 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerson Re-identification with Deep Similarity-Guided Graph Neural Network
Jul 26, 2018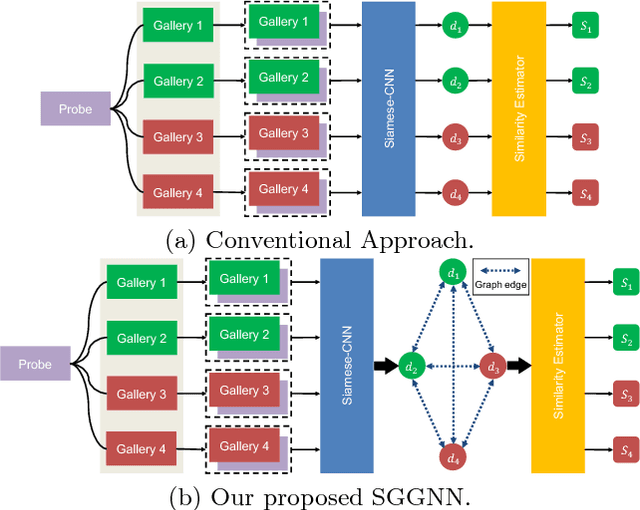
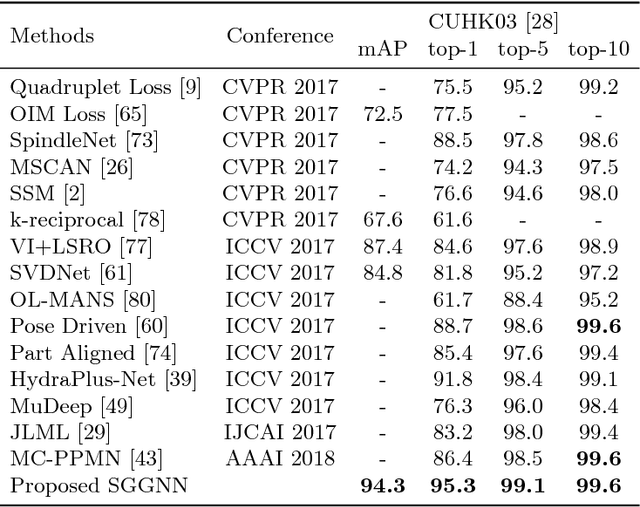
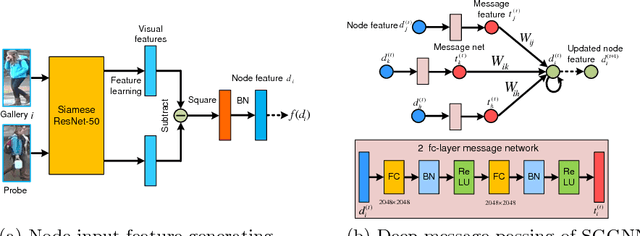
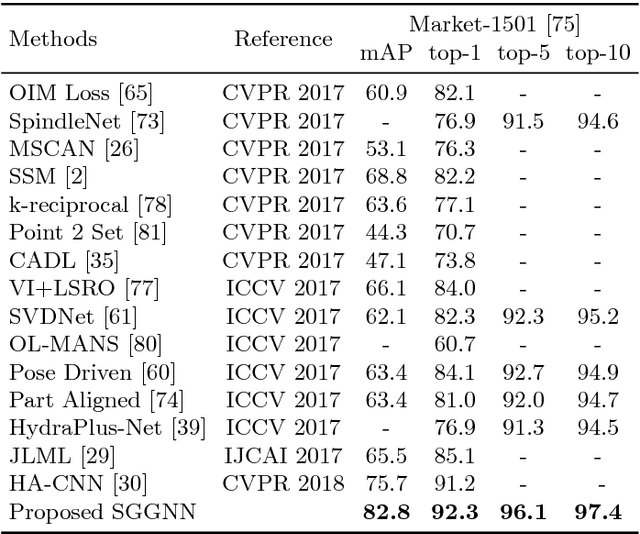
The person re-identification task requires to robustly estimate visual similarities between person images. However, existing person re-identification models mostly estimate the similarities of different image pairs of probe and gallery images independently while ignores the relationship information between different probe-gallery pairs. As a result, the similarity estimation of some hard samples might not be accurate. In this paper, we propose a novel deep learning framework, named Similarity-Guided Graph Neural Network (SGGNN) to overcome such limitations. Given a probe image and several gallery images, SGGNN creates a graph to represent the pairwise relationships between probe-gallery pairs (nodes) and utilizes such relationships to update the probe-gallery relation features in an end-to-end manner. Accurate similarity estimation can be achieved by using such updated probe-gallery relation features for prediction. The input features for nodes on the graph are the relation features of different probe-gallery image pairs. The probe-gallery relation feature updating is then performed by the messages passing in SGGNN, which takes other nodes' information into account for similarity estimation. Different from conventional GNN approaches, SGGNN learns the edge weights with rich labels of gallery instance pairs directly, which provides relation fusion more precise information. The effectiveness of our proposed method is validated on three public person re-identification datasets.
Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data
Jul 23, 2018
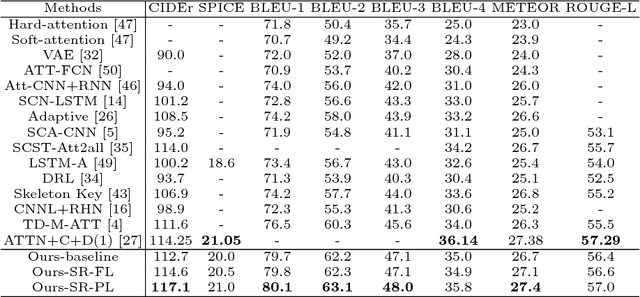
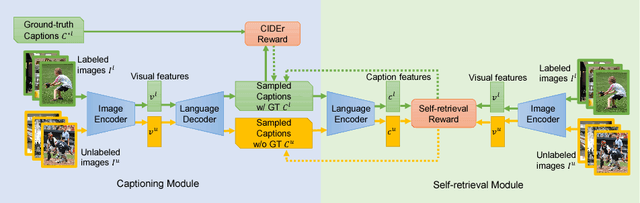
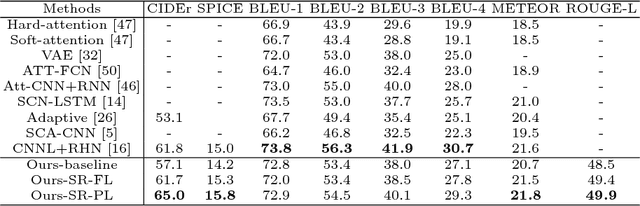
The aim of image captioning is to generate captions by machine to describe image contents. Despite many efforts, generating discriminative captions for images remains non-trivial. Most traditional approaches imitate the language structure patterns, thus tend to fall into a stereotype of replicating frequent phrases or sentences and neglect unique aspects of each image. In this work, we propose an image captioning framework with a self-retrieval module as training guidance, which encourages generating discriminative captions. It brings unique advantages: (1) the self-retrieval guidance can act as a metric and an evaluator of caption discriminativeness to assure the quality of generated captions. (2) The correspondence between generated captions and images are naturally incorporated in the generation process without human annotations, and hence our approach could utilize a large amount of unlabeled images to boost captioning performance with no additional laborious annotations. We demonstrate the effectiveness of the proposed retrieval-guided method on COCO and Flickr30k captioning datasets, and show its superior captioning performance with more discriminative captions.
Talking Face Generation by Adversarially Disentangled Audio-Visual Representation
Jul 20, 2018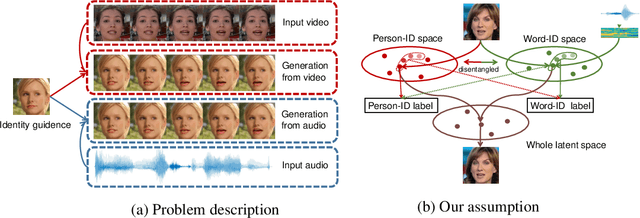

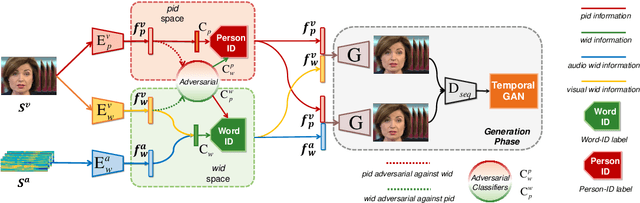

Talking face generation aims to synthesize a sequence of face images that correspond to given speech semantics. However, when people talk, the subtle movements of their face region are usually a complex combination of the intrinsic face appearance of the subject and also the extrinsic speech to be delivered. Existing works either focus on the former, which constructs the specific face appearance model on a single subject; or the latter, which models the identity-agnostic transformation between lip motion and speech. In this work, we integrate both aspects and enable arbitrary-subject talking face generation by learning disentangled audio-visual representation. We assume the talking face sequence is actually a composition of both subject-related information and speech-related information. These two spaces are then explicitly disentangled through a novel associative-and-adversarial training process. The disentangled representation has an additional advantage that both audio and video can serve as the source of speech information for generation. Extensive experiments show that our proposed approach can generate realistic talking face sequences on arbitrary subjects with much clearer lip motion patterns. We also demonstrate the learned audio-visual representation is extremely useful for applications like automatic lip reading and audio-video retrieval.
SCAN: Self-and-Collaborative Attention Network for Video Person Re-identification
Jul 20, 2018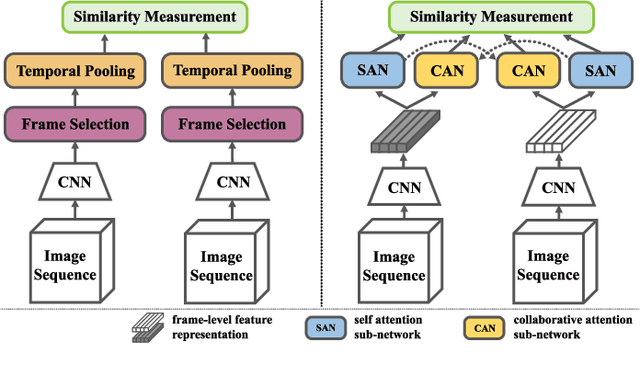


Video person re-identification attracts much attention in recent years. It aims to match image sequences of pedestrians from different camera views. Previous approaches usually improve this task from three aspects, including a) selecting more discriminative frames, b) generating more informative temporal representations, and c) developing more effective distance metrics. To address the above issues, we present a novel and practical deep architecture for video person re-identification termed Self-and-Collaborative Attention Network (SCAN). It has several appealing properties. First, SCAN adopts non-parametric attention mechanism to refine the intra-sequence and inter-sequence feature representation of videos, and outputs self-and-collaborative feature representation for each video, making the discriminative frames aligned between the probe and gallery sequences.Second, beyond existing models, a generalized pairwise similarity measurement is proposed to calculate the similarity feature representations of video pairs, enabling computing the matching scores by the binary classifier. Third, a dense clip segmentation strategy is also introduced to generate rich probe-gallery pairs to optimize the model. Extensive experiments demonstrate the effectiveness of SCAN, which outperforms top-1 accuracies of the best-performing baselines by 7.8%, 2.1% and 4.9% on iLIDS-VID, PRID2011 and MARS dataset, respectively.
Zoom-Net: Mining Deep Feature Interactions for Visual Relationship Recognition
Jul 13, 2018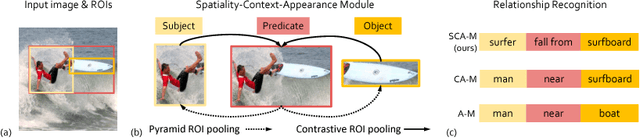
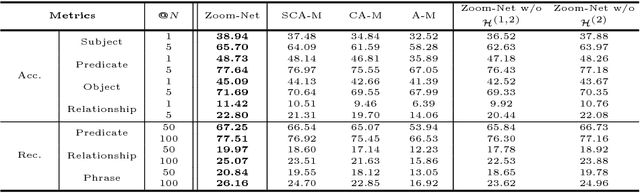
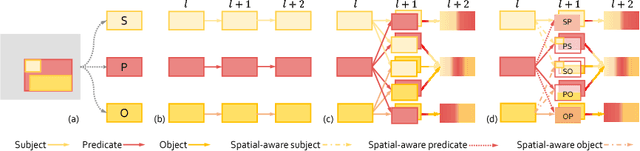
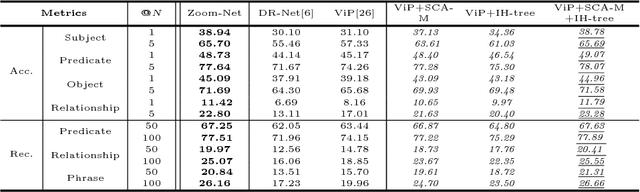
Recognizing visual relationships <subject-predicate-object> among any pair of localized objects is pivotal for image understanding. Previous studies have shown remarkable progress in exploiting linguistic priors or external textual information to improve the performance. In this work, we investigate an orthogonal perspective based on feature interactions. We show that by encouraging deep message propagation and interactions between local object features and global predicate features, one can achieve compelling performance in recognizing complex relationships without using any linguistic priors. To this end, we present two new pooling cells to encourage feature interactions: (i) Contrastive ROI Pooling Cell, which has a unique deROI pooling that inversely pools local object features to the corresponding area of global predicate features. (ii) Pyramid ROI Pooling Cell, which broadcasts global predicate features to reinforce local object features.The two cells constitute a Spatiality-Context-Appearance Module (SCA-M), which can be further stacked consecutively to form our final Zoom-Net.We further shed light on how one could resolve ambiguous and noisy object and predicate annotations by Intra-Hierarchical trees (IH-tree). Extensive experiments conducted on Visual Genome dataset demonstrate the effectiveness of our feature-oriented approach compared to state-of-the-art methods (Acc@1 11.42% from 8.16%) that depend on explicit modeling of linguistic interactions. We further show that SCA-M can be incorporated seamlessly into existing approaches to improve the performance by a large margin. The source code will be released on https://github.com/gjyin91/ZoomNet.
StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
Jun 28, 2018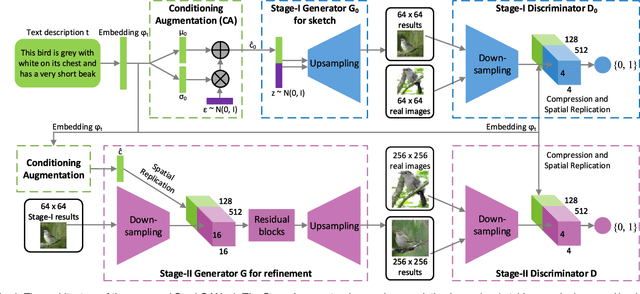

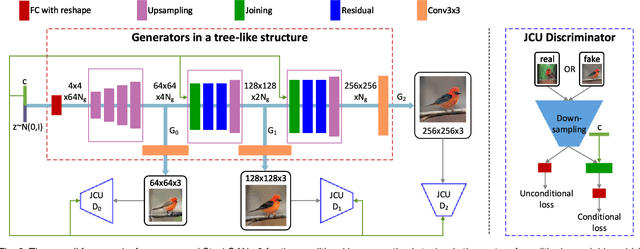

Although Generative Adversarial Networks (GANs) have shown remarkable success in various tasks, they still face challenges in generating high quality images. In this paper, we propose Stacked Generative Adversarial Networks (StackGAN) aiming at generating high-resolution photo-realistic images. First, we propose a two-stage generative adversarial network architecture, StackGAN-v1, for text-to-image synthesis. The Stage-I GAN sketches the primitive shape and colors of the object based on given text description, yielding low-resolution images. The Stage-II GAN takes Stage-I results and text descriptions as inputs, and generates high-resolution images with photo-realistic details. Second, an advanced multi-stage generative adversarial network architecture, StackGAN-v2, is proposed for both conditional and unconditional generative tasks. Our StackGAN-v2 consists of multiple generators and discriminators in a tree-like structure; images at multiple scales corresponding to the same scene are generated from different branches of the tree. StackGAN-v2 shows more stable training behavior than StackGAN-v1 by jointly approximating multiple distributions. Extensive experiments demonstrate that the proposed stacked generative adversarial networks significantly outperform other state-of-the-art methods in generating photo-realistic images.
Zoom Out-and-In Network with Map Attention Decision for Region Proposal and Object Detection
Jun 08, 2018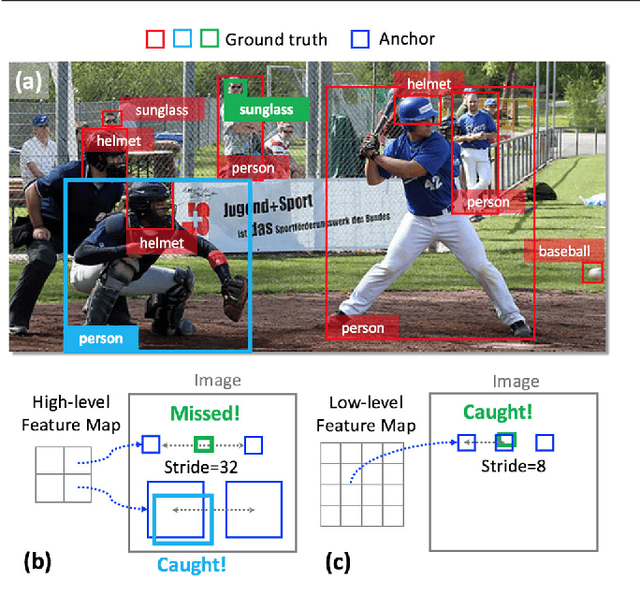
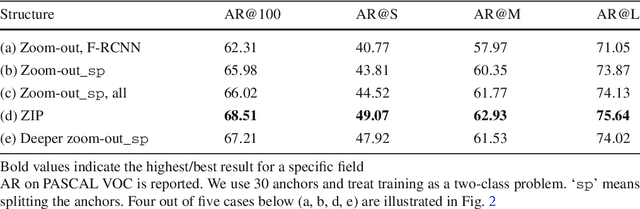
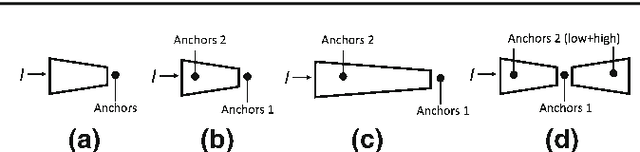
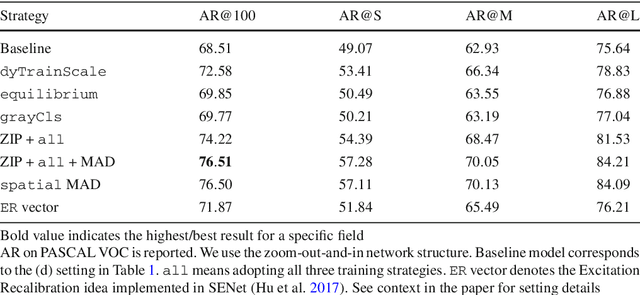
In this paper, we propose a zoom-out-and-in network for generating object proposals. A key observation is that it is difficult to classify anchors of different sizes with the same set of features. Anchors of different sizes should be placed accordingly based on different depth within a network: smaller boxes on high-resolution layers with a smaller stride while larger boxes on low-resolution counterparts with a larger stride. Inspired by the conv/deconv structure, we fully leverage the low-level local details and high-level regional semantics from two feature map streams, which are complimentary to each other, to identify the objectness in an image. A map attention decision (MAD) unit is further proposed to aggressively search for neuron activations among two streams and attend the most contributive ones on the feature learning of the final loss. The unit serves as a decisionmaker to adaptively activate maps along certain channels with the solely purpose of optimizing the overall training loss. One advantage of MAD is that the learned weights enforced on each feature channel is predicted on-the-fly based on the input context, which is more suitable than the fixed enforcement of a convolutional kernel. Experimental results on three datasets, including PASCAL VOC 2007, ImageNet DET, MS COCO, demonstrate the effectiveness of our proposed algorithm over other state-of-the-arts, in terms of average recall (AR) for region proposal and average precision (AP) for object detection.
Deep Continuous Conditional Random Fields with Asymmetric Inter-object Constraints for Online Multi-object Tracking
Jun 04, 2018
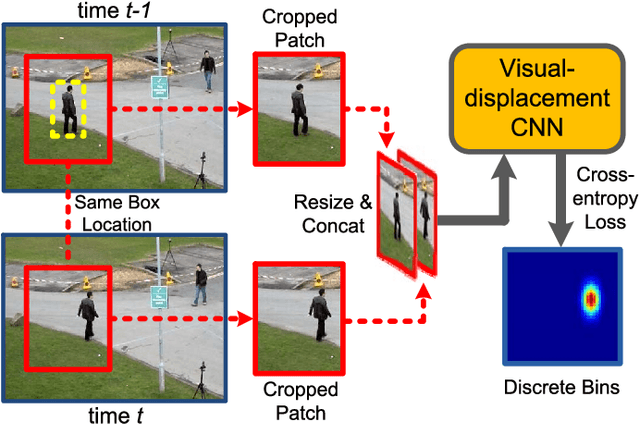
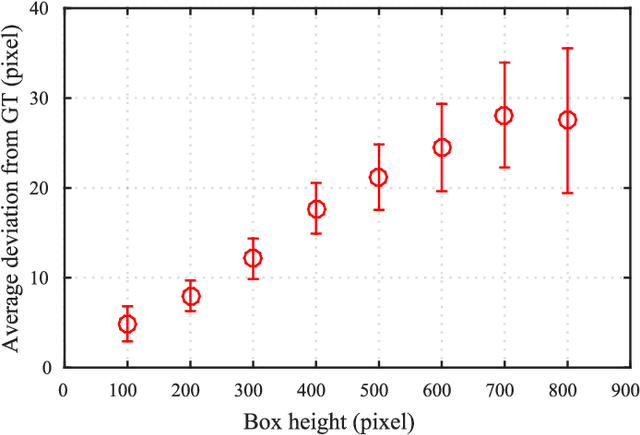
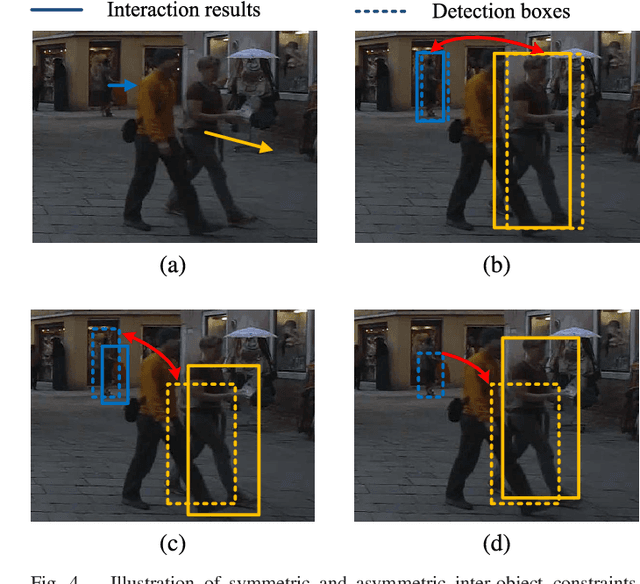
Online Multi-Object Tracking (MOT) is a challenging problem and has many important applications including intelligence surveillance, robot navigation and autonomous driving. In existing MOT methods, individual object's movements and inter-object relations are mostly modeled separately and relations between them are still manually tuned. In addition, inter-object relations are mostly modeled in a symmetric way, which we argue is not an optimal setting. To tackle those difficulties, in this paper, we propose a Deep Continuous Conditional Random Field (DCCRF) for solving the online MOT problem in a track-by-detection framework. The DCCRF consists of unary and pairwise terms. The unary terms estimate tracked objects' displacements across time based on visual appearance information. They are modeled as deep Convolution Neural Networks, which are able to learn discriminative visual features for tracklet association. The asymmetric pairwise terms model inter-object relations in an asymmetric way, which encourages high-confidence tracklets to help correct errors of low-confidence tracklets and not to be affected by low-confidence ones much. The DCCRF is trained in an end-to-end manner for better adapting the influences of visual information as well as inter-object relations. Extensive experimental comparisons with state-of-the-arts as well as detailed component analysis of our proposed DCCRF on two public benchmarks demonstrate the effectiveness of our proposed MOT framework.
Avatar-Net: Multi-scale Zero-shot Style Transfer by Feature Decoration
May 22, 2018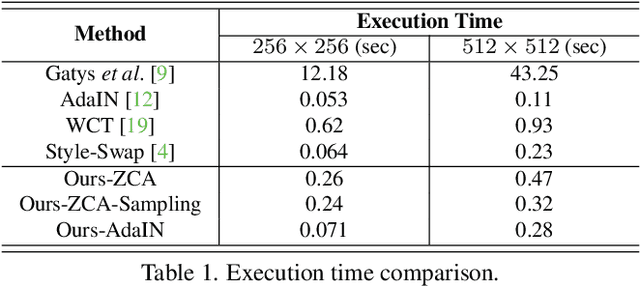



Zero-shot artistic style transfer is an important image synthesis problem aiming at transferring arbitrary style into content images. However, the trade-off between the generalization and efficiency in existing methods impedes a high quality zero-shot style transfer in real-time. In this paper, we resolve this dilemma and propose an efficient yet effective Avatar-Net that enables visually plausible multi-scale transfer for arbitrary style. The key ingredient of our method is a style decorator that makes up the content features by semantically aligned style features from an arbitrary style image, which does not only holistically match their feature distributions but also preserve detailed style patterns in the decorated features. By embedding this module into an image reconstruction network that fuses multi-scale style abstractions, the Avatar-Net renders multi-scale stylization for any style image in one feed-forward pass. We demonstrate the state-of-the-art effectiveness and efficiency of the proposed method in generating high-quality stylized images, with a series of applications include multiple style integration, video stylization and etc.
Lehmer Transform and its Theoretical Properties
May 13, 2018
We propose a new class of transforms that we call {\it Lehmer Transform} which is motivated by the {\it Lehmer mean function}. The proposed {\it Lehmer transform} decomposes a function of a sample into their constituting statistical moments. Theoretical properties of the proposed transform are presented. This transform could be very useful to provide an alternative method in analyzing non-stationary signals such as brain wave EEG.