 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP: Revisiting Weight Decomposition for Low-Rank Adaptation
Paper and Code

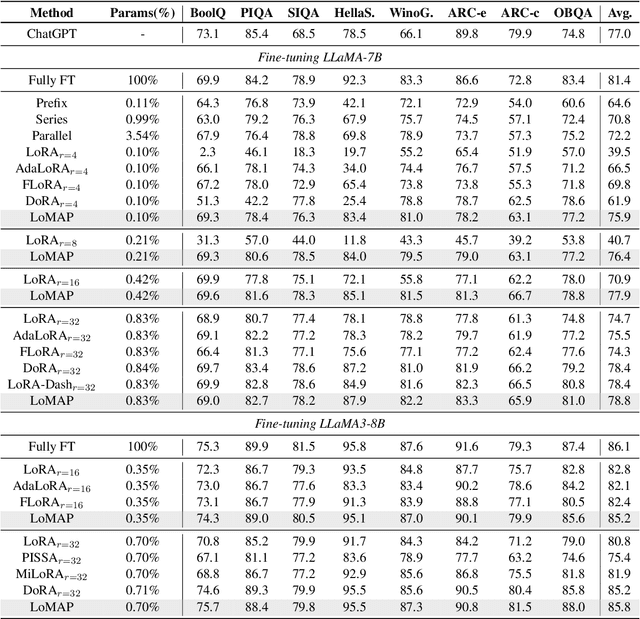
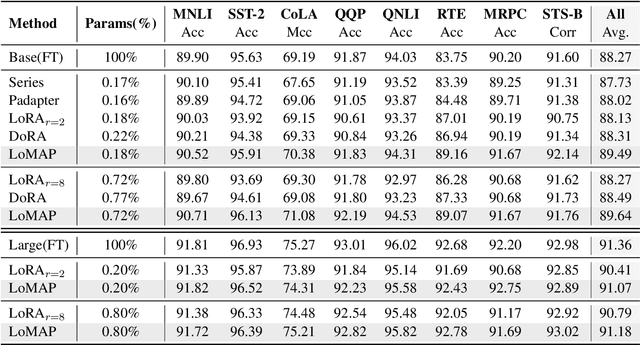

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.