 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCast: Recasting Learning Signals for Reinforcement Learning in Generative Recommendation
Apr 24, 2026Generic group-based RL assumes that sampled rollout groups are already usable learning signals. We show that this assumption breaks down in sparse-hit generative recommendation, where many sampled groups never become learnable at all. We propose ReCast, a repair-then-contrast learning-signal framework that first restores minimal learnability for all-zero groups and then replaces full-group reward normalization with a boundary-focused contrastive update on the strongest positive and the hardest negative. ReCast leaves the outer RL framework unchanged, modifies only within-group signal construction, and partially decouples rollout search width from actor-side update width. Across multiple generative recommendation tasks, ReCast consistently outperforms OpenOneRec-RL, achieving up to 36.6% relative improvement in Pass@1. Its matched-budget advantage is substantially larger: ReCast reaches the baseline's target performance with only 4.1% of the rollout budget, and this advantage widens with model scale. The same design also yields direct system-level gains, reducing actor-side update time by 16.60x, lowering peak allocated memory by 16.5%, and improving actor MFU by 14.2%. Mechanism analysis shows that ReCast mitigates the persistent all-zero / single-hit regime, restores learnability when natural positives are scarce, and converts otherwise wasted rollout budget into more stable policy updates. These results suggest that, for generative recommendation, the decisive RL problem is not only how to assign rewards, but how to construct learnable optimization events from sparse, structured supervision.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
HeTGB: A Comprehensive Benchmark for Heterophilic Text-Attributed Graphs
Mar 05, 2025Graph neural networks (GNNs) have demonstrated success in modeling relational data primarily under the assumption of homophily. However, many real-world graphs exhibit heterophily, where linked nodes belong to different categories or possess diverse attributes. Additionally, nodes in many domains are associated with textual descriptions, forming heterophilic text-attributed graphs (TAGs). Despite their significance, the study of heterophilic TAGs remains underexplored due to the lack of comprehensive benchmarks. To address this gap, we introduce the Heterophilic Text-attributed Graph Benchmark (HeTGB), a novel benchmark comprising five real-world heterophilic graph datasets from diverse domains, with nodes enriched by extensive textual descriptions. HeTGB enables systematic evaluation of GNNs, pre-trained language models (PLMs) and co-training methods on the node classification task. Through extensive benchmarking experiments, we showcase the utility of text attributes in heterophilic graphs, analyze the challenges posed by heterophilic TAGs and the limitations of existing models, and provide insights into the interplay between graph structures and textual attributes. We have publicly released HeTGB with baseline implementations to facilitate further research in this field.
Pseudo-Label Enhanced Prototypical Contrastive Learning for Uniformed Intent Discovery
Oct 26, 2024



New intent discovery is a crucial capability for task-oriented dialogue systems. Existing methods focus on transferring in-domain (IND) prior knowledge to out-of-domain (OOD) data through pre-training and clustering stages. They either handle the two processes in a pipeline manner, which exhibits a gap between intent representation and clustering process or use typical contrastive clustering that overlooks the potential supervised signals from the whole data. Besides, they often individually deal with open intent discovery or OOD settings. To this end, we propose a Pseudo-Label enhanced Prototypical Contrastive Learning (PLPCL) model for uniformed intent discovery. We iteratively utilize pseudo-labels to explore potential positive/negative samples for contrastive learning and bridge the gap between representation and clustering. To enable better knowledge transfer, we design a prototype learning method integrating the supervised and pseudo signals from IND and OOD samples. In addition, our method has been proven effective in two different settings of discovering new intents. Experiments on three benchmark datasets and two task settings demonstrate the effectiveness of our approach.
A Survey of Ontology Expansion for Conversational Understanding
Oct 19, 2024



In the rapidly evolving field of conversational AI, Ontology Expansion (OnExp) is crucial for enhancing the adaptability and robustness of conversational agents. Traditional models rely on static, predefined ontologies, limiting their ability to handle new and unforeseen user needs. This survey paper provides a comprehensive review of the state-of-the-art techniques in OnExp for conversational understanding. It categorizes the existing literature into three main areas: (1) New Intent Discovery, (2) New Slot-Value Discovery, and (3) Joint OnExp. By examining the methodologies, benchmarks, and challenges associated with these areas, we highlight several emerging frontiers in OnExp to improve agent performance in real-world scenarios and discuss their corresponding challenges. This survey aspires to be a foundational reference for researchers and practitioners, promoting further exploration and innovation in this crucial domain.
Retrieval Augmented Generation for Dynamic Graph Modeling
Aug 26, 2024



Dynamic graph modeling is crucial for analyzing evolving patterns in various applications. Existing approaches often integrate graph neural networks with temporal modules or redefine dynamic graph modeling as a generative sequence task. However, these methods typically rely on isolated historical contexts of the target nodes from a narrow perspective, neglecting occurrences of similar patterns or relevant cases associated with other nodes. In this work, we introduce the Retrieval-Augmented Generation for Dynamic Graph Modeling (RAG4DyG) framework, which leverages guidance from contextually and temporally analogous examples to broaden the perspective of each node. This approach presents two critical challenges: (1) How to identify and retrieve high-quality demonstrations that are contextually and temporally analogous to dynamic graph samples? (2) How can these demonstrations be effectively integrated to improve dynamic graph modeling? To address these challenges, we propose RAG4DyG, which enriches the understanding of historical contexts by retrieving and learning from contextually and temporally pertinent demonstrations. Specifically, we employ a time- and context-aware contrastive learning module to identify and retrieve relevant cases for each query sequence. Moreover, we design a graph fusion strategy to integrate the retrieved cases, thereby augmenting the inherent historical contexts for improved prediction. Extensive experiments on real-world datasets across different domains demonstrate the effectiveness of RAG4DyG for dynamic graph modeling.
Few-Shot Learning on Graphs: from Meta-learning to Pre-training and Prompting
Feb 02, 2024



Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, where performance heavily relies on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few task-specific labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies into three major families: meta-learning approaches, pre-training approaches, and hybrid approaches, with a finer-grained classification in each family to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective future directions for few-shot learning on graphs to catalyze continued innovation in this field.
Actively Discovering New Slots for Task-oriented Conversation
May 06, 2023



Existing task-oriented conversational search systems heavily rely on domain ontologies with pre-defined slots and candidate value sets. In practical applications, these prerequisites are hard to meet, due to the emerging new user requirements and ever-changing scenarios. To mitigate these issues for better interaction performance, there are efforts working towards detecting out-of-vocabulary values or discovering new slots under unsupervised or semi-supervised learning paradigm. However, overemphasizing on the conversation data patterns alone induces these methods to yield noisy and arbitrary slot results. To facilitate the pragmatic utility, real-world systems tend to provide a stringent amount of human labelling quota, which offers an authoritative way to obtain accurate and meaningful slot assignments. Nonetheless, it also brings forward the high requirement of utilizing such quota efficiently. Hence, we formulate a general new slot discovery task in an information extraction fashion and incorporate it into an active learning framework to realize human-in-the-loop learning. Specifically, we leverage existing language tools to extract value candidates where the corresponding labels are further leveraged as weak supervision signals. Based on these, we propose a bi-criteria selection scheme which incorporates two major strategies, namely, uncertainty-based sampling and diversity-based sampling to efficiently identify terms of interest. We conduct extensive experiments on several public datasets and compare with a bunch of competitive baselines to demonstrate the effectiveness of our method. We have made the code and data used in this paper publicly available.
Multi-Sample based Contrastive Loss for Top-k Recommendation
Sep 01, 2021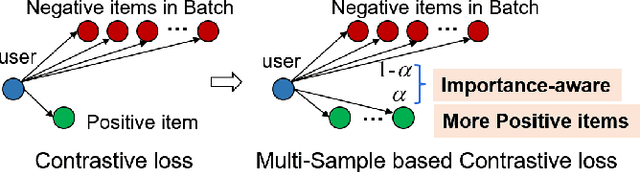
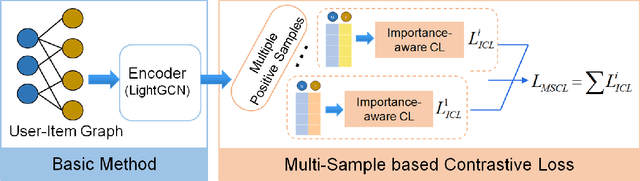
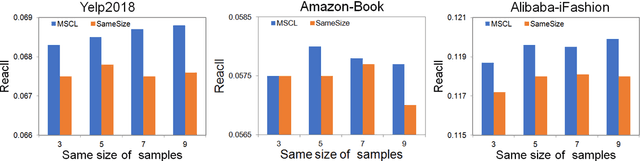
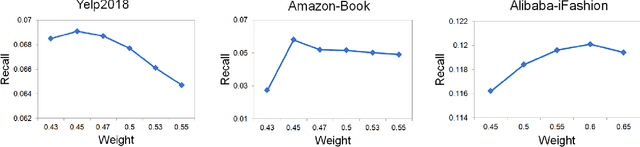
The top-k recommendation is a fundamental task in recommendation systems which is generally learned by comparing positive and negative pairs. The Contrastive Loss (CL) is the key in contrastive learning that has received more attention recently and we find it is well suited for top-k recommendations. However, it is a problem that CL treats the importance of the positive and negative samples as the same. On the one hand, CL faces the imbalance problem of one positive sample and many negative samples. On the other hand, positive items are so few in sparser datasets that their importance should be emphasized. Moreover, the other important issue is that the sparse positive items are still not sufficiently utilized in recommendations. So we propose a new data augmentation method by using multiple positive items (or samples) simultaneously with the CL loss function. Therefore, we propose a Multi-Sample based Contrastive Loss (MSCL) function which solves the two problems by balancing the importance of positive and negative samples and data augmentation. And based on the graph convolution network (GCN) method, experimental results demonstrate the state-of-the-art performance of MSCL. The proposed MSCL is simple and can be applied in many methods. We will release our code on GitHub upon the acceptance.