 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025



Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
NEARL-CLIP: Interacted Query Adaptation with Orthogonal Regularization for Medical Vision-Language Understanding
Aug 06, 2025



Computer-aided medical image analysis is crucial for disease diagnosis and treatment planning, yet limited annotated datasets restrict medical-specific model development. While vision-language models (VLMs) like CLIP offer strong generalization capabilities, their direct application to medical imaging analysis is impeded by a significant domain gap. Existing approaches to bridge this gap, including prompt learning and one-way modality interaction techniques, typically focus on introducing domain knowledge to a single modality. Although this may offer performance gains, it often causes modality misalignment, thereby failing to unlock the full potential of VLMs. In this paper, we propose \textbf{NEARL-CLIP} (i\underline{N}teracted qu\underline{E}ry \underline{A}daptation with o\underline{R}thogona\underline{L} Regularization), a novel cross-modality interaction VLM-based framework that contains two contributions: (1) Unified Synergy Embedding Transformer (USEformer), which dynamically generates cross-modality queries to promote interaction between modalities, thus fostering the mutual enrichment and enhancement of multi-modal medical domain knowledge; (2) Orthogonal Cross-Attention Adapter (OCA). OCA introduces an orthogonality technique to decouple the new knowledge from USEformer into two distinct components: the truly novel information and the incremental knowledge. By isolating the learning process from the interference of incremental knowledge, OCA enables a more focused acquisition of new information, thereby further facilitating modality interaction and unleashing the capability of VLMs. Notably, NEARL-CLIP achieves these two contributions in a parameter-efficient style, which only introduces \textbf{1.46M} learnable parameters.
MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding
Jul 08, 2025



Audio-driven emotional 3D facial animation aims to generate synchronized lip movements and vivid facial expressions. However, most existing approaches focus on static and predefined emotion labels, limiting their diversity and naturalness. To address these challenges, we propose MEDTalk, a novel framework for fine-grained and dynamic emotional talking head generation. Our approach first disentangles content and emotion embedding spaces from motion sequences using a carefully designed cross-reconstruction process, enabling independent control over lip movements and facial expressions. Beyond conventional audio-driven lip synchronization, we integrate audio and speech text, predicting frame-wise intensity variations and dynamically adjusting static emotion features to generate realistic emotional expressions. Furthermore, to enhance control and personalization, we incorporate multimodal inputs-including text descriptions and reference expression images-to guide the generation of user-specified facial expressions. With MetaHuman as the priority, our generated results can be conveniently integrated into the industrial production pipeline.
MedSeg-R: Reasoning Segmentation in Medical Images with Multimodal Large Language Models
Jun 12, 2025



Medical image segmentation is crucial for clinical diagnosis, yet existing models are limited by their reliance on explicit human instructions and lack the active reasoning capabilities to understand complex clinical questions. While recent advancements in multimodal large language models (MLLMs) have improved medical question-answering (QA) tasks, most methods struggle to generate precise segmentation masks, limiting their application in automatic medical diagnosis. In this paper, we introduce medical image reasoning segmentation, a novel task that aims to generate segmentation masks based on complex and implicit medical instructions. To address this, we propose MedSeg-R, an end-to-end framework that leverages the reasoning abilities of MLLMs to interpret clinical questions while also capable of producing corresponding precise segmentation masks for medical images. It is built on two core components: 1) a global context understanding module that interprets images and comprehends complex medical instructions to generate multi-modal intermediate tokens, and 2) a pixel-level grounding module that decodes these tokens to produce precise segmentation masks and textual responses. Furthermore, we introduce MedSeg-QA, a large-scale dataset tailored for the medical image reasoning segmentation task. It includes over 10,000 image-mask pairs and multi-turn conversations, automatically annotated using large language models and refined through physician reviews. Experiments show MedSeg-R's superior performance across several benchmarks, achieving high segmentation accuracy and enabling interpretable textual analysis of medical images.
ReCalKV: Low-Rank KV Cache Compression via Head Reordering and Offline Calibration
May 30, 2025



Large language models (LLMs) have achieved remarkable performance, yet their capability on long-context reasoning is often constrained by the excessive memory required to store the Key-Value (KV) cache. This makes KV cache compression an essential step toward enabling efficient long-context reasoning. Recent methods have explored reducing the hidden dimensions of the KV cache, but many introduce additional computation through projection layers or suffer from significant performance degradation under high compression ratios. To address these challenges, we propose ReCalKV, a post-training KV cache compression method that reduces the hidden dimensions of the KV cache. We develop distinct compression strategies for Keys and Values based on their different roles and varying importance in the attention mechanism. For Keys, we propose Head-wise Similarity-aware Reordering (HSR), which clusters similar heads and applies grouped SVD to the key projection matrix, reducing additional computation while preserving accuracy. For Values, we propose Offline Calibration and Matrix Fusion (OCMF) to preserve accuracy without extra computational overhead. Experiments show that ReCalKV outperforms existing low-rank compression methods, achieving high compression ratios with minimal performance loss. Code is available at: https://github.com/XIANGLONGYAN/ReCalKV.
MAP: Revisiting Weight Decomposition for Low-Rank Adaptation
May 29, 2025
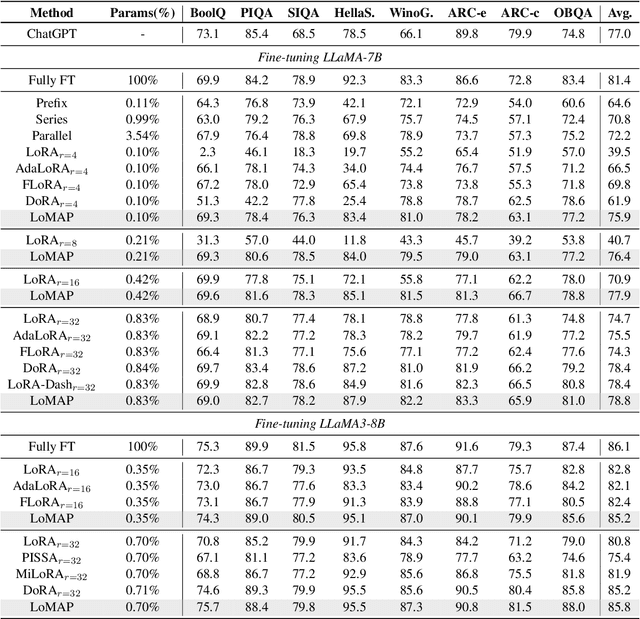
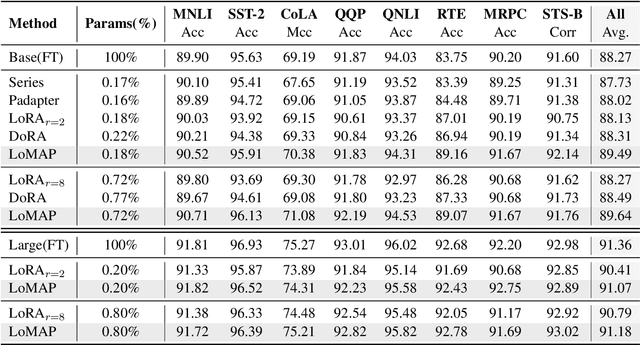

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.
Weight Spectra Induced Efficient Model Adaptation
May 29, 2025Large-scale foundation models have demonstrated remarkable versatility across a wide range of downstream tasks. However, fully fine-tuning these models incurs prohibitive computational costs, motivating the development of Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, which introduces low-rank updates to pre-trained weights. Despite their empirical success, the underlying mechanisms by which PEFT modifies model parameters remain underexplored. In this work, we present a systematic investigation into the structural changes of weight matrices during fully fine-tuning. Through singular value decomposition (SVD), we reveal that fine-tuning predominantly amplifies the top singular values while leaving the remainder largely intact, suggesting that task-specific knowledge is injected into a low-dimensional subspace. Furthermore, we find that the dominant singular vectors are reoriented in task-specific directions, whereas the non-dominant subspace remains stable. Building on these insights, we propose a novel method that leverages learnable rescaling of top singular directions, enabling precise modulation of the most influential components without disrupting the global structure. Our approach achieves consistent improvements over strong baselines across multiple tasks, highlighting the efficacy of structurally informed fine-tuning.
Revisiting Sparsity Constraint Under High-Rank Property in Partial Multi-Label Learning
May 27, 2025



Partial Multi-Label Learning (PML) extends the multi-label learning paradigm to scenarios where each sample is associated with a candidate label set containing both ground-truth labels and noisy labels. Existing PML methods commonly rely on two assumptions: sparsity of the noise label matrix and low-rankness of the ground-truth label matrix. However, these assumptions are inherently conflicting and impractical for real-world scenarios, where the true label matrix is typically full-rank or close to full-rank. To address these limitations, we demonstrate that the sparsity constraint contributes to the high-rank property of the predicted label matrix. Based on this, we propose a novel method Schirn, which introduces a sparsity constraint on the noise label matrix while enforcing a high-rank property on the predicted label matrix. Extensive experiments demonstrate the superior performance of Schirn compared to state-of-the-art methods, validating its effectiveness in tackling real-world PML challenges.
HAODiff: Human-Aware One-Step Diffusion via Dual-Prompt Guidance
May 26, 2025Human-centered images often suffer from severe generic degradation during transmission and are prone to human motion blur (HMB), making restoration challenging. Existing research lacks sufficient focus on these issues, as both problems often coexist in practice. To address this, we design a degradation pipeline that simulates the coexistence of HMB and generic noise, generating synthetic degraded data to train our proposed HAODiff, a human-aware one-step diffusion. Specifically, we propose a triple-branch dual-prompt guidance (DPG), which leverages high-quality images, residual noise (LQ minus HQ), and HMB segmentation masks as training targets. It produces a positive-negative prompt pair for classifier-free guidance (CFG) in a single diffusion step. The resulting adaptive dual prompts let HAODiff exploit CFG more effectively, boosting robustness against diverse degradations. For fair evaluation, we introduce MPII-Test, a benchmark rich in combined noise and HMB cases. Extensive experiments show that our HAODiff surpasses existing state-of-the-art (SOTA) methods in terms of both quantitative metrics and visual quality on synthetic and real-world datasets, including our introduced MPII-Test. Code is available at: https://github.com/gobunu/HAODiff.
Freqformer: Image-Demoiréing Transformer via Efficient Frequency Decomposition
May 25, 2025



Image demoir\'eing remains a challenging task due to the complex interplay between texture corruption and color distortions caused by moir\'e patterns. Existing methods, especially those relying on direct image-to-image restoration, often fail to disentangle these intertwined artifacts effectively. While wavelet-based frequency-aware approaches offer a promising direction, their potential remains underexplored. In this paper, we present Freqformer, a Transformer-based framework specifically designed for image demoir\'eing through targeted frequency separation. Our method performs an effective frequency decomposition that explicitly splits moir\'e patterns into high-frequency spatially-localized textures and low-frequency scale-robust color distortions, which are then handled by a dual-branch architecture tailored to their distinct characteristics. We further propose a learnable Frequency Composition Transform (FCT) module to adaptively fuse the frequency-specific outputs, enabling consistent and high-fidelity reconstruction. To better aggregate the spatial dependencies and the inter-channel complementary information, we introduce a Spatial-Aware Channel Attention (SA-CA) module that refines moir\'e-sensitive regions without incurring high computational cost. Extensive experiments on various demoir\'eing benchmarks demonstrate that Freqformer achieves state-of-the-art performance with a compact model size. The code is publicly available at https://github.com/xyLiu339/Freqformer.