 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion Handling by Pushing for Enhanced Fruit Detection
Apr 07, 2026In agricultural robotics, effective observation and localization of fruits present challenges due to occlusions caused by other parts of the tree, such as branches and leaves. These occlusions can result in false fruit localization or impede the robot from picking the fruit. The objective of this work is to push away branches that block the fruit's view to increase their visibility. Our setup consists of an RGB-D camera and a robot arm. First, we detect the occluded fruit in the RGB image and estimate its occluded part via a deep learning generative model in the depth space. The direction to push to clear the occlusions is determined using classic image processing techniques. We then introduce a 3D extension of the 2D Hough transform to detect straight line segments in the point cloud. This extension helps detect tree branches and identify the one mainly responsible for the occlusion. Finally, we clear the occlusion by pushing the branch with the robot arm. Our method uses a combination of deep learning for fruit appearance estimation, classic image processing for push direction determination, and 3D Hough transform for branch detection. We validate our perception methods through real data under different lighting conditions and various types of fruits (i.e. apple, lemon, orange), achieving improved visibility and successful occlusion clearance. We demonstrate the practical application of our approach through a real robot branch pushing demonstration.
Sound Judgment: Properties of Consequential Sounds Affecting Human-Perception of Robots
Feb 04, 2025
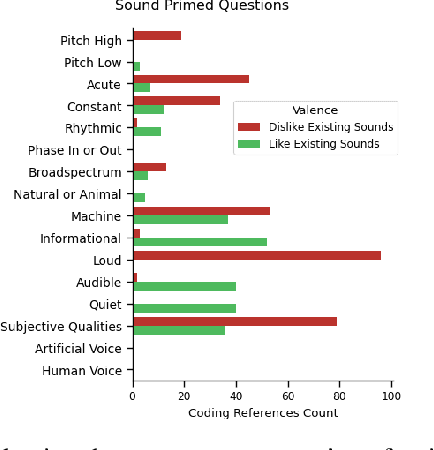
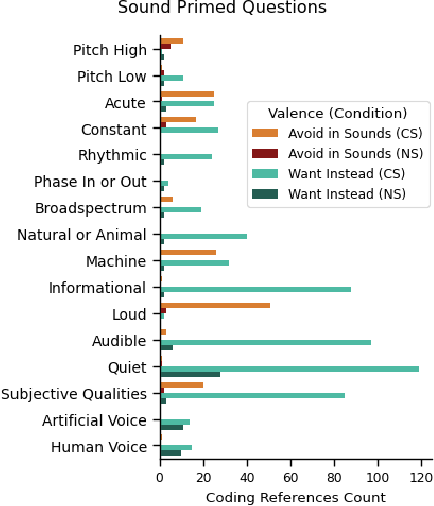
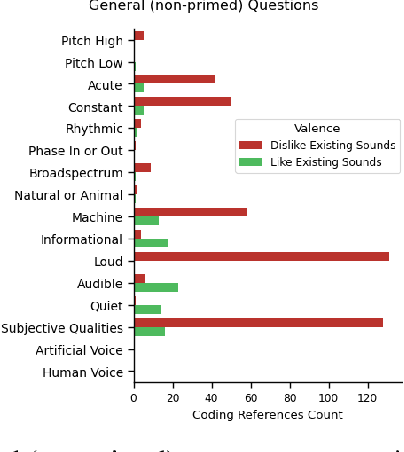
Positive human-perception of robots is critical to achieving sustained use of robots in shared environments. One key factor affecting human-perception of robots are their sounds, especially the consequential sounds which robots (as machines) must produce as they operate. This paper explores qualitative responses from 182 participants to gain insight into human-perception of robot consequential sounds. Participants viewed videos of different robots performing their typical movements, and responded to an online survey regarding their perceptions of robots and the sounds they produce. Topic analysis was used to identify common properties of robot consequential sounds that participants expressed liking, disliking, wanting or wanting to avoid being produced by robots. Alongside expected reports of disliking high pitched and loud sounds, many participants preferred informative and audible sounds (over no sound) to provide predictability of purpose and trajectory of the robot. Rhythmic sounds were preferred over acute or continuous sounds, and many participants wanted more natural sounds (such as wind or cat purrs) in-place of machine-like noise. The results presented in this paper support future research on methods to improve consequential sounds produced by robots by highlighting features of sounds that cause negative perceptions, and providing insights into sound profile changes for improvement of human-perception of robots, thus enhancing human robot interaction.
A Framework for Dynamic Situational Awareness in Human Robot Teams: An Interview Study
Jan 15, 2025



In human-robot teams, human situational awareness is the operator's conscious knowledge of the team's states, actions, plans and their environment. Appropriate human situational awareness is critical to successful human-robot collaboration. In human-robot teaming, it is often assumed that the best and required level of situational awareness is knowing everything at all times. This view is problematic, because what a human needs to know for optimal team performance varies given the dynamic environmental conditions, task context and roles and capabilities of team members. We explore this topic by interviewing 16 participants with active and repeated experience in diverse human-robot teaming applications. Based on analysis of these interviews, we derive a framework explaining the dynamic nature of required situational awareness in human-robot teaming. In addition, we identify a range of factors affecting the dynamic nature of required and actual levels of situational awareness (i.e., dynamic situational awareness), types of situational awareness inefficiencies resulting from gaps between actual and required situational awareness, and their main consequences. We also reveal various strategies, initiated by humans and robots, that assist in maintaining the required situational awareness. Our findings inform the implementation of accurate estimates of dynamic situational awareness and the design of user-adaptive human-robot interfaces. Therefore, this work contributes to the future design of more collaborative and effective human-robot teams.
'What did the Robot do in my Absence?' Video Foundation Models to Enhance Intermittent Supervision
Nov 15, 2024



This paper investigates the application of Video Foundation Models (ViFMs) for generating robot data summaries to enhance intermittent human supervision of robot teams. We propose a novel framework that produces both generic and query-driven summaries of long-duration robot vision data in three modalities: storyboards, short videos, and text. Through a user study involving 30 participants, we evaluate the efficacy of these summary methods in allowing operators to accurately retrieve the observations and actions that occurred while the robot was operating without supervision over an extended duration (40 min). Our findings reveal that query-driven summaries significantly improve retrieval accuracy compared to generic summaries or raw data, albeit with increased task duration. Storyboards are found to be the most effective presentation modality, especially for object-related queries. This work represents, to our knowledge, the first zero-shot application of ViFMs for generating multi-modal robot-to-human communication in intermittent supervision contexts, demonstrating both the promise and limitations of these models in human-robot interaction (HRI) scenarios.
Classifying Bicycle Infrastructure Using On-Bike Street-Level Images
Oct 24, 2024



While cycling offers an attractive option for sustainable transportation, many potential cyclists are discouraged from taking up cycling due to the lack of suitable and safe infrastructure. Efficiently mapping cycling infrastructure across entire cities is necessary to advance our understanding of how to provide connected networks of high-quality infrastructure. Therefore we propose a system capable of classifying available cycling infrastructure from on-bike smartphone camera data. The system receives an image sequence as input, temporally analyzing the sequence to account for sparsity of signage. The model outputs cycling infrastructure class labels defined by a hierarchical classification system. Data is collected via participant cyclists covering 7,006Km across the Greater Melbourne region that is automatically labeled via a GPS and OpenStreetMap database matching algorithm. The proposed model achieved an accuracy of 95.38%, an increase in performance of 7.55% compared to the non-temporal model. The model demonstrated robustness to extreme absence of image features where the model lost only 6.6% in accuracy after 90% of images being replaced with blank images. This work is the first to classify cycling infrastructure using only street-level imagery collected from bike-mounted mobile phone cameras, while demonstrating robustness to feature sparsity via long temporal sequence analysis.
"One Soy Latte for Daniel": Visual and Movement Communication of Intention from a Robot Waiter to a Group of Customers
Jul 08, 2024Service robots are increasingly employed in the hospitality industry for delivering food orders in restaurants. However, in current practice the robot often arrives at a fixed location for each table when delivering orders to different patrons in the same dining group, thus requiring a human staff member or the customers themselves to identify and retrieve each order. This study investigates how to improve the robot's service behaviours to facilitate clear intention communication to a group of users, thus achieving accurate delivery and positive user experiences. Specifically, we conduct user studies (N=30) with a Temi service robot as a representative delivery robot currently adopted in restaurants. We investigated two factors in the robot's intent communication, namely visualisation and movement trajectories, and their influence on the objective and subjective interaction outcomes. A robot personalising its movement trajectory and stopping location in addition to displaying a visualisation of the order yields more accurate intent communication and successful order delivery, as well as more positive user perception towards the robot and its service. Our results also showed that individuals in a group have different interaction experiences.
Robotic Vision for Human-Robot Interaction and Collaboration: A Survey and Systematic Review
Jul 28, 2023



Robotic vision for human-robot interaction and collaboration is a critical process for robots to collect and interpret detailed information related to human actions, goals, and preferences, enabling robots to provide more useful services to people. This survey and systematic review presents a comprehensive analysis on robotic vision in human-robot interaction and collaboration over the last 10 years. From a detailed search of 3850 articles, systematic extraction and evaluation was used to identify and explore 310 papers in depth. These papers described robots with some level of autonomy using robotic vision for locomotion, manipulation and/or visual communication to collaborate or interact with people. This paper provides an in-depth analysis of current trends, common domains, methods and procedures, technical processes, data sets and models, experimental testing, sample populations, performance metrics and future challenges. This manuscript found that robotic vision was often used in action and gesture recognition, robot movement in human spaces, object handover and collaborative actions, social communication and learning from demonstration. Few high-impact and novel techniques from the computer vision field had been translated into human-robot interaction and collaboration. Overall, notable advancements have been made on how to develop and deploy robots to assist people.
Learning to Assist and Communicate with Novice Drone Pilots for Expert Level Performance
Jun 16, 2023



Multi-task missions for unmanned aerial vehicles (UAVs) involving inspection and landing tasks are challenging for novice pilots due to the difficulties associated with depth perception and the control interface. We propose a shared autonomy system, alongside supplementary information displays, to assist pilots to successfully complete multi-task missions without any pilot training. Our approach comprises of three modules: (1) a perception module that encodes visual information onto a latent representation, (2) a policy module that augments pilot's actions, and (3) an information augmentation module that provides additional information to the pilot. The policy module is trained in simulation with simulated users and transferred to the real world without modification in a user study (n=29), alongside supplementary information schemes including learnt red/green light feedback cues and an augmented reality display. The pilot's intent is unknown to the policy module and is inferred from the pilot's input and UAV's states. The assistant increased task success rate for the landing and inspection tasks from [16.67% & 54.29%] respectively to [95.59% & 96.22%]. With the assistant, inexperienced pilots achieved similar performance to experienced pilots. Red/green light feedback cues reduced the required time by 19.53% and trajectory length by 17.86% for the inspection task, where participants rated it as their preferred condition due to the intuitive interface and providing reassurance. This work demonstrates that simple user models can train shared autonomy systems in simulation, and transfer to physical tasks to estimate user intent and provide effective assistance and information to the pilot.
Towards vision-based dual arm robotic fruit harvesting
Jun 16, 2023Interest in agricultural robotics has increased considerably in recent years due to benefits such as improvement in productivity and labor reduction. However, current problems associated with unstructured environments make the development of robotic harvesters challenging. Most research in agricultural robotics focuses on single arm manipulation. Here, we propose a dual-arm approach. We present a dual-arm fruit harvesting robot equipped with a RGB-D camera, cutting and collecting tools. We exploit the cooperative task description to maximize the capabilities of the dual-arm robot. We designed a Hierarchical Quadratic Programming based control strategy to fulfill the set of hard constrains related to the robot and environment: robot joint limits, robot self-collisions, robot-fruit and robot-tree collisions. We combine deep learning and standard image processing algorithms to detect and track fruits as well as the tree trunk in the scene. We validate our perception methods on real-world RGB-D images and our control method on simulated experiments.
A Benchmark for Cycling Close Pass Near Miss Event Detection from Video Streams
Apr 24, 2023



Cycling is a healthy and sustainable mode of transport. However, interactions with motor vehicles remain a key barrier to increased cycling participation. The ability to detect potentially dangerous interactions from on-bike sensing could provide important information to riders and policy makers. Thus, automated detection of conflict between cyclists and drivers has attracted researchers from both computer vision and road safety communities. In this paper, we introduce a novel benchmark, called Cyc-CP, towards cycling close pass near miss event detection from video streams. We first divide this task into scene-level and instance-level problems. Scene-level detection asks an algorithm to predict whether there is a close pass near miss event in the input video clip. Instance-level detection aims to detect which vehicle in the scene gives rise to a close pass near miss. We propose two benchmark models based on deep learning techniques for these two problems. For training and testing those models, we construct a synthetic dataset and also collect a real-world dataset. Our models can achieve 88.13% and 84.60% accuracy on the real-world dataset, respectively. We envision this benchmark as a test-bed to accelerate cycling close pass near miss detection and facilitate interaction between the fields of road safety, intelligent transportation systems and artificial intelligence. Both the benchmark datasets and detection models will be available at https://github.com/SustainableMobility/cyc-cp to facilitate experimental reproducibility and encourage more in-depth research in the field.