteorology can now be addressed using AI models. In particular, data-driven algorithms have significantly improved accuracy compared to traditional methods. Meteorological data is often transformed into 2D images or 3D videos, which are then fed into AI models for learning. Additionally, these models often incorporate physical signals, such as temperature, pressure, and wind speed, to further enhance accuracy and interpretability. In this paper, we review several representative AI + Weather/Climate algorithms and propose a new paradigm where observational data from different perspectives, each with distinct physical meanings, are treated as multimodal data and integrated via transformers. Furthermore, key weather and climate knowledge can be incorporated through regularization techniques to further strengthen the model's capabilities. This new paradigm is versatile and can address a variety of tasks, offering strong generalizability. We also discuss future directions for improving model accuracy and interpretability.