 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Coding Agents via Entropy-Enhanced Multi-Turn Preference Optimization
Sep 15, 2025Software engineering presents complex, multi-step challenges for Large Language Models (LLMs), requiring reasoning over large codebases and coordinated tool use. The difficulty of these tasks is exemplified by benchmarks like SWE-bench, where current LLMs still struggle to resolve real-world issues. A promising approach to enhance performance is test-time scaling (TTS), but its gains are heavily dependent on the diversity of model outputs. While standard alignment methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) are effective at aligning model outputs with human preferences, this process can come at the cost of reduced diversity, limiting the effectiveness of TTS. Additionally, existing preference optimization algorithms are typically designed for single-turn tasks and do not fully address the complexities of multi-turn reasoning and tool integration required for interactive coding agents. To bridge this gap, we introduce \sys, an entropy-enhanced framework that adapts existing preference optimization algorithms to the multi-turn, tool-assisted setting. \sys augments the preference objective to explicitly preserve policy entropy and generalizes learning to optimize over multi-turn interactions rather than single-turn responses. We validate \sys by fine-tuning a diverse suite of models from different families and sizes (up to 106B parameters). To maximize performance gains from TTS, we further propose a hybrid best-trajectory selection scheme combining a learned verifier model with model free approaches. On the \swebench leaderboard, our approach establishes new state-of-the-art results among open-weight models. A 30B parameter model trained with \sys ranks 1st on \lite and 4th on \verified on the open-weight leaderboard, surpassed only by models with over 10x more parameters(\eg$>$350B).
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025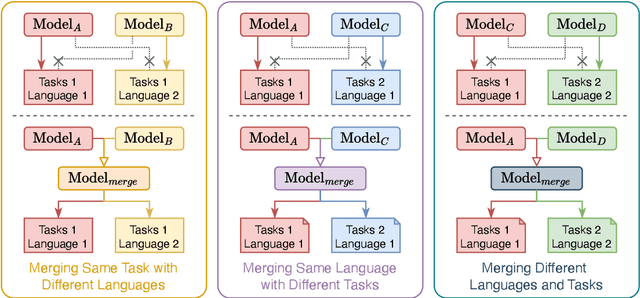
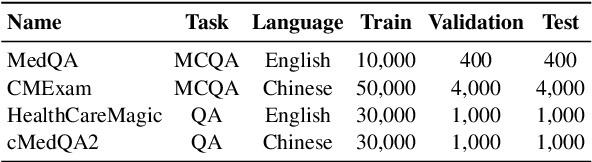
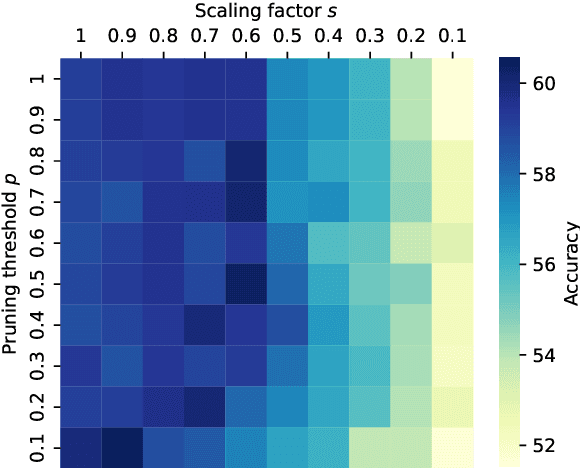
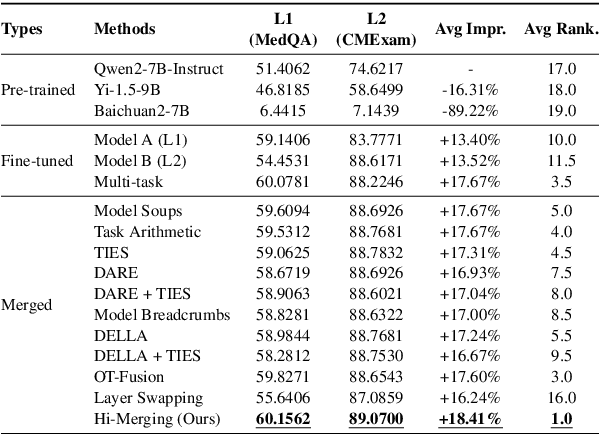
Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures
Model Merging for Knowledge Editing
Jun 14, 2025Large Language Models (LLMs) require continuous updates to maintain accurate and current knowledge as the world evolves. While existing knowledge editing approaches offer various solutions for knowledge updating, they often struggle with sequential editing scenarios and harm the general capabilities of the model, thereby significantly hampering their practical applicability. This paper proposes a two-stage framework combining robust supervised fine-tuning (R-SFT) with model merging for knowledge editing. Our method first fine-tunes the LLM to internalize new knowledge fully, then merges the fine-tuned model with the original foundation model to preserve newly acquired knowledge and general capabilities. Experimental results demonstrate that our approach significantly outperforms existing methods in sequential editing while better preserving the original performance of the model, all without requiring any architectural changes. Code is available at: https://github.com/Applied-Machine-Learning-Lab/MM4KE.
* 11 pages, 3 figures
IQE-CLIP: Instance-aware Query Embedding for Zero-/Few-shot Anomaly Detection in Medical Domain
Jun 12, 2025Recent advances in vision-language models, such as CLIP, have significantly improved performance in zero- and few-shot anomaly detection (ZFSAD) tasks. However, most existing CLIP-based methods assume prior knowledge of categories and rely on carefully designed prompts tailored to specific scenarios. While these text prompts capture semantic information in the textual space, they often fail to distinguish normal and anomalous instances in the joint embedding space. Moreover, most ZFSAD approaches focus on industrial domains, with limited exploration in medical tasks. To address these limitations, we propose IQE-CLIP, a novel framework for ZFSAD in the medical domain. We show that query embeddings integrating both textual and instance-aware visual information serve as more effective indicators of anomalies. Specifically, we introduce class-based and learnable prompting tokens to better adapt CLIP to the medical setting. Furthermore, we design an instance-aware query module that extracts region-level contextual information from both modalities, enabling the generation of anomaly-sensitive embeddings. Extensive experiments on six medical datasets demonstrate that IQE-CLIP achieves state-of-the-art performance in both zero-shot and few-shot settings. Code and data are available at \href{https://github.com/hongh0/IQE-CLIP/}{this https URL}.
The Butterfly Effect in Pathology: Exploring Security in Pathology Foundation Models
May 30, 2025With the widespread adoption of pathology foundation models in both research and clinical decision support systems, exploring their security has become a critical concern. However, despite their growing impact, the vulnerability of these models to adversarial attacks remains largely unexplored. In this work, we present the first systematic investigation into the security of pathology foundation models for whole slide image~(WSI) analysis against adversarial attacks. Specifically, we introduce the principle of \textit{local perturbation with global impact} and propose a label-free attack framework that operates without requiring access to downstream task labels. Under this attack framework, we revise four classical white-box attack methods and redefine the perturbation budget based on the characteristics of WSI. We conduct comprehensive experiments on three representative pathology foundation models across five datasets and six downstream tasks. Despite modifying only 0.1\% of patches per slide with imperceptible noise, our attack leads to downstream accuracy degradation that can reach up to 20\% in the worst cases. Furthermore, we analyze key factors that influence attack success, explore the relationship between patch-level vulnerability and semantic content, and conduct a preliminary investigation into potential defence strategies. These findings lay the groundwork for future research on the adversarial robustness and reliable deployment of pathology foundation models. Our code is publicly available at: https://github.com/Jiashuai-Liu-hmos/Attack-WSI-pathology-foundation-models.
NeuralOM: Neural Ocean Model for Subseasonal-to-Seasonal Simulation
May 27, 2025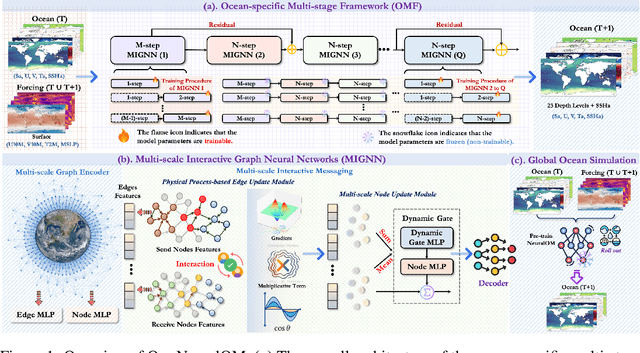
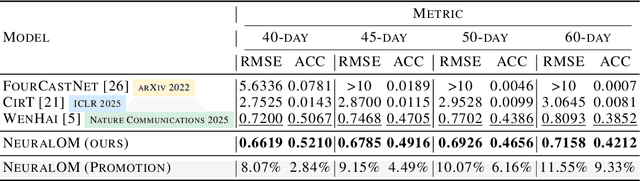
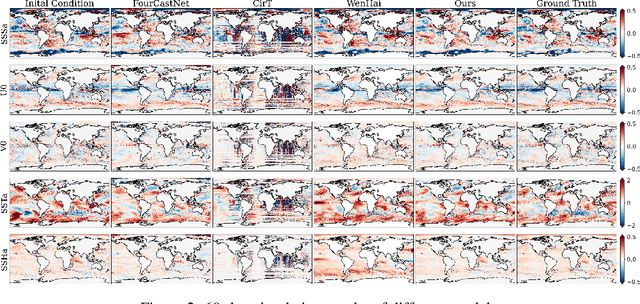
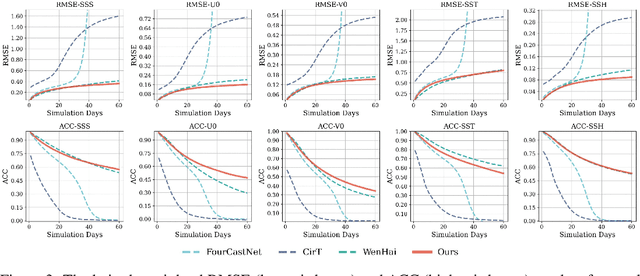
Accurate Subseasonal-to-Seasonal (S2S) ocean simulation is critically important for marine research, yet remains challenging due to its substantial thermal inertia and extended time delay. Machine learning (ML)-based models have demonstrated significant advancements in simulation accuracy and computational efficiency compared to traditional numerical methods. Nevertheless, a significant limitation of current ML models for S2S ocean simulation is their inadequate incorporation of physical consistency and the slow-changing properties of the ocean system. In this work, we propose a neural ocean model (NeuralOM) for S2S ocean simulation with a multi-scale interactive graph neural network to emulate diverse physical phenomena associated with ocean systems effectively. Specifically, we propose a multi-stage framework tailored to model the ocean's slowly changing nature. Additionally, we introduce a multi-scale interactive messaging module to capture complex dynamical behaviors, such as gradient changes and multiplicative coupling relationships inherent in ocean dynamics. Extensive experimental evaluations confirm that our proposed NeuralOM outperforms state-of-the-art models in S2S and extreme event simulation. The codes are available at https://github.com/YuanGao-YG/NeuralOM.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
Turb-L1: Achieving Long-term Turbulence Tracing By Tackling Spectral Bias
May 25, 2025



Accurately predicting the long-term evolution of turbulence is crucial for advancing scientific understanding and optimizing engineering applications. However, existing deep learning methods face significant bottlenecks in long-term autoregressive prediction, which exhibit excessive smoothing and fail to accurately track complex fluid dynamics. Our extensive experimental and spectral analysis of prevailing methods provides an interpretable explanation for this shortcoming, identifying Spectral Bias as the core obstacle. Concretely, spectral bias is the inherent tendency of models to favor low-frequency, smooth features while overlooking critical high-frequency details during training, thus reducing fidelity and causing physical distortions in long-term predictions. Building on this insight, we propose Turb-L1, an innovative turbulence prediction method, which utilizes a Hierarchical Dynamics Synthesis mechanism within a multi-grid architecture to explicitly overcome spectral bias. It accurately captures cross-scale interactions and preserves the fidelity of high-frequency dynamics, enabling reliable long-term tracking of turbulence evolution. Extensive experiments on the 2D turbulence benchmark show that Turb-L1 demonstrates excellent performance: (I) In long-term predictions, it reduces Mean Squared Error (MSE) by $80.3\%$ and increases Structural Similarity (SSIM) by over $9\times$ compared to the SOTA baseline, significantly improving prediction fidelity. (II) It effectively overcomes spectral bias, accurately reproducing the full enstrophy spectrum and maintaining physical realism in high-wavenumber regions, thus avoiding the spectral distortions or spurious energy accumulation seen in other methods.
Think or Not? Exploring Thinking Efficiency in Large Reasoning Models via an Information-Theoretic Lens
May 23, 2025The recent rise of Large Reasoning Models (LRMs) has significantly improved multi-step reasoning performance, but often at the cost of generating excessively long reasoning chains. This paper revisits the efficiency of such reasoning processes through an information-theoretic lens, revealing a fundamental trade-off between reasoning length and semantic efficiency. We propose two metrics, InfoBias and InfoGain, to quantify divergence from ideal reasoning paths and stepwise information contribution, respectively. Empirical analyses show that longer reasoning chains tend to exhibit higher information bias and diminishing information gain, especially for incorrect answers. Motivated by these findings, we introduce an entropy-based Adaptive Think strategy that dynamically halts reasoning once confidence is sufficiently high, improving efficiency while maintaining competitive accuracy. Compared to the Vanilla Think approach (default mode), our strategy yields a 1.10% improvement in average accuracy and a 50.80% reduction in token usage on QwQ-32B across six benchmark tasks spanning diverse reasoning types and difficulty levels, demonstrating superior efficiency and reasoning performance. These results underscore the promise of entropy-based methods for enhancing both accuracy and cost-effiiciency in large language model deployment.