 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-Code Agentic Programming for Agent Harness
Jun 14, 2026Every major LLM agent framework gives the LLM the role of orchestrator; the model decides what to do next, when to call tools, and when to stop. We argue that token explosion, control-flow hallucination, and unreliable completion are not implementation bugs but architectural consequences of assigning the deterministic work of looping, branching, and sequencing to a probabilistic system. A better prompt or a stronger model cannot guarantee the reliability of the LLM agent. We therefore propose Agentic Programming, in which the program governs all control flow, and the LLM is itself part of it, an adaptive component we call LLM-as-Code and invoke only where a task calls for reasoning or generation. Within each call the model keeps full flexibility, but it cannot alter the program's execution path. With control in the program, the LLM's context is built from the execution history's call tree and forms a directed acyclic graph (DAG). Each call's context length is then determined by its call depth rather than by accumulation over steps. A case study of computer-use agents shows that the design is practical, not just a theoretical stance, substantially improving the stability of long visual operation sequences.
AdapTime: Enabling Adaptive Temporal Reasoning in Large Language Models
Apr 27, 2026Large language models have demonstrated strong reasoning capabilities in general knowledge question answering. However, their ability to handle temporal information remains limited. To address this limitation, existing approaches often involve external tools or manual verification and are tailored to specific scenarios, leading to poor generalizability. Moreover, these methods apply a fixed pipeline to all questions, overlooking the fact that different types of temporal questions require distinct reasoning strategies, which leads to unnecessary processing for simple cases and inadequate reasoning for complex ones. To this end, we propose AdapTime, an adaptive temporal reasoning method that dynamically executes reasoning steps based on the input context. Specifically, it involves three temporal reasoning actions: reformulate, rewrite and review, with an LLM planner guiding the reasoning process. AdapTime integrates seamlessly with state-of-the-art LLMs and significantly enhances their temporal reasoning capabilities without relying on external support. Extensive experiments demonstrate the effectiveness of our approach.
MultiDx: A Multi-Source Knowledge Integration Framework towards Diagnostic Reasoning
Apr 27, 2026Diagnostic prediction and clinical reasoning are critical tasks in healthcare applications. While Large Language Models (LLMs) have shown strong capabilities in commonsense reasoning, they still struggle with diagnostic reasoning due to limited domain knowledge. Existing approaches often rely on internal model knowledge or static knowledge bases, resulting in knowledge insufficiency and limited adaptability, which hinder their capacity to perform diagnostic reasoning. Moreover, these methods focus solely on the accuracy of final predictions, overlooking alignment with standard clinical reasoning trajectories. To this end, we propose MultiDx, a two-stage diagnostic reasoning framework that performs differential diagnosis by analyzing evidence collected from multiple knowledge sources. Specifically, it first generates suspected diagnoses and reasoning paths by leveraging knowledge from web search, SOAP-formatted case, and clinical case database. Then it integrates multi-perspective evidence through matching, voting, and differential diagnosis to generate the final prediction.~Extensive experiments on two public benchmarks demonstrate the effectiveness of our approach.
Tandem: Riding Together with Large and Small Language Models for Efficient Reasoning
Apr 26, 2026Recent advancements in large language models (LLMs) have catalyzed the rise of reasoning-intensive inference paradigms, where models perform explicit step-by-step reasoning before generating final answers. While such approaches improve answer quality and interpretability, they incur substantial computational overhead due to the prolonged generation sequences. In this paper, we propose Tandem, a novel collaborative framework that synergizes large and small language models (LLMs and SLMs) to achieve high-quality reasoning with significantly reduced computational cost. Specifically, the LLM serves as a strategic coordinator, efficiently generating a compact set of critical reasoning insights. These insights are then used to guide a smaller, more efficient SLM in executing the full reasoning process and delivering the final response. To balance efficiency and reliability, Tandem introduces a cost-aware termination mechanism that adaptively determines when sufficient reasoning guidance has been accumulated, enabling early stopping of the LLM's generation. Experiments on mathematical reasoning and code generation benchmarks demonstrate that Tandem reduces computational costs by approximately 40% compared to standalone LLM reasoning, while achieving superior or competitive performance. Furthermore, the sufficiency classifier trained on one domain transfers effectively to others without retraining. The code is available at: https://github.com/Applied-Machine-Learning-Lab/ACL2026_Tandem.
Chinese-SkillSpan: A Span-Level Dataset for ESCO-Aligned Competency Extraction from Chinese Job Ads
Apr 24, 2026Job Skill Named Entity Recognition (JobSkillNER) aims to automatically extract key skill information from large-scale job posting data, which is important for improving talent-market matching efficiency and supporting personalized employment services. To the best of our knowledge, this work presents the first Chinese JobSkillNER dataset for recruitment texts. We propose annotation guidelines tailored to Chinese job postings and an LLM-empowered Macro-Micro collaborative annotation pipeline. The pipeline leverages the contextual understanding ability of large language models (LLMs) for initial annotation and then refines the results through expert sentence-level adjudication. Using this pipeline, we annotate more than 20,000 instances collected from four major recruitment platforms over the period 2014-2025. Based on these efforts, we release Chinese-SkillSpan, the first Chinese JobSkillNER dataset aligned with the ESCO occupational skill standard across four dimensions: knowledge, skill, transversal competence, and language competence (LSKT). Experimental results show that the dataset supports effective model training and evaluation, indicating that Chinese-SkillSpan helps fill a major gap in Chinese JobSkillNER resources and provides a useful benchmark for intelligent recruitment research. Code and data are available at https://sites.google.com/view/cn-skillspan-resources .
Job Skill Extraction via LLM-Centric Multi-Module Framework
Apr 23, 2026Span-level skill extraction from job advertisements underpins candidate-job matching and labor-market analytics, yet generative large language models (LLMs) often yield malformed spans, boundary drift, and hallucinations, especially with long-tail terms and cross-domain shift. We present SRICL, an LLM-centric framework that combines semantic retrieval (SR), in-context learning (ICL), and supervised fine-tuning (SFT) with a deterministic verifier. SR pulls in-domain annotated sentences and definitions from ESCO to form format-constrained prompts that stabilize boundaries and handle coordination. SFT aligns output behavior, while the verifier enforces pairing, non-overlap, and BIO legality with minimal retries. On six public span-labeled corpora of job-ad sentences across sectors and languages, SRICL achieves substantial STRICT-F1 improvements over GPT-3.5 prompting baselines and sharply reduces invalid tags and hallucinated spans, enabling dependable sentence-level deployment in low-resource, multi-domain settings.
Attention Needs to Focus: A Unified Perspective on Attention Allocation
Jan 07, 2026The Transformer architecture, a cornerstone of modern Large Language Models (LLMs), has achieved extraordinary success in sequence modeling, primarily due to its attention mechanism. However, despite its power, the standard attention mechanism is plagued by well-documented issues: representational collapse and attention sink. Although prior work has proposed approaches for these issues, they are often studied in isolation, obscuring their deeper connection. In this paper, we present a unified perspective, arguing that both can be traced to a common root -- improper attention allocation. We identify two failure modes: 1) Attention Overload, where tokens receive comparable high weights, blurring semantic features that lead to representational collapse; 2) Attention Underload, where no token is semantically relevant, yet attention is still forced to distribute, resulting in spurious focus such as attention sink. Building on this insight, we introduce Lazy Attention, a novel mechanism designed for a more focused attention distribution. To mitigate overload, it employs positional discrimination across both heads and dimensions to sharpen token distinctions. To counteract underload, it incorporates Elastic-Softmax, a modified normalization function that relaxes the standard softmax constraint to suppress attention on irrelevant tokens. Experiments on the FineWeb-Edu corpus, evaluated across nine diverse benchmarks, demonstrate that Lazy Attention successfully mitigates attention sink and achieves competitive performance compared to both standard attention and modern architectures, while reaching up to 59.58% attention sparsity.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Model Merging for Knowledge Editing
Jun 14, 2025Large Language Models (LLMs) require continuous updates to maintain accurate and current knowledge as the world evolves. While existing knowledge editing approaches offer various solutions for knowledge updating, they often struggle with sequential editing scenarios and harm the general capabilities of the model, thereby significantly hampering their practical applicability. This paper proposes a two-stage framework combining robust supervised fine-tuning (R-SFT) with model merging for knowledge editing. Our method first fine-tunes the LLM to internalize new knowledge fully, then merges the fine-tuned model with the original foundation model to preserve newly acquired knowledge and general capabilities. Experimental results demonstrate that our approach significantly outperforms existing methods in sequential editing while better preserving the original performance of the model, all without requiring any architectural changes. Code is available at: https://github.com/Applied-Machine-Learning-Lab/MM4KE.
* 11 pages, 3 figures
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025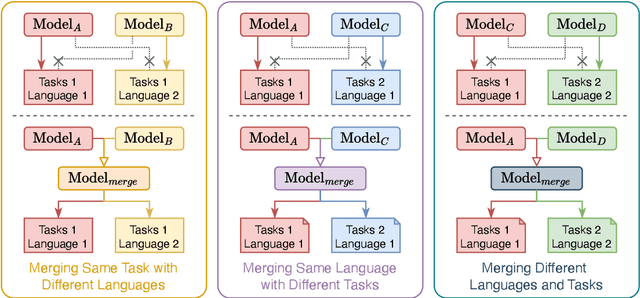
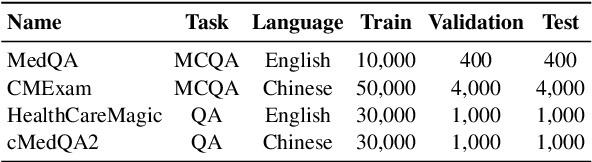
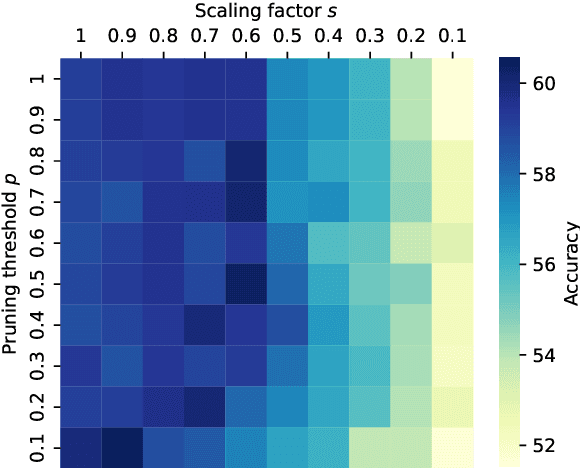
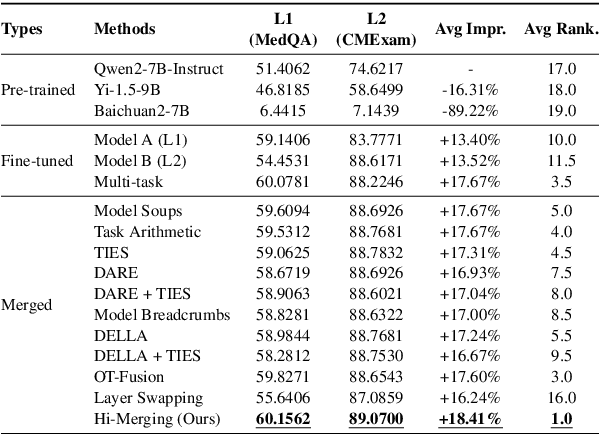
Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures