 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward the Automated Construction of Probabilistic Knowledge Graphs for the Maritime Domain
May 04, 2023



International maritime crime is becoming increasingly sophisticated, often associated with wider criminal networks. Detecting maritime threats by means of fusing data purely related to physical movement (i.e., those generated by physical sensors, or hard data) is not sufficient. This has led to research and development efforts aimed at combining hard data with other types of data (especially human-generated or soft data). Existing work often assumes that input soft data is available in a structured format, or is focused on extracting certain relevant entities or concepts to accompany or annotate hard data. Much less attention has been given to extracting the rich knowledge about the situations of interest implicitly embedded in the large amount of soft data existing in unstructured formats (such as intelligence reports and news articles). In order to exploit the potentially useful and rich information from such sources, it is necessary to extract not only the relevant entities and concepts but also their semantic relations, together with the uncertainty associated with the extracted knowledge (i.e., in the form of probabilistic knowledge graphs). This will increase the accuracy of and confidence in, the extracted knowledge and facilitate subsequent reasoning and learning. To this end, we propose Maritime DeepDive, an initial prototype for the automated construction of probabilistic knowledge graphs from natural language data for the maritime domain. In this paper, we report on the current implementation of Maritime DeepDive, together with preliminary results on extracting probabilistic events from maritime piracy incidents. This pipeline was evaluated on a manually crafted gold standard, yielding promising results.
Towards Medical Artificial General Intelligence via Knowledge-Enhanced Multimodal Pretraining
Apr 26, 2023



Medical artificial general intelligence (MAGI) enables one foundation model to solve different medical tasks, which is very practical in the medical domain. It can significantly reduce the requirement of large amounts of task-specific data by sufficiently sharing medical knowledge among different tasks. However, due to the challenges of designing strongly generalizable models with limited and complex medical data, most existing approaches tend to develop task-specific models. To take a step towards MAGI, we propose a new paradigm called Medical-knOwledge-enhanced mulTimOdal pretRaining (MOTOR). In MOTOR, we combine two kinds of basic medical knowledge, i.e., general and specific knowledge, in a complementary manner to boost the general pretraining process. As a result, the foundation model with comprehensive basic knowledge can learn compact representations from pretraining radiographic data for better cross-modal alignment. MOTOR unifies the understanding and generation, which are two kinds of core intelligence of an AI system, into a single medical foundation model, to flexibly handle more diverse medical tasks. To enable a comprehensive evaluation and facilitate further research, we construct a medical multimodal benchmark including a wide range of downstream tasks, such as chest x-ray report generation and medical visual question answering. Extensive experiments on our benchmark show that MOTOR obtains promising results through simple task-oriented adaptation. The visualization shows that the injected knowledge successfully highlights key information in the medical data, demonstrating the excellent interpretability of MOTOR. Our MOTOR successfully mimics the human practice of fulfilling a "medical student" to accelerate the process of becoming a "specialist". We believe that our work makes a significant stride in realizing MAGI.
A Benchmark for Cycling Close Pass Near Miss Event Detection from Video Streams
Apr 24, 2023



Cycling is a healthy and sustainable mode of transport. However, interactions with motor vehicles remain a key barrier to increased cycling participation. The ability to detect potentially dangerous interactions from on-bike sensing could provide important information to riders and policy makers. Thus, automated detection of conflict between cyclists and drivers has attracted researchers from both computer vision and road safety communities. In this paper, we introduce a novel benchmark, called Cyc-CP, towards cycling close pass near miss event detection from video streams. We first divide this task into scene-level and instance-level problems. Scene-level detection asks an algorithm to predict whether there is a close pass near miss event in the input video clip. Instance-level detection aims to detect which vehicle in the scene gives rise to a close pass near miss. We propose two benchmark models based on deep learning techniques for these two problems. For training and testing those models, we construct a synthetic dataset and also collect a real-world dataset. Our models can achieve 88.13% and 84.60% accuracy on the real-world dataset, respectively. We envision this benchmark as a test-bed to accelerate cycling close pass near miss detection and facilitate interaction between the fields of road safety, intelligent transportation systems and artificial intelligence. Both the benchmark datasets and detection models will be available at https://github.com/SustainableMobility/cyc-cp to facilitate experimental reproducibility and encourage more in-depth research in the field.
Dynamic Graph Enhanced Contrastive Learning for Chest X-ray Report Generation
Mar 18, 2023



Automatic radiology reporting has great clinical potential to relieve radiologists from heavy workloads and improve diagnosis interpretation. Recently, researchers have enhanced data-driven neural networks with medical knowledge graphs to eliminate the severe visual and textual bias in this task. The structures of such graphs are exploited by using the clinical dependencies formed by the disease topic tags via general knowledge and usually do not update during the training process. Consequently, the fixed graphs can not guarantee the most appropriate scope of knowledge and limit the effectiveness. To address the limitation, we propose a knowledge graph with Dynamic structure and nodes to facilitate medical report generation with Contrastive Learning, named DCL. In detail, the fundamental structure of our graph is pre-constructed from general knowledge. Then we explore specific knowledge extracted from the retrieved reports to add additional nodes or redefine their relations in a bottom-up manner. Each image feature is integrated with its very own updated graph before being fed into the decoder module for report generation. Finally, this paper introduces Image-Report Contrastive and Image-Report Matching losses to better represent visual features and textual information. Evaluated on IU-Xray and MIMIC-CXR datasets, our DCL outperforms previous state-of-the-art models on these two benchmarks.
* Accepted by CVPR 2023. Project page: https://github.com/mlii0117/DCL
Guided Image-to-Image Translation by Discriminator-Generator Communication
Mar 07, 2023



The goal of Image-to-image (I2I) translation is to transfer an image from a source domain to a target domain, which has recently drawn increasing attention. One major branch of this research is to formulate I2I translation based on Generative Adversarial Network (GAN). As a zero-sum game, GAN can be reformulated as a Partially-observed Markov Decision Process (POMDP) for generators, where generators cannot access full state information of their environments. This formulation illustrates the information insufficiency in the GAN training. To mitigate this problem, we propose to add a communication channel between discriminators and generators. We explore multiple architecture designs to integrate the communication mechanism into the I2I translation framework. To validate the performance of the proposed approach, we have conducted extensive experiments on various benchmark datasets. The experimental results confirm the superiority of our proposed method.
3D-TOGO: Towards Text-Guided Cross-Category 3D Object Generation
Dec 02, 2022



Text-guided 3D object generation aims to generate 3D objects described by user-defined captions, which paves a flexible way to visualize what we imagined. Although some works have been devoted to solving this challenging task, these works either utilize some explicit 3D representations (e.g., mesh), which lack texture and require post-processing for rendering photo-realistic views; or require individual time-consuming optimization for every single case. Here, we make the first attempt to achieve generic text-guided cross-category 3D object generation via a new 3D-TOGO model, which integrates a text-to-views generation module and a views-to-3D generation module. The text-to-views generation module is designed to generate different views of the target 3D object given an input caption. prior-guidance, caption-guidance and view contrastive learning are proposed for achieving better view-consistency and caption similarity. Meanwhile, a pixelNeRF model is adopted for the views-to-3D generation module to obtain the implicit 3D neural representation from the previously-generated views. Our 3D-TOGO model generates 3D objects in the form of the neural radiance field with good texture and requires no time-cost optimization for every single caption. Besides, 3D-TOGO can control the category, color and shape of generated 3D objects with the input caption. Extensive experiments on the largest 3D object dataset (i.e., ABO) are conducted to verify that 3D-TOGO can better generate high-quality 3D objects according to the input captions across 98 different categories, in terms of PSNR, SSIM, LPIPS and CLIP-score, compared with text-NeRF and Dreamfields.
Deepfake Detection: A Comprehensive Study from the Reliability Perspective
Nov 20, 2022



The mushroomed Deepfake synthetic materials circulated on the internet have raised serious social impact to politicians, celebrities, and every human being on earth. In this paper, we provide a thorough review of the existing models following the development history of the Deepfake detection studies and define the research challenges of Deepfake detection in three aspects, namely, transferability, interpretability, and reliability. While the transferability and interpretability challenges have both been frequently discussed and attempted to solve with quantitative evaluations, the reliability issue has been barely considered, leading to the lack of reliable evidence in real-life usages and even for prosecutions on Deepfake related cases in court. We therefore conduct a model reliability study scheme using statistical random sampling knowledge and the publicly available benchmark datasets to qualitatively validate the detection performance of the existing models on arbitrary Deepfake candidate suspects. A barely remarked systematic data pre-processing procedure is demonstrated along with the fair training and testing experiments on the existing detection models. Case studies are further executed to justify the real-life Deepfake cases including different groups of victims with the help of reliably qualified detection models. The model reliability study provides a workflow for the detection models to act as or assist evidence for Deepfake forensic investigation in court once approved by authentication experts or institutions.
Simple Primitives with Feasibility- and Contextuality-Dependence for Open-World Compositional Zero-shot Learning
Nov 05, 2022The task of Compositional Zero-Shot Learning (CZSL) is to recognize images of novel state-object compositions that are absent during the training stage. Previous methods of learning compositional embedding have shown effectiveness in closed-world CZSL. However, in Open-World CZSL (OW-CZSL), their performance tends to degrade significantly due to the large cardinality of possible compositions. Some recent works separately predict simple primitives (i.e., states and objects) to reduce cardinality. However, they consider simple primitives as independent probability distributions, ignoring the heavy dependence between states, objects, and compositions. In this paper, we model the dependence of compositions via feasibility and contextuality. Feasibility-dependence refers to the unequal feasibility relations between simple primitives, e.g., \textit{hairy} is more feasible with \textit{cat} than with \textit{building} in the real world. Contextuality-dependence represents the contextual variance in images, e.g., \textit{cat} shows diverse appearances under the state of \textit{dry} and \textit{wet}. We design Semantic Attention (SA) and generative Knowledge Disentanglement (KD) to learn the dependence of feasibility and contextuality, respectively. SA captures semantics in compositions to alleviate impossible predictions, driven by the visual similarity between simple primitives. KD disentangles images into unbiased feature representations, easing contextual bias in predictions. Moreover, we complement the current compositional probability model with feasibility and contextuality in a compatible format. Finally, we conduct comprehensive experiments to analyze and validate the superior or competitive performance of our model, Semantic Attention and knowledge Disentanglement guided Simple Primitives (SAD-SP), on three widely-used benchmark OW-CZSL datasets.
Learning Self-Regularized Adversarial Views for Self-Supervised Vision Transformers
Oct 16, 2022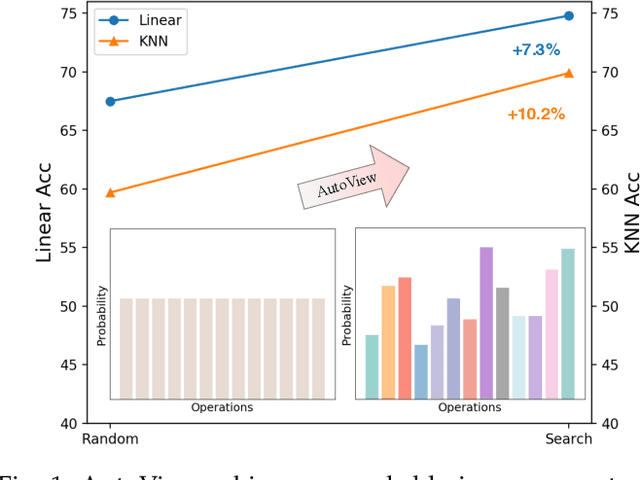
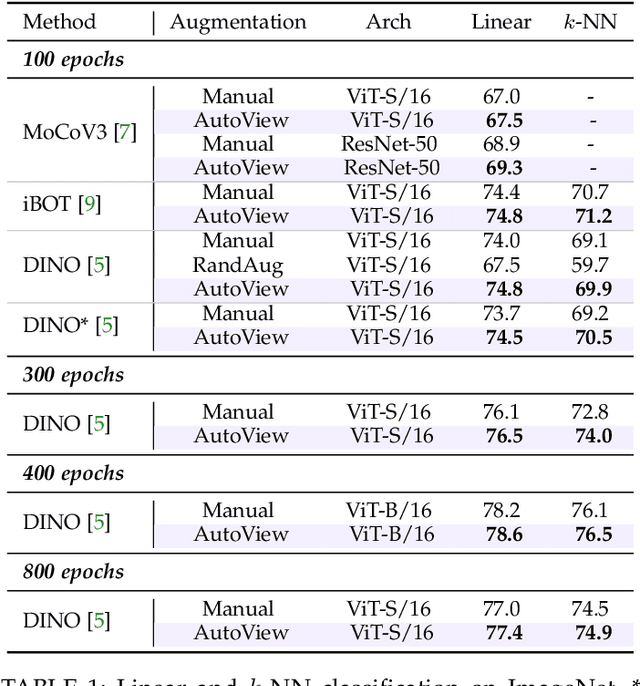
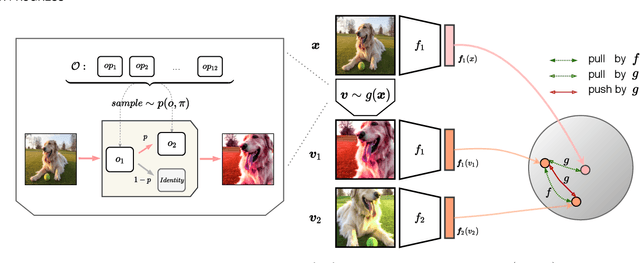

Automatic data augmentation (AutoAugment) strategies are indispensable in supervised data-efficient training protocols of vision transformers, and have led to state-of-the-art results in supervised learning. Despite the success, its development and application on self-supervised vision transformers have been hindered by several barriers, including the high search cost, the lack of supervision, and the unsuitable search space. In this work, we propose AutoView, a self-regularized adversarial AutoAugment method, to learn views for self-supervised vision transformers, by addressing the above barriers. First, we reduce the search cost of AutoView to nearly zero by learning views and network parameters simultaneously in a single forward-backward step, minimizing and maximizing the mutual information among different augmented views, respectively. Then, to avoid information collapse caused by the lack of label supervision, we propose a self-regularized loss term to guarantee the information propagation. Additionally, we present a curated augmentation policy search space for self-supervised learning, by modifying the generally used search space designed for supervised learning. On ImageNet, our AutoView achieves remarkable improvement over RandAug baseline (+10.2% k-NN accuracy), and consistently outperforms sota manually tuned view policy by a clear margin (up to +1.3% k-NN accuracy). Extensive experiments show that AutoView pretraining also benefits downstream tasks (+1.2% mAcc on ADE20K Semantic Segmentation and +2.8% mAP on revisited Oxford Image Retrieval benchmark) and improves model robustness (+2.3% Top-1 Acc on ImageNet-A and +1.0% AUPR on ImageNet-O). Code and models will be available at https://github.com/Trent-tangtao/AutoView.
PAR: Political Actor Representation Learning with Social Context and Expert Knowledge
Oct 15, 2022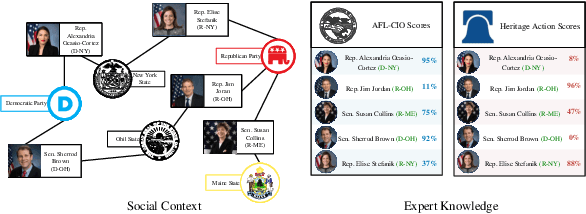
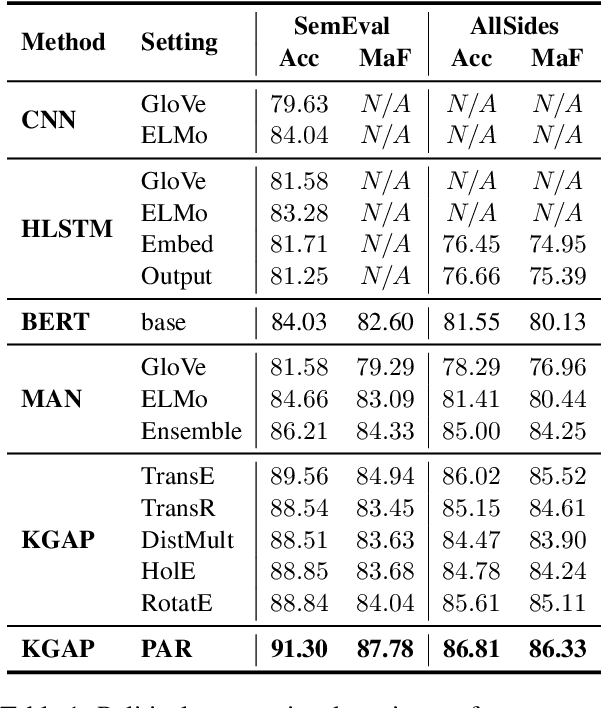
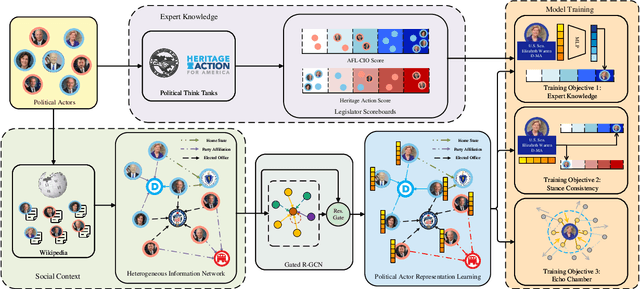
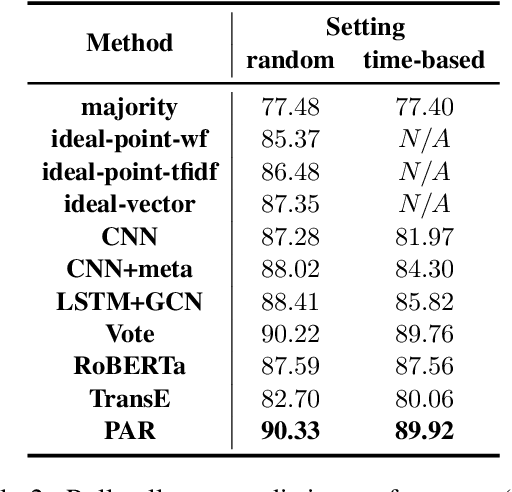
Modeling the ideological perspectives of political actors is an essential task in computational political science with applications in many downstream tasks. Existing approaches are generally limited to textual data and voting records, while they neglect the rich social context and valuable expert knowledge for holistic ideological analysis. In this paper, we propose \textbf{PAR}, a \textbf{P}olitical \textbf{A}ctor \textbf{R}epresentation learning framework that jointly leverages social context and expert knowledge. Specifically, we retrieve and extract factual statements about legislators to leverage social context information. We then construct a heterogeneous information network to incorporate social context and use relational graph neural networks to learn legislator representations. Finally, we train PAR with three objectives to align representation learning with expert knowledge, model ideological stance consistency, and simulate the echo chamber phenomenon. Extensive experiments demonstrate that PAR is better at augmenting political text understanding and successfully advances the state-of-the-art in political perspective detection and roll call vote prediction. Further analysis proves that PAR learns representations that reflect the political reality and provide new insights into political behavior.