 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHalDet: A Unified Benchmark for Hallucination Detection across Diverse Generation Scenarios
Jun 05, 2026Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of downstream domains and tasks. Consequently, reported detector performance is often difficult to compare, reproduce, and generalize beyond specific experimental settings. We introduce OpenHalDet, a unified benchmark for hallucination detection across diverse generation scenarios. OpenHalDet standardizes the evaluation pipeline, from prompt construction and response generation to truthfulness annotation, detector scoring, and metric computation. It supports heterogeneous detector families under different access settings, including black-box methods that use only generated outputs, gray-box methods that rely on probability-based signals, and white-box methods that exploit internal model signals. By bringing diverse tasks, models, and detectors into a shared framework, OpenHalDet enables controlled comparison and provides a systematic view of how different detection paradigms behave in LLM applications. We release OpenHalDet as an open and extensible codebase to facilitate reproducible evaluation and future development of hallucination detection methods. The code and datasets are available at https://github.com/Nellie179/Hallucination-Detection.
Declarative Data Services: Structured Agentic Discovery for Composing Data Systems
May 20, 2026Agentic discovery has shown that LLM-driven search can find novel algorithms, designs, and code under benchmark conditions. Translating the paradigm to multi-system data backends surfaces a harder problem: the search space is heterogeneous, the verifier is whether a deployed stack actually runs, and composition knowledge is unevenly captured in pretraining. Unbounded agentic discovery, a coding agent iterating on failure-log feedback, fails to converge consistently on a working stack even when iteration and explicit composition knowledge are added. We propose Declarative Data Services (DDS), an architecture for structured agentic discovery of data-system compositions from declarative user intent. The framework owns four typed contracts at successive layers (intent, operator DAG, per-system skills, runtime attribution) that decompose the global search into bounded sub-searches; sub-agents search each typed space, while the framework provides the channels by which knowledge flows forward as inline skill citations and errors route backward as typed signals. As a proof of life on a trading-backend workload, DDS converges where unbounded discovery does not; runtime failures become skill patches that the next deployment cites inline. We position this as an early prototype reporting lessons from real-world data-system composition.
SubFlow: Sub-mode Conditioned Flow Matching for Diverse One-Step Generation
Apr 14, 2026Flow matching has emerged as a powerful generative framework, with recent few-step methods achieving remarkable inference acceleration. However, we identify a critical yet overlooked limitation: these models suffer from severe diversity degradation, concentrating samples on dominant modes while neglecting rare but valid variations of the target distribution. We trace this degradation to averaging distortion: when trained with MSE objectives, class-conditional flows learn a frequency-weighted mean over intra-class sub-modes, causing the model to over-represent high-density modes while systematically neglecting low-density ones. To address this, we propose SubFlow, Sub-mode Conditioned Flow Matching, which eliminates averaging distortion by decomposing each class into fine-grained sub-modes via semantic clustering and conditioning the flow on sub-mode indices. Each conditioned sub-distribution is approximately unimodal, so the learned flow accurately targets individual modes with no averaging distortion, restoring full mode coverage in a single inference step. Crucially, SubFlow is entirely plug-and-play: it integrates seamlessly into existing one-step models such as MeanFlow and Shortcut Models without any architectural modifications. Extensive experiments on ImageNet-256 demonstrate that SubFlow yields substantial gains in generation diversity (Recall) while maintaining competitive image quality (FID), confirming its broad applicability across different one-step generation frameworks. Project page: https://yexionglin.github.io/subflow.
Is Gradient Ascent Really Necessary? Memorize to Forget for Machine Unlearning
Feb 06, 2026For ethical and safe AI, machine unlearning rises as a critical topic aiming to protect sensitive, private, and copyrighted knowledge from misuse. To achieve this goal, it is common to conduct gradient ascent (GA) to reverse the training on undesired data. However, such a reversal is prone to catastrophic collapse, which leads to serious performance degradation in general tasks. As a solution, we propose model extrapolation as an alternative to GA, which reaches the counterpart direction in the hypothesis space from one model given another reference model. Therefore, we leverage the original model as the reference, further train it to memorize undesired data while keeping prediction consistency on the rest retained data, to obtain a memorization model. Counterfactual as it might sound, a forget model can be obtained via extrapolation from the memorization model to the reference model. Hence, we avoid directly acquiring the forget model using GA, but proceed with gradient descent for the memorization model, which successfully stabilizes the machine unlearning process. Our model extrapolation is simple and efficient to implement, and it can also effectively converge throughout training to achieve improved unlearning performance.
AdLift: Lifting Adversarial Perturbations to Safeguard 3D Gaussian Splatting Assets Against Instruction-Driven Editing
Dec 08, 2025Recent studies have extended diffusion-based instruction-driven 2D image editing pipelines to 3D Gaussian Splatting (3DGS), enabling faithful manipulation of 3DGS assets and greatly advancing 3DGS content creation. However, it also exposes these assets to serious risks of unauthorized editing and malicious tampering. Although imperceptible adversarial perturbations against diffusion models have proven effective for protecting 2D images, applying them to 3DGS encounters two major challenges: view-generalizable protection and balancing invisibility with protection capability. In this work, we propose the first editing safeguard for 3DGS, termed AdLift, which prevents instruction-driven editing across arbitrary views and dimensions by lifting strictly bounded 2D adversarial perturbations into 3D Gaussian-represented safeguard. To ensure both adversarial perturbations effectiveness and invisibility, these safeguard Gaussians are progressively optimized across training views using a tailored Lifted PGD, which first conducts gradient truncation during back-propagation from the editing model at the rendered image and applies projected gradients to strictly constrain the image-level perturbation. Then, the resulting perturbation is backpropagated to the safeguard Gaussian parameters via an image-to-Gaussian fitting operation. We alternate between gradient truncation and image-to-Gaussian fitting, yielding consistent adversarial-based protection performance across different viewpoints and generalizes to novel views. Empirically, qualitative and quantitative results demonstrate that AdLift effectively protects against state-of-the-art instruction-driven 2D image and 3DGS editing.
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025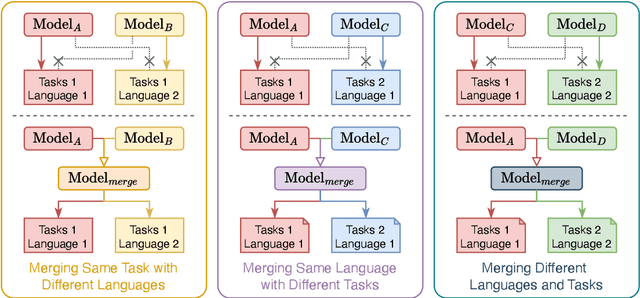
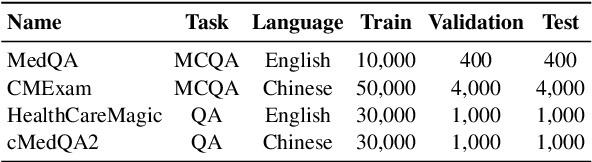
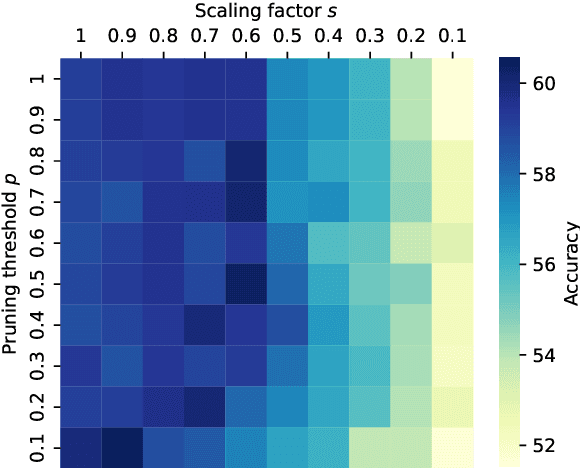
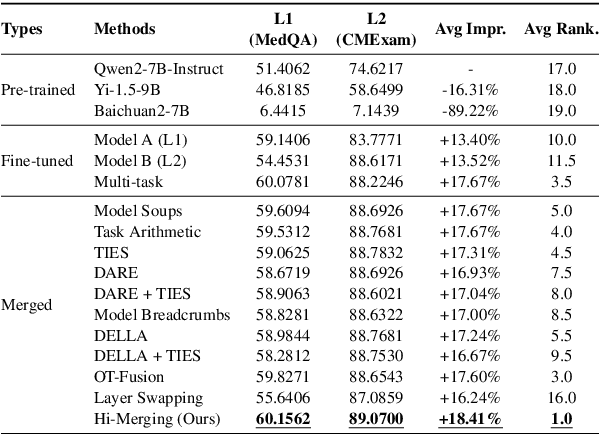
Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures
Federated Adapter on Foundation Models: An Out-Of-Distribution Approach
May 02, 2025As foundation models gain prominence, Federated Foundation Models (FedFM) have emerged as a privacy-preserving approach to collaboratively fine-tune models in federated learning (FL) frameworks using distributed datasets across clients. A key challenge for FedFM, given the versatile nature of foundation models, is addressing out-of-distribution (OOD) generalization, where unseen tasks or clients may exhibit distribution shifts leading to suboptimal performance. Although numerous studies have explored OOD generalization in conventional FL, these methods are inadequate for FedFM due to the challenges posed by large parameter scales and increased data heterogeneity. To address these, we propose FedOA, which employs adapter-based parameter-efficient fine-tuning methods for efficacy and introduces personalized adapters with feature distance-based regularization to align distributions and guarantee OOD generalization for each client. Theoretically, we demonstrate that the conventional aggregated global model in FedFM inherently retains OOD generalization capabilities, and our proposed method enhances the personalized model's OOD generalization through regularization informed by the global model, with proven convergence under general non-convex settings. Empirically, the effectiveness of the proposed method is validated on benchmark datasets across various NLP tasks.
Robust Learning under Hybrid Noise
Jul 04, 2024Feature noise and label noise are ubiquitous in practical scenarios, which pose great challenges for training a robust machine learning model. Most previous approaches usually deal with only a single problem of either feature noise or label noise. However, in real-world applications, hybrid noise, which contains both feature noise and label noise, is very common due to the unreliable data collection and annotation processes. Although some results have been achieved by a few representation learning based attempts, this issue is still far from being addressed with promising performance and guaranteed theoretical analyses. To address the challenge, we propose a novel unified learning framework called "Feature and Label Recovery" (FLR) to combat the hybrid noise from the perspective of data recovery, where we concurrently reconstruct both the feature matrix and the label matrix of input data. Specifically, the clean feature matrix is discovered by the low-rank approximation, and the ground-truth label matrix is embedded based on the recovered features with a nuclear norm regularization. Meanwhile, the feature noise and label noise are characterized by their respective adaptive matrix norms to satisfy the corresponding maximum likelihood. As this framework leads to a non-convex optimization problem, we develop the non-convex Alternating Direction Method of Multipliers (ADMM) with the convergence guarantee to solve our learning objective. We also provide the theoretical analysis to show that the generalization error of FLR can be upper-bounded in the presence of hybrid noise. Experimental results on several typical benchmark datasets clearly demonstrate the superiority of our proposed method over the state-of-the-art robust learning approaches for various noises.