 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022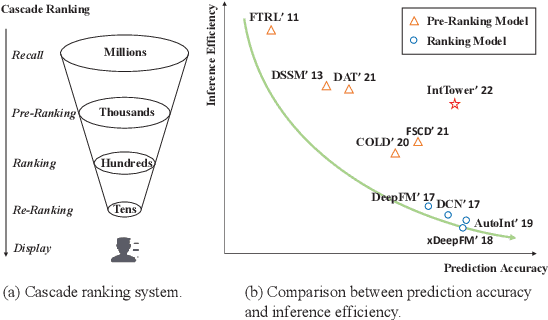
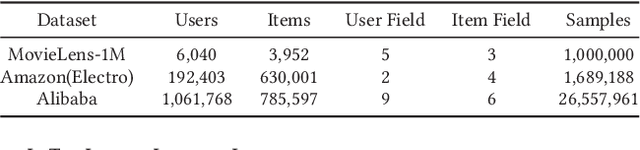
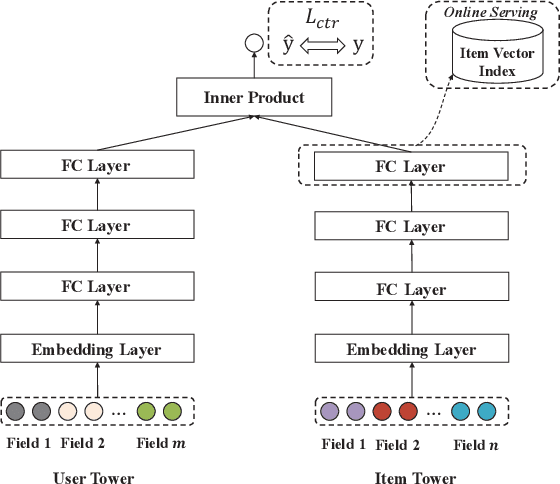
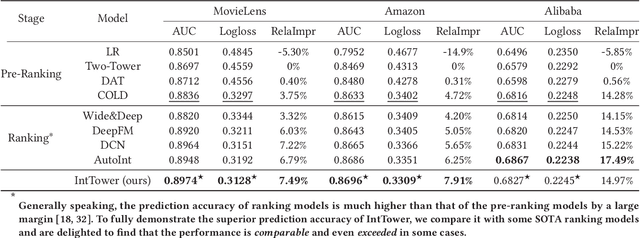
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}
U-HRNet: Delving into Improving Semantic Representation of High Resolution Network for Dense Prediction
Oct 13, 2022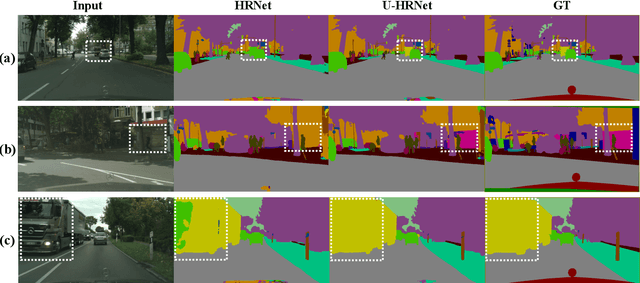

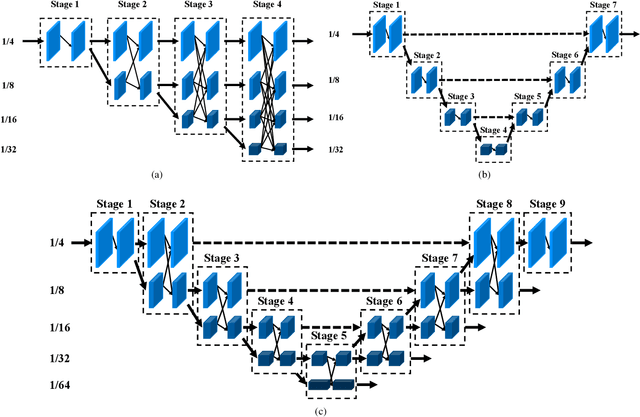
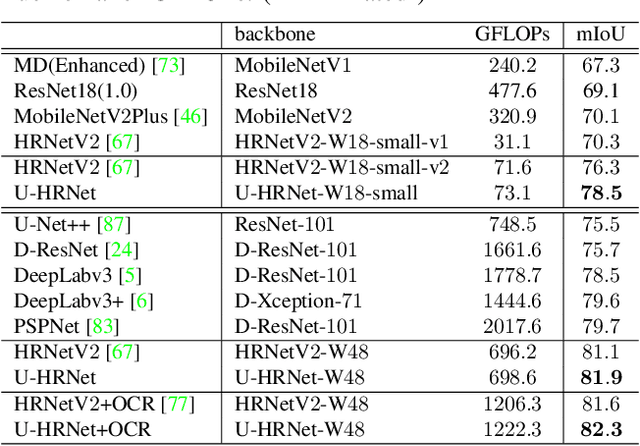
High resolution and advanced semantic representation are both vital for dense prediction. Empirically, low-resolution feature maps often achieve stronger semantic representation, and high-resolution feature maps generally can better identify local features such as edges, but contains weaker semantic information. Existing state-of-the-art frameworks such as HRNet has kept low-resolution and high-resolution feature maps in parallel, and repeatedly exchange the information across different resolutions. However, we believe that the lowest-resolution feature map often contains the strongest semantic information, and it is necessary to go through more layers to merge with high-resolution feature maps, while for high-resolution feature maps, the computational cost of each convolutional layer is very large, and there is no need to go through so many layers. Therefore, we designed a U-shaped High-Resolution Network (U-HRNet), which adds more stages after the feature map with strongest semantic representation and relaxes the constraint in HRNet that all resolutions need to be calculated parallel for a newly added stage. More calculations are allocated to low-resolution feature maps, which significantly improves the overall semantic representation. U-HRNet is a substitute for the HRNet backbone and can achieve significant improvement on multiple semantic segmentation and depth prediction datasets, under the exactly same training and inference setting, with almost no increasing in the amount of calculation. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
Neural-FacTOR: Neural Representation Learning for Website Fingerprinting Attack over TOR Anonymity
Sep 26, 2022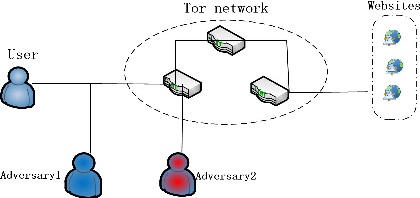
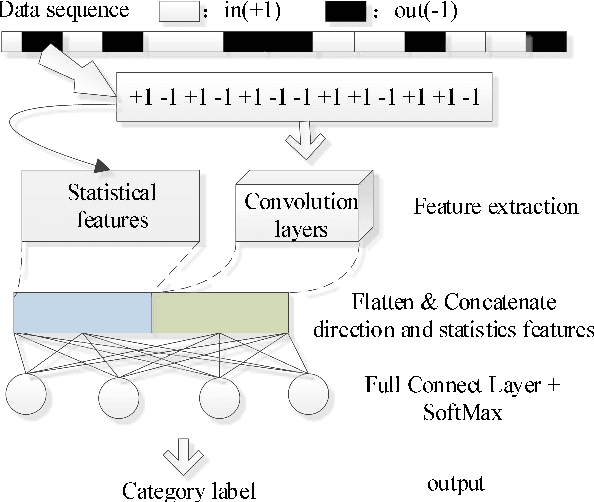
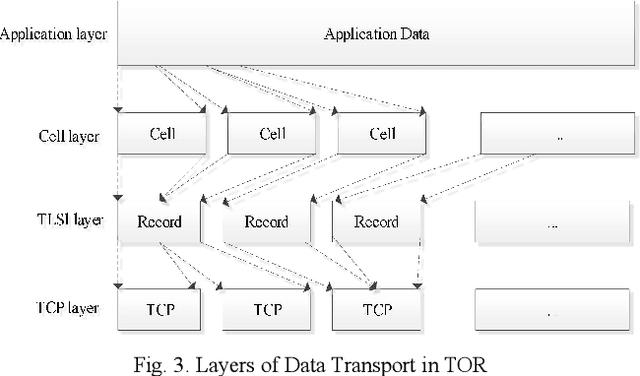
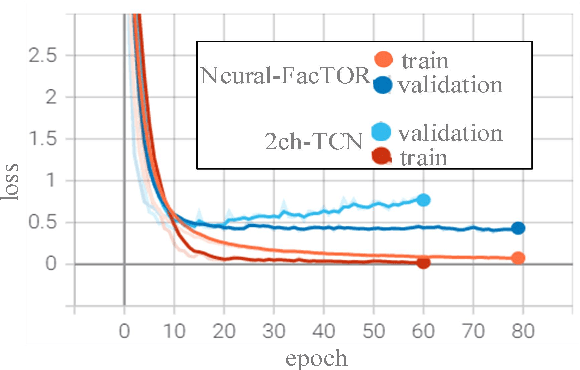
TOR (The Onion Router) network is a widely used open source anonymous communication tool, the abuse of TOR makes it difficult to monitor the proliferation of online crimes such as to access criminal websites. Most existing approches for TOR network de-anonymization heavily rely on manually extracted features resulting in time consuming and poor performance. To tackle the shortcomings, this paper proposes a neural representation learning approach to recognize website fingerprint based on classification algorithm. We constructed a new website fingerprinting attack model based on convolutional neural network (CNN) with dilation and causal convolution, which can improve the perception field of CNN as well as capture the sequential characteristic of input data. Experiments on three mainstream public datasets show that the proposed model is robust and effective for the website fingerprint classification and improves the accuracy by 12.21% compared with the state-of-the-art methods.
Low Resource Style Transfer via Domain Adaptive Meta Learning
May 25, 2022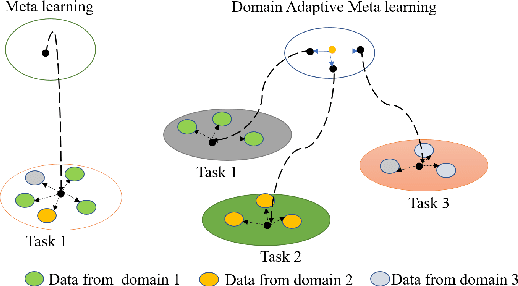
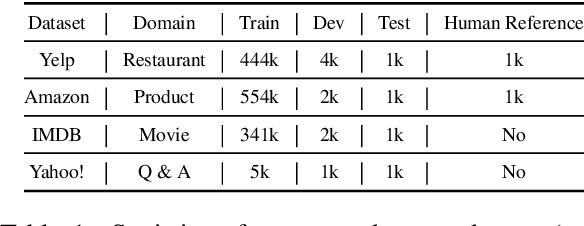
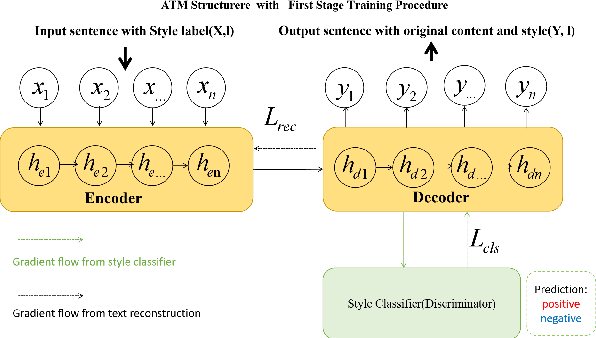
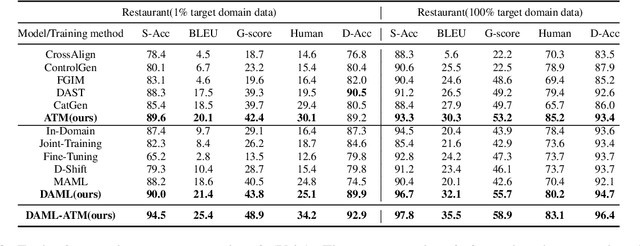
Text style transfer (TST) without parallel data has achieved some practical success. However, most of the existing unsupervised text style transfer methods suffer from (i) requiring massive amounts of non-parallel data to guide transferring different text styles. (ii) colossal performance degradation when fine-tuning the model in new domains. In this work, we propose DAML-ATM (Domain Adaptive Meta-Learning with Adversarial Transfer Model), which consists of two parts: DAML and ATM. DAML is a domain adaptive meta-learning approach to learn general knowledge in multiple heterogeneous source domains, capable of adapting to new unseen domains with a small amount of data. Moreover, we propose a new unsupervised TST approach Adversarial Transfer Model (ATM), composed of a sequence-to-sequence pre-trained language model and uses adversarial style training for better content preservation and style transfer. Results on multi-domain datasets demonstrate that our approach generalizes well on unseen low-resource domains, achieving state-of-the-art results against ten strong baselines.
Dressing in the Wild by Watching Dance Videos
Mar 29, 2022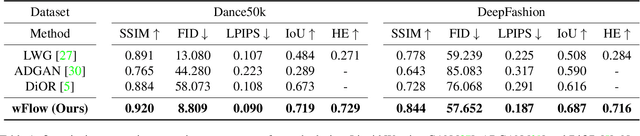
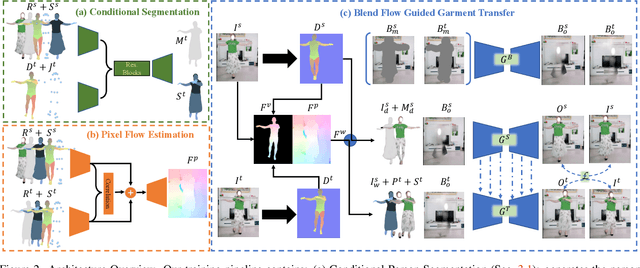
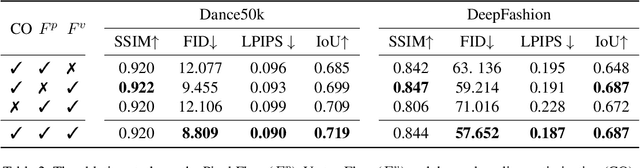
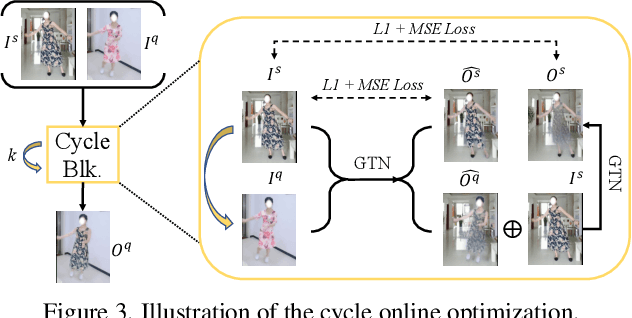
While significant progress has been made in garment transfer, one of the most applicable directions of human-centric image generation, existing works overlook the in-the-wild imagery, presenting severe garment-person misalignment as well as noticeable degradation in fine texture details. This paper, therefore, attends to virtual try-on in real-world scenes and brings essential improvements in authenticity and naturalness especially for loose garment (e.g., skirts, formal dresses), challenging poses (e.g., cross arms, bent legs), and cluttered backgrounds. Specifically, we find that the pixel flow excels at handling loose garments whereas the vertex flow is preferred for hard poses, and by combining their advantages we propose a novel generative network called wFlow that can effectively push up garment transfer to in-the-wild context. Moreover, former approaches require paired images for training. Instead, we cut down the laboriousness by working on a newly constructed large-scale video dataset named Dance50k with self-supervised cross-frame training and an online cycle optimization. The proposed Dance50k can boost real-world virtual dressing by covering a wide variety of garments under dancing poses. Extensive experiments demonstrate the superiority of our wFlow in generating realistic garment transfer results for in-the-wild images without resorting to expensive paired datasets.
PP-YOLOv2: A Practical Object Detector
Apr 21, 2021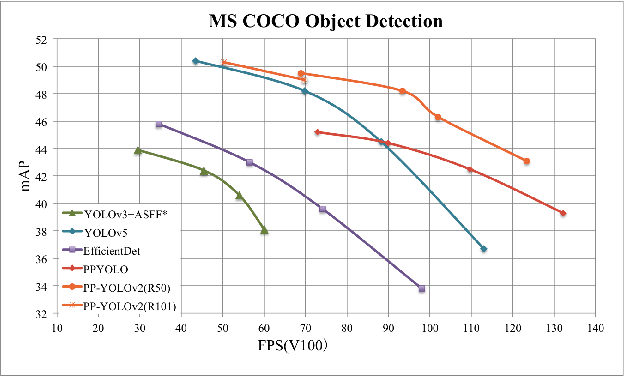

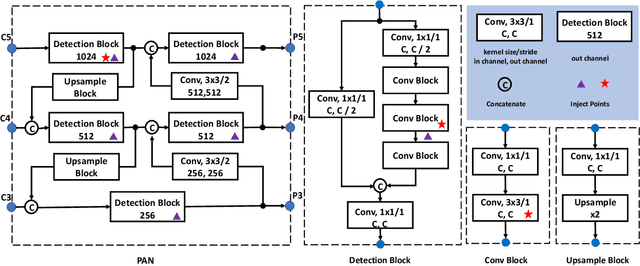
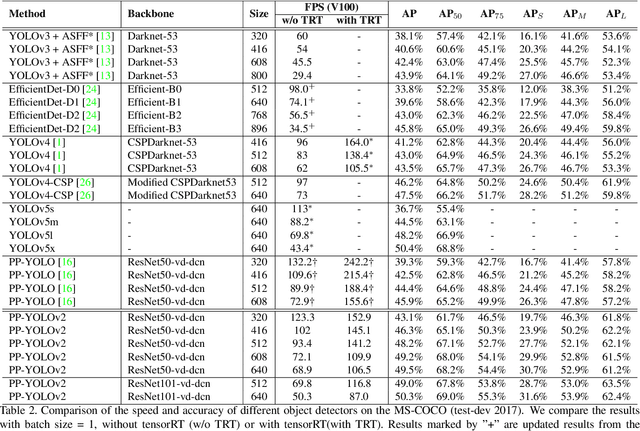
Being effective and efficient is essential to an object detector for practical use. To meet these two concerns, we comprehensively evaluate a collection of existing refinements to improve the performance of PP-YOLO while almost keep the infer time unchanged. This paper will analyze a collection of refinements and empirically evaluate their impact on the final model performance through incremental ablation study. Things we tried that didn't work will also be discussed. By combining multiple effective refinements, we boost PP-YOLO's performance from 45.9% mAP to 49.5% mAP on COCO2017 test-dev. Since a significant margin of performance has been made, we present PP-YOLOv2. In terms of speed, PP-YOLOv2 runs in 68.9FPS at 640x640 input size. Paddle inference engine with TensorRT, FP16-precision, and batch size = 1 further improves PP-YOLOv2's infer speed, which achieves 106.5 FPS. Such a performance surpasses existing object detectors with roughly the same amount of parameters (i.e., YOLOv4-CSP, YOLOv5l). Besides, PP-YOLOv2 with ResNet101 achieves 50.3% mAP on COCO2017 test-dev. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Exploring Text-transformers in AAAI 2021 Shared Task: COVID-19 Fake News Detection in English
Jan 07, 2021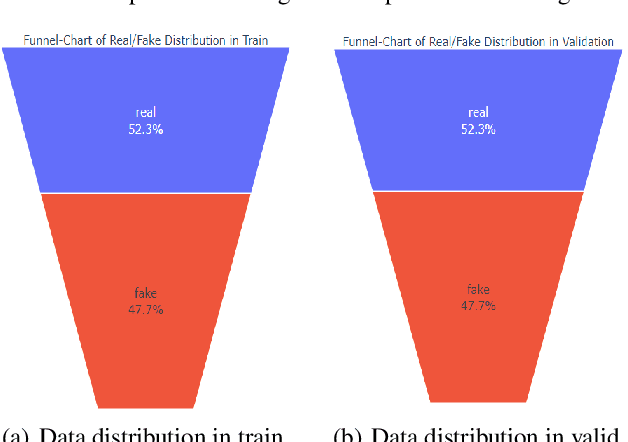
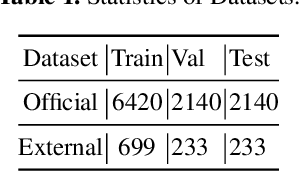

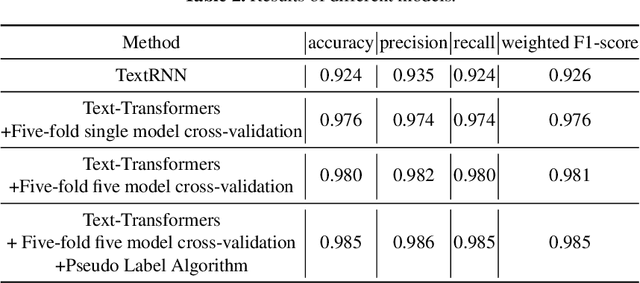
In this paper, we describe our system for the AAAI 2021 shared task of COVID-19 Fake News Detection in English, where we achieved the 3rd position with the weighted F1 score of 0.9859 on the test set. Specifically, we proposed an ensemble method of different pre-trained language models such as BERT, Roberta, Ernie, etc. with various training strategies including warm-up,learning rate schedule and k-fold cross-validation. We also conduct an extensive analysis of the samples that are not correctly classified. The code is available at:https://github.com/archersama/3rd-solution-COVID19-Fake-News-Detection-in-English.
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Aug 03, 2020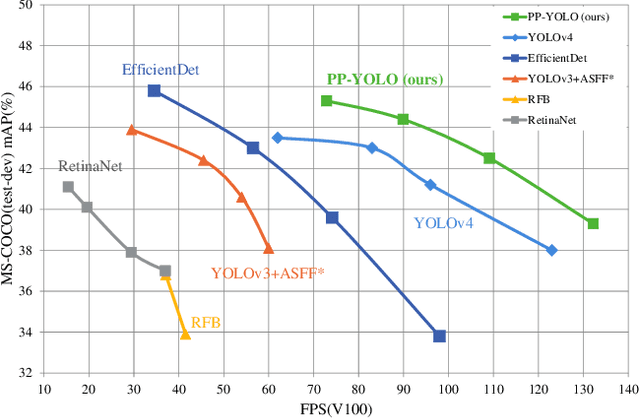
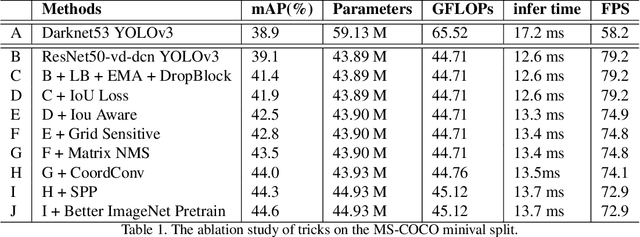
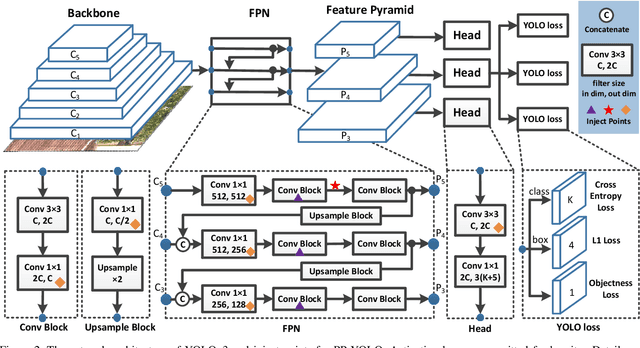
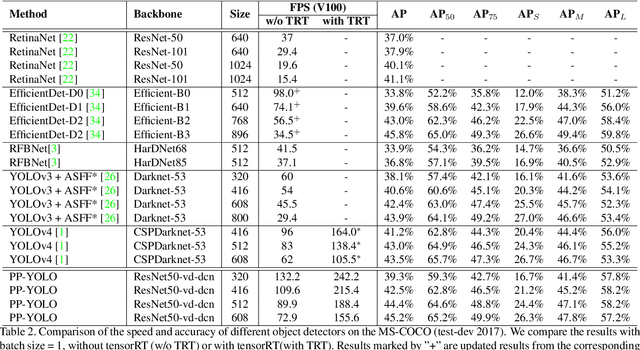
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, we develop a new object detector based on YOLOv3. We mainly try to combine various existing tricks that almost not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, we call it PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4.Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Graph-PCNN: Two Stage Human Pose Estimation with Graph Pose Refinement
Jul 21, 2020
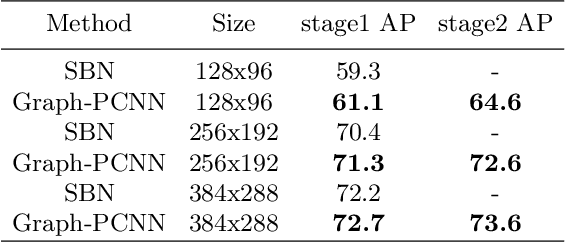
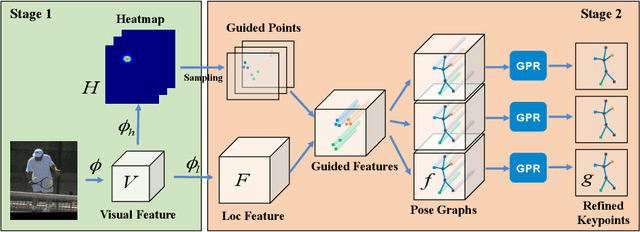
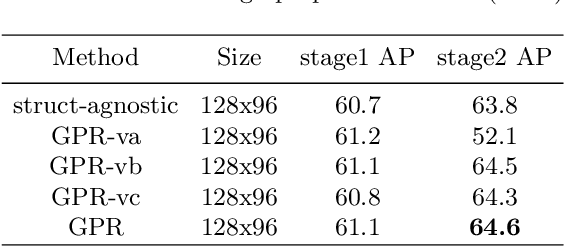
Recently, most of the state-of-the-art human pose estimation methods are based on heatmap regression. The final coordinates of keypoints are obtained by decoding heatmap directly. In this paper, we aim to find a better approach to get more accurate localization results. We mainly put forward two suggestions for improvement: 1) different features and methods should be applied for rough and accurate localization, 2) relationship between keypoints should be considered. Specifically, we propose a two-stage graph-based and model-agnostic framework, called Graph-PCNN, with a localization subnet and a graph pose refinement module added onto the original heatmap regression network. In the first stage, heatmap regression network is applied to obtain a rough localization result, and a set of proposal keypoints, called guided points, are sampled. In the second stage, for each guided point, different visual feature is extracted by the localization subnet. The relationship between guided points is explored by the graph pose refinement module to get more accurate localization results. Experiments show that Graph-PCNN can be used in various backbones to boost the performance by a large margin. Without bells and whistles, our best model can achieve a new state-of-the-art 76.8% AP on COCO test-dev split.
FenceMask: A Data Augmentation Approach for Pre-extracted Image Features
Jun 14, 2020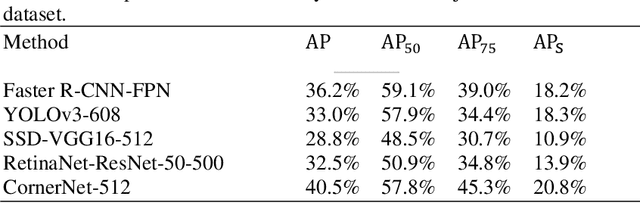


We propose a novel data augmentation method named 'FenceMask' that exhibits outstanding performance in various computer vision tasks. It is based on the 'simulation of object occlusion' strategy, which aim to achieve the balance between object occlusion and information retention of the input data. By enhancing the sparsity and regularity of the occlusion block, our augmentation method overcome the difficulty of small object augmentation and notably improve performance over baselines. Sufficient experiments prove the performance of our method is better than other simulate object occlusion approaches. We tested it on CIFAR10, CIFAR100 and ImageNet datasets for Coarse-grained classification, COCO2017 and VisDrone datasets for detection, Oxford Flowers, Cornel Leaf and Stanford Dogs datasets for Fine-Grained Visual Categorization. Our method achieved significant performance improvement on Fine-Grained Visual Categorization task and VisDrone dataset.