 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAT: Neuron-Based Early Exit for Large Reasoning Models
Feb 02, 2026Large Reasoning Models (LRMs) often suffer from \emph{overthinking}, a phenomenon in which redundant reasoning steps are generated after a correct solution has already been reached. Existing early reasoning exit methods primarily rely on output-level heuristics or trained probing models to skip redundant reasoning steps, thereby mitigating overthinking. However, these approaches typically require additional rollout computation or externally labeled datasets. In this paper, we propose \textbf{NEAT}, a \textbf{N}euron-based \textbf{E}arly re\textbf{A}soning exi\textbf{T} framework that monitors neuron-level activation dynamics to enable training-free early exits, without introducing additional test-time computation. NEAT identifies exit-associated neurons and tracks their activation patterns during reasoning to dynamically trigger early exit or suppress reflection, thereby reducing unnecessary reasoning while preserving solution quality. Experiments on four reasoning benchmarks across six models with different scales and architectures show that, for each model, NEAT achieves an average token reduction of 22\% to 28\% when averaged over the four benchmarks, while maintaining accuracy.
DEEPMED: Building a Medical DeepResearch Agent via Multi-hop Med-Search Data and Turn-Controlled Agentic Training & Inference
Jan 26, 2026Medical reasoning models remain constrained by parametric knowledge and are thus susceptible to forgetting and hallucinations. DeepResearch (DR) models ground outputs in verifiable evidence from tools and perform strongly in general domains, but their direct transfer to medical field yields relatively limited gains. We attribute this to two gaps: task characteristic and tool-use scaling. Medical questions require evidence interpretation in a knowledge-intensive clinical context; while general DR models can retrieve information, they often lack clinical-context reasoning and thus "find it but fail to use it," leaving performance limited by medical abilities. Moreover, in medical scenarios, blindly scaling tool-call can inject noisy context, derailing sensitive medical reasoning and prompting repetitive evidence-seeking along incorrect paths. Therefore, we propose DeepMed. For data, we deploy a multi-hop med-search QA synthesis method supporting the model to apply the DR paradigm in medical contexts. For training, we introduce a difficulty-aware turn-penalty to suppress excessive tool-call growth. For inference, we bring a monitor to help validate hypotheses within a controlled number of steps and avoid context rot. Overall, on seven medical benchmarks, DeepMed improves its base model by 9.79\% on average and outperforms larger medical reasoning and DR models.
ES4R: Speech Encoding Based on Prepositive Affective Modeling for Empathetic Response Generation
Jan 16, 2026Empathetic speech dialogue requires not only understanding linguistic content but also perceiving rich paralinguistic information such as prosody, tone, and emotional intensity for affective understandings. Existing speech-to-speech large language models either rely on ASR transcription or use encoders to extract latent representations, often weakening affective information and contextual coherence in multi-turn dialogues. To address this, we propose \textbf{ES4R}, a framework for speech-based empathetic response generation. Our core innovation lies in explicitly modeling structured affective context before speech encoding, rather than relying on implicit learning by the encoder or explicit emotion supervision. Specifically, we introduce a dual-level attention mechanism to capture turn-level affective states and dialogue-level affective dynamics. The resulting affective representations are then integrated with textual semantics through speech-guided cross-modal attention to generate empathetic responses. For speech output, we employ energy-based strategy selection and style fusion to achieve empathetic speech synthesis. ES4R consistently outperforms strong baselines in both automatic and human evaluations and remains robust across different LLM backbones.
PlaM: Training-Free Plateau-Guided Model Merging for Better Visual Grounding in MLLMs
Jan 12, 2026Multimodal Large Language Models (MLLMs) rely on strong linguistic reasoning inherited from their base language models. However, multimodal instruction fine-tuning paradoxically degrades this text's reasoning capability, undermining multimodal performance. To address this issue, we propose a training-free framework to mitigate this degradation. Through layer-wise vision token masking, we reveal a common three-stage pattern in multimodal large language models: early-modal separation, mid-modal alignment, and late-modal degradation. By analyzing the behavior of MLLMs at different stages, we propose a plateau-guided model merging method that selectively injects base language model parameters into MLLMs. Experimental results based on five MLLMs on nine benchmarks demonstrate the effectiveness of our method. Attention-based analysis further reveals that merging shifts attention from diffuse, scattered patterns to focused localization on task-relevant visual regions. Our repository is on https://github.com/wzj1718/PlaM.
CIRAG: Construction-Integration Retrieval and Adaptive Generation for Multi-hop Question Answering
Jan 11, 2026Triple-based Iterative Retrieval-Augmented Generation (iRAG) mitigates document-level noise for multi-hop question answering. However, existing methods still face limitations: (i) greedy single-path expansion, which propagates early errors and fails to capture parallel evidence from different reasoning branches, and (ii) granularity-demand mismatch, where a single evidence representation struggles to balance noise control with contextual sufficiency. In this paper, we propose the Construction-Integration Retrieval and Adaptive Generation model, CIRAG. It introduces an Iterative Construction-Integration module that constructs candidate triples and history-conditionally integrates them to distill core triples and generate the next-hop query. This module mitigates the greedy trap by preserving multiple plausible evidence chains. Besides, we propose an Adaptive Cascaded Multi-Granularity Generation module that progressively expands contextual evidence based on the problem requirements, from triples to supporting sentences and full passages. Moreover, we introduce Trajectory Distillation, which distills the teacher model's integration policy into a lightweight student, enabling efficient and reliable long-horizon reasoning. Extensive experiments demonstrate that CIRAG achieves superior performance compared to existing iRAG methods.
SAFE-QAQ: End-to-End Slow-Thinking Audio-Text Fraud Detection via Reinforcement Learning
Jan 04, 2026Existing fraud detection methods predominantly rely on transcribed text, suffering from ASR errors and missing crucial acoustic cues like vocal tone and environmental context. This limits their effectiveness against complex deceptive strategies. To address these challenges, we first propose \textbf{SAFE-QAQ}, an end-to-end comprehensive framework for audio-based slow-thinking fraud detection. First, the SAFE-QAQ framework eliminates the impact of transcription errors on detection performance. Secondly, we propose rule-based slow-thinking reward mechanisms that systematically guide the system to identify fraud-indicative patterns by accurately capturing fine-grained audio details, through hierarchical reasoning processes. Besides, our framework introduces a dynamic risk assessment framework during live calls, enabling early detection and prevention of fraud. Experiments on the TeleAntiFraud-Bench demonstrate that SAFE-QAQ achieves dramatic improvements over existing methods in multiple key dimensions, including accuracy, inference efficiency, and real-time processing capabilities. Currently deployed and analyzing over 70,000 calls daily, SAFE-QAQ effectively automates complex fraud detection, reducing human workload and financial losses. Code: https://anonymous.4open.science/r/SAFE-QAQ.
Resource-Limited Joint Multimodal Sentiment Reasoning and Classification via Chain-of-Thought Enhancement and Distillation
Aug 07, 2025The surge in rich multimodal content on social media platforms has greatly advanced Multimodal Sentiment Analysis (MSA), with Large Language Models (LLMs) further accelerating progress in this field. Current approaches primarily leverage the knowledge and reasoning capabilities of parameter-heavy (Multimodal) LLMs for sentiment classification, overlooking autonomous multimodal sentiment reasoning generation in resource-constrained environments. Therefore, we focus on the Resource-Limited Joint Multimodal Sentiment Reasoning and Classification task, JMSRC, which simultaneously performs multimodal sentiment reasoning chain generation and sentiment classification only with a lightweight model. We propose a Multimodal Chain-of-Thought Reasoning Distillation model, MulCoT-RD, designed for JMSRC that employs a "Teacher-Assistant-Student" distillation paradigm to address deployment constraints in resource-limited environments. We first leverage a high-performance Multimodal Large Language Model (MLLM) to generate the initial reasoning dataset and train a medium-sized assistant model with a multi-task learning mechanism. A lightweight student model is jointly trained to perform efficient multimodal sentiment reasoning generation and classification. Extensive experiments on four datasets demonstrate that MulCoT-RD with only 3B parameters achieves strong performance on JMSRC, while exhibiting robust generalization and enhanced interpretability.
Why Do More Experts Fail? A Theoretical Analysis of Model Merging
May 27, 2025



Model merging dramatically reduces storage and computational resources by combining multiple expert models into a single multi-task model. Although recent model merging methods have shown promising results, they struggle to maintain performance gains as the number of merged models increases. In this paper, we investigate the key obstacles that limit the scalability of model merging when integrating a large number of expert models. First, we prove that there is an upper bound on model merging. Further theoretical analysis reveals that the limited effective parameter space imposes a strict constraint on the number of models that can be successfully merged. Gaussian Width shows that the marginal benefit of merging additional models diminishes according to a strictly concave function. This implies that the effective parameter space becomes rapidly saturated as the number of merged models increases. Furthermore, using Approximate Kinematics Theory, we prove the existence of a unique optimal threshold beyond which adding more models does not yield significant performance improvements. At the same time, we introduce a straightforward Reparameterized Heavy-Tailed method (RHT) to extend the coverage of the merged model, thereby enhancing its performance. Empirical results on 12 benchmarks, including both knowledge-intensive and general-purpose tasks, validate our theoretical analysis. We believe that these results spark further research beyond the current scope of model merging. The source code is in the anonymous Github repository https://github.com/wzj1718/ModelMergingAnalysis.
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
May 26, 2025
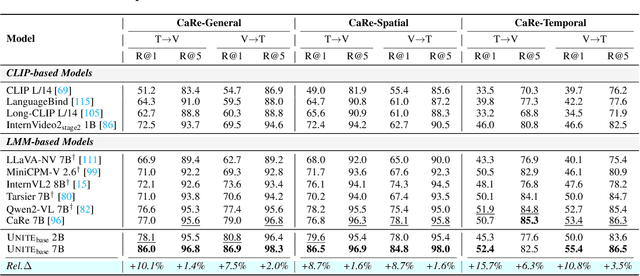

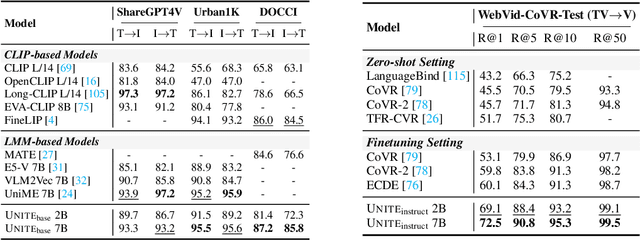
Multimodal information retrieval (MIR) faces inherent challenges due to the heterogeneity of data sources and the complexity of cross-modal alignment. While previous studies have identified modal gaps in feature spaces, a systematic approach to address these challenges remains unexplored. In this work, we introduce UNITE, a universal framework that tackles these challenges through two critical yet underexplored aspects: data curation and modality-aware training configurations. Our work provides the first comprehensive analysis of how modality-specific data properties influence downstream task performance across diverse scenarios. Moreover, we propose Modal-Aware Masked Contrastive Learning (MAMCL) to mitigate the competitive relationships among the instances of different modalities. Our framework achieves state-of-the-art results on multiple multimodal retrieval benchmarks, outperforming existing methods by notable margins. Through extensive experiments, we demonstrate that strategic modality curation and tailored training protocols are pivotal for robust cross-modal representation learning. This work not only advances MIR performance but also provides a foundational blueprint for future research in multimodal systems. Our project is available at https://friedrichor.github.io/projects/UNITE.
Enhancing LLM-based Recommendation through Semantic-Aligned Collaborative Knowledge
Apr 14, 2025Large Language Models (LLMs) demonstrate remarkable capabilities in leveraging comprehensive world knowledge and sophisticated reasoning mechanisms for recommendation tasks. However, a notable limitation lies in their inability to effectively model sparse identifiers (e.g., user and item IDs), unlike conventional collaborative filtering models (Collabs.), thus hindering LLM to learn distinctive user-item representations and creating a performance bottleneck. Prior studies indicate that integrating collaborative knowledge from Collabs. into LLMs can mitigate the above limitations and enhance their recommendation performance. Nevertheless, the significant discrepancy in knowledge distribution and semantic space between LLMs and Collab. presents substantial challenges for effective knowledge transfer. To tackle these challenges, we propose a novel framework, SeLLa-Rec, which focuses on achieving alignment between the semantic spaces of Collabs. and LLMs. This alignment fosters effective knowledge fusion, mitigating the influence of discriminative noise and facilitating the deep integration of knowledge from diverse models. Specifically, three special tokens with collaborative knowledge are embedded into the LLM's semantic space through a hybrid projection layer and integrated into task-specific prompts to guide the recommendation process. Experiments conducted on two public benchmark datasets (MovieLens-1M and Amazon Book) demonstrate that SeLLa-Rec achieves state-of-the-art performance.