 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebTestBench: Evaluating Computer-Use Agents towards End-to-End Automated Web Testing
Mar 26, 2026The emergence of Large Language Models (LLMs) has catalyzed a paradigm shift in programming, giving rise to "vibe coding", where users can build complete projects and even control computers using natural language instructions. This paradigm has driven automated webpage development, but it introduces a new requirement about how to automatically verify whether the web functionalities are reliably implemented. Existing works struggle to adapt, relying on static visual similarity or predefined checklists that constrain their utility in open-ended environments. Furthermore, they overlook a vital aspect of software quality, namely latent logical constraints. To address these gaps, we introduce WebTestBench, a benchmark for evaluating end-to-end automated web testing. WebTestBench encompasses comprehensive dimensions across diverse web application categories. We decompose the testing process into two cascaded sub-tasks, checklist generation and defect detection, and propose WebTester, a baseline framework for this task. Evaluating popular LLMs with WebTester reveals severe challenges, including insufficient test completeness, detection bottlenecks, and long-horizon interaction unreliability. These findings expose a substantial gap between current computer-use agent capabilities and industrial-grade deployment demands. We hope that WebTestBench provides valuable insights and guidance for advancing end-to-end automated web testing. Our dataset and code are available at https://github.com/friedrichor/WebTestBench.
Accelerating Diffusion LLM Inference via Local Determinism Propagation
Oct 08, 2025Diffusion large language models (dLLMs) represent a significant advancement in text generation, offering parallel token decoding capabilities. However, existing open-source implementations suffer from quality-speed trade-offs that impede their practical deployment. Conservative sampling strategies typically decode only the most confident token per step to ensure quality (i.e., greedy decoding), at the cost of inference efficiency due to repeated redundant refinement iterations--a phenomenon we term delayed decoding. Through systematic analysis of dLLM decoding dynamics, we characterize this delayed decoding behavior and propose a training-free adaptive parallel decoding strategy, named LocalLeap, to address these inefficiencies. LocalLeap is built on two fundamental empirical principles: local determinism propagation centered on high-confidence anchors and progressive spatial consistency decay. By applying these principles, LocalLeap identifies anchors and performs localized relaxed parallel decoding within bounded neighborhoods, achieving substantial inference step reduction through early commitment of already-determined tokens without compromising output quality. Comprehensive evaluation on various benchmarks demonstrates that LocalLeap achieves 6.94$\times$ throughput improvements and reduces decoding steps to just 14.2\% of the original requirement, achieving these gains with negligible performance impact. The source codes are available at: https://github.com/friedrichor/LocalLeap.
Evaluating Multimodal Large Language Models on Video Captioning via Monte Carlo Tree Search
Jun 11, 2025Video captioning can be used to assess the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, existing benchmarks and evaluation protocols suffer from crucial issues, such as inadequate or homogeneous creation of key points, exorbitant cost of data creation, and limited evaluation scopes. To address these issues, we propose an automatic framework, named AutoCaption, which leverages Monte Carlo Tree Search (MCTS) to construct numerous and diverse descriptive sentences (\textit{i.e.}, key points) that thoroughly represent video content in an iterative way. This iterative captioning strategy enables the continuous enhancement of video details such as actions, objects' attributes, environment details, etc. We apply AutoCaption to curate MCTS-VCB, a fine-grained video caption benchmark covering video details, thereby enabling a comprehensive evaluation of MLLMs on the video captioning task. We evaluate more than 20 open- and closed-source MLLMs of varying sizes on MCTS-VCB. Results show that MCTS-VCB can effectively and comprehensively evaluate the video captioning capability, with Gemini-1.5-Pro achieving the highest F1 score of 71.2. Interestingly, we fine-tune InternVL2.5-8B with the AutoCaption-generated data, which helps the model achieve an overall improvement of 25.0% on MCTS-VCB and 16.3% on DREAM-1K, further demonstrating the effectiveness of AutoCaption. The code and data are available at https://github.com/tjunlp-lab/MCTS-VCB.
TUNA: Comprehensive Fine-grained Temporal Understanding Evaluation on Dense Dynamic Videos
May 26, 2025Videos are unique in their integration of temporal elements, including camera, scene, action, and attribute, along with their dynamic relationships over time. However, existing benchmarks for video understanding often treat these properties separately or narrowly focus on specific aspects, overlooking the holistic nature of video content. To address this, we introduce TUNA, a temporal-oriented benchmark for fine-grained understanding on dense dynamic videos, with two complementary tasks: captioning and QA. Our TUNA features diverse video scenarios and dynamics, assisted by interpretable and robust evaluation criteria. We evaluate several leading models on our benchmark, providing fine-grained performance assessments across various dimensions. This evaluation reveals key challenges in video temporal understanding, such as limited action description, inadequate multi-subject understanding, and insensitivity to camera motion, offering valuable insights for improving video understanding models. The data and code are available at https://friedrichor.github.io/projects/TUNA.
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
May 26, 2025
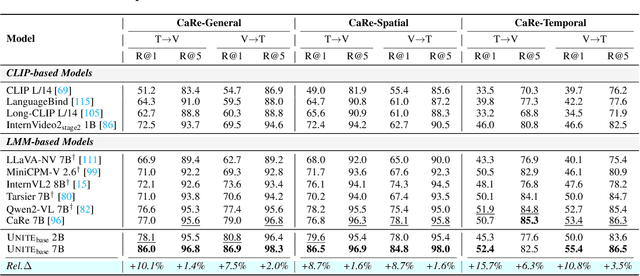

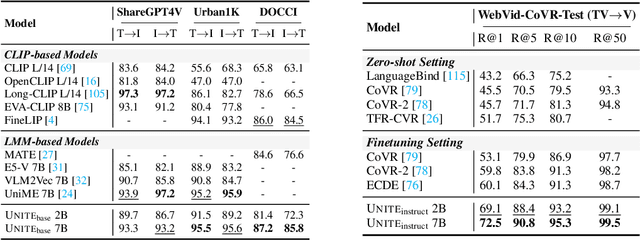
Multimodal information retrieval (MIR) faces inherent challenges due to the heterogeneity of data sources and the complexity of cross-modal alignment. While previous studies have identified modal gaps in feature spaces, a systematic approach to address these challenges remains unexplored. In this work, we introduce UNITE, a universal framework that tackles these challenges through two critical yet underexplored aspects: data curation and modality-aware training configurations. Our work provides the first comprehensive analysis of how modality-specific data properties influence downstream task performance across diverse scenarios. Moreover, we propose Modal-Aware Masked Contrastive Learning (MAMCL) to mitigate the competitive relationships among the instances of different modalities. Our framework achieves state-of-the-art results on multiple multimodal retrieval benchmarks, outperforming existing methods by notable margins. Through extensive experiments, we demonstrate that strategic modality curation and tailored training protocols are pivotal for robust cross-modal representation learning. This work not only advances MIR performance but also provides a foundational blueprint for future research in multimodal systems. Our project is available at https://friedrichor.github.io/projects/UNITE.
Is Mamba Effective for Time Series Forecasting?
Mar 17, 2024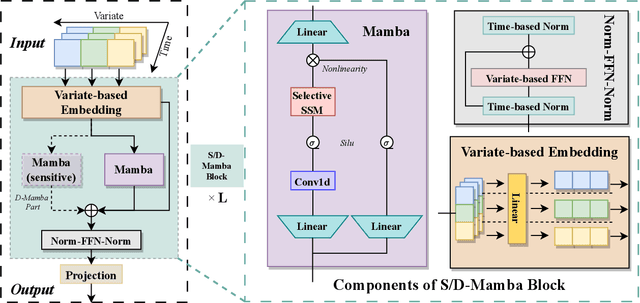
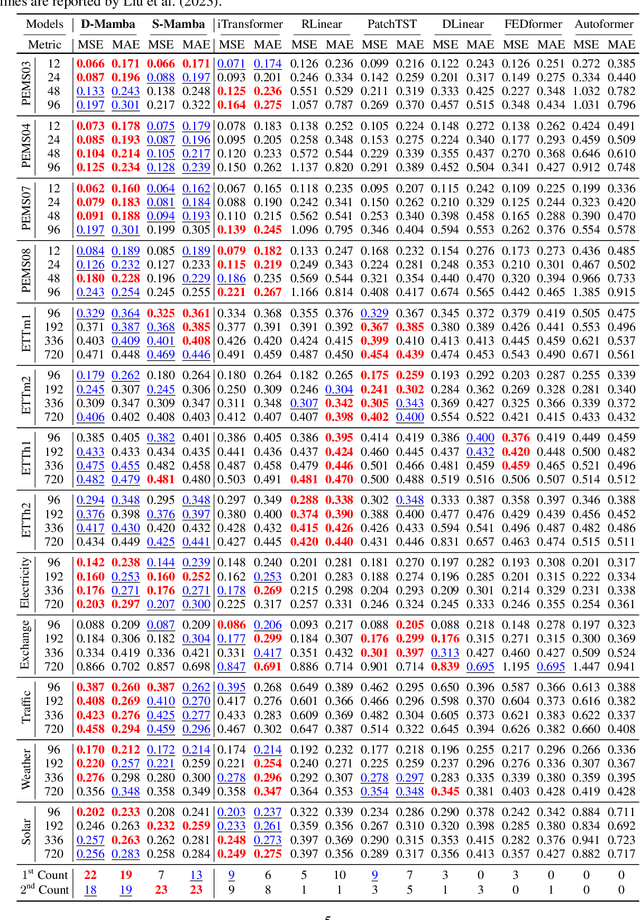
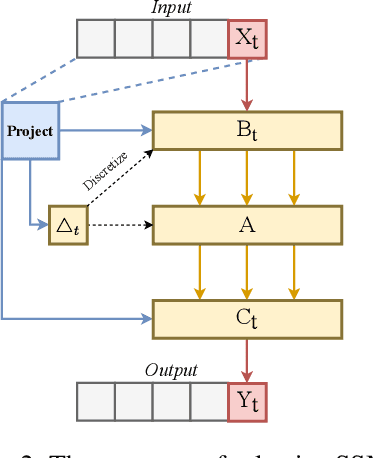
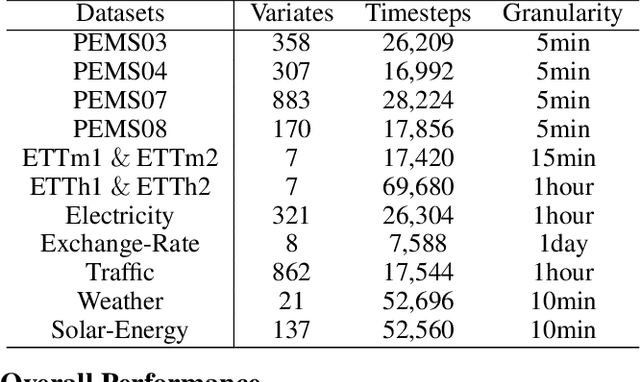
In the realm of time series forecasting (TSF), the Transformer has consistently demonstrated robust performance due to its ability to focus on the global context and effectively capture long-range dependencies within time, as well as discern correlations between multiple variables. However, due to the inefficiencies of the Transformer model and questions surrounding its ability to capture dependencies, ongoing efforts to refine the Transformer architecture persist. Recently, state space models (SSMs), e.g. Mamba, have gained traction due to their ability to capture complex dependencies in sequences, similar to the Transformer, while maintaining near-linear complexity. In text and image tasks, Mamba-based models can improve performance and cost savings, creating a win-win situation. This has piqued our interest in exploring SSM's potential in TSF tasks. In this paper, we introduce two straightforward SSM-based models for TSF, S-Mamba and D-Mamba, both employing the Mamba Block to extract variate correlations. Remarkably, S-Mamba and D-Mamba achieve superior performance while saving GPU memory and training time. Furthermore, we conduct extensive experiments to delve deeper into the potential of Mamba compared to the Transformer in the TSF, aiming to explore a new research direction for this field. Our code is available at https://github.com/wzhwzhwzh0921/S-D-Mamba.
StickerConv: Generating Multimodal Empathetic Responses from Scratch
Jan 20, 2024Stickers, while widely recognized for enhancing empathetic communication in online interactions, remain underexplored in current empathetic dialogue research. In this paper, we introduce the Agent for StickerConv (Agent4SC), which uses collaborative agent interactions to realistically simulate human behavior with sticker usage, thereby enhancing multimodal empathetic communication. Building on this foundation, we develop a multimodal empathetic dialogue dataset, StickerConv, which includes 12.9K dialogue sessions, 5.8K unique stickers, and 2K diverse conversational scenarios, specifically designs to augment the generation of empathetic responses in a multimodal context. To leverage the richness of this dataset, we propose PErceive and Generate Stickers (PEGS), a multimodal empathetic response generation model, complemented by a comprehensive set of empathy evaluation metrics based on LLM. Our experiments demonstrate PEGS's effectiveness in generating contextually relevant and emotionally resonant multimodal empathetic responses, contributing to the advancement of more nuanced and engaging empathetic dialogue systems. Our project page is available at https://neu-datamining.github.io/StickerConv .