 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTango: Taming Visual Signals for Efficient Video Large Language Models
Apr 13, 2026Token pruning has emerged as a mainstream approach for developing efficient Video Large Language Models (Video LLMs). This work revisits and advances the two predominant token-pruning paradigms: attention-based selection and similarity-based clustering. Our study reveals two critical limitations in existing methods: (1) conventional top-k selection strategies fail to fully account for the attention distribution, which is often spatially multi-modal and long-tailed in magnitude; and (2) direct similarity-based clustering frequently generates fragmented clusters, resulting in distorted representations after pooling. To address these bottlenecks, we propose Tango, a novel framework designed to optimize the utilization of visual signals. Tango integrates a diversity-driven strategy to enhance attention-based token selection, and introduces Spatio-temporal Rotary Position Embedding (ST-RoPE) to preserve geometric structure via locality priors. Comprehensive experiments across various Video LLMs and video understanding benchmarks demonstrate the effectiveness and generalizability of our approach. Notably, when retaining only 10% of the video tokens, Tango preserves 98.9% of the original performance on LLaVA-OV while delivering a 1.88$\times$ inference speedup.
VQNet 2.0: A New Generation Machine Learning Framework that Unifies Classical and Quantum
Jan 09, 2023With the rapid development of classical and quantum machine learning, a large number of machine learning frameworks have been proposed. However, existing machine learning frameworks usually only focus on classical or quantum, rather than both. Therefore, based on VQNet 1.0, we further propose VQNet 2.0, a new generation of unified classical and quantum machine learning framework that supports hybrid optimization. The core library of the framework is implemented in C++, and the user level is implemented in Python, and it supports deployment on quantum and classical hardware. In this article, we analyze the development trend of the new generation machine learning framework and introduce the design principles of VQNet 2.0 in detail: unity, practicality, efficiency, and compatibility, as well as full particulars of implementation. We illustrate the functions of VQNet 2.0 through several basic applications, including classical convolutional neural networks, quantum autoencoders, hybrid classical-quantum networks, etc. After that, through extensive experiments, we demonstrate that the operation speed of VQNet 2.0 is higher than the comparison method. Finally, through extensive experiments, we demonstrate that VQNet 2.0 can deploy on different hardware platforms, the overall calculation speed is faster than the comparison method. It also can be mixed and optimized with quantum circuits composed of multiple quantum computing libraries.
AGAN: Towards Automated Design of Generative Adversarial Networks
Jun 25, 2019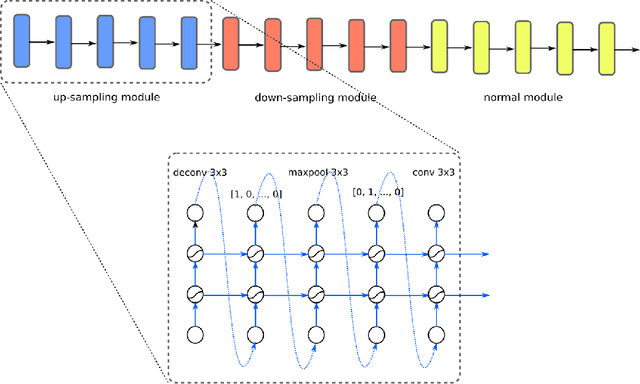
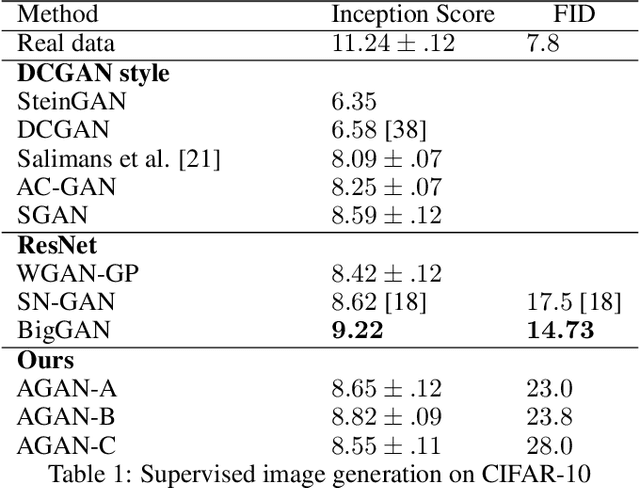
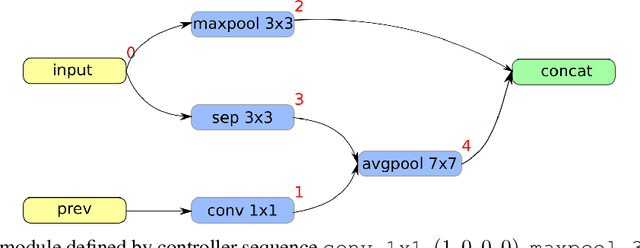
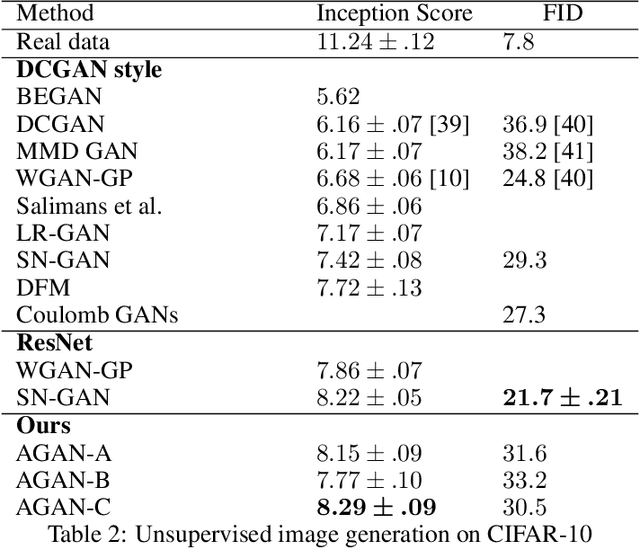
Recent progress in Generative Adversarial Networks (GANs) has shown promising signs of improving GAN training via architectural change. Despite some early success, at present the design of GAN architectures requires human expertise, laborious trial-and-error testings, and often draws inspiration from its image classification counterpart. In the current paper, we present the first neural architecture search algorithm, automated neural architecture search for deep generative models, or AGAN for abbreviation, that is specifically suited for GAN training. For unsupervised image generation tasks on CIFAR-10, our algorithm finds architecture that outperforms state-of-the-art models under same regularization techniques. For supervised tasks, the automatically searched architectures also achieve highly competitive performance, outperforming best human-invented architectures at resolution $32\times32$. Moreover, we empirically demonstrate that the modules learned by AGAN are transferable to other image generation tasks such as STL-10.
DELTA: DEep Learning Transfer using Feature Map with Attention for Convolutional Networks
Jan 26, 2019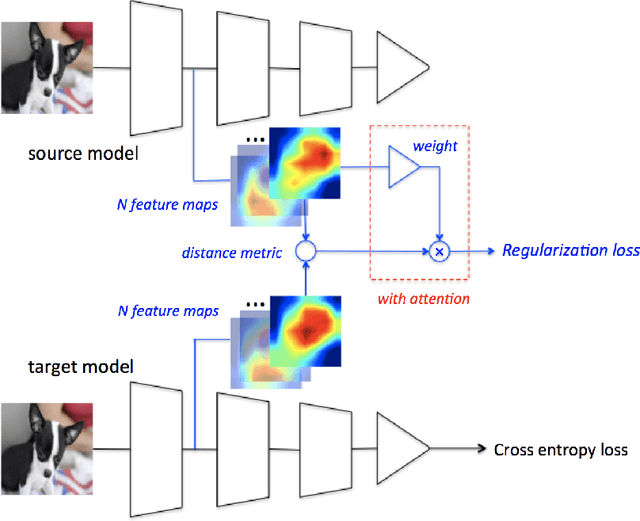
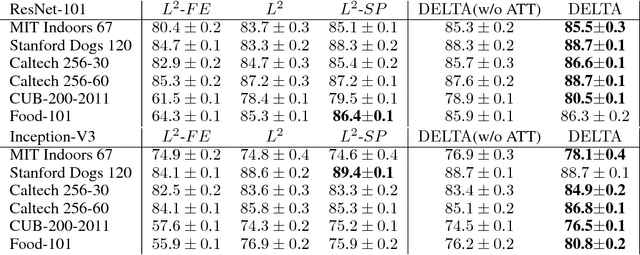
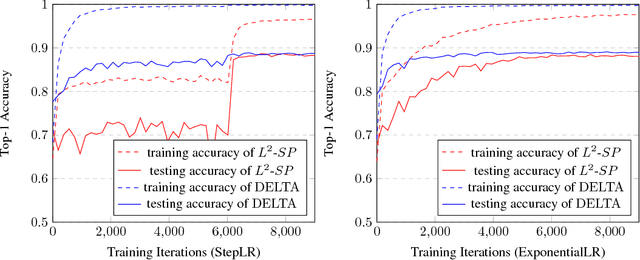
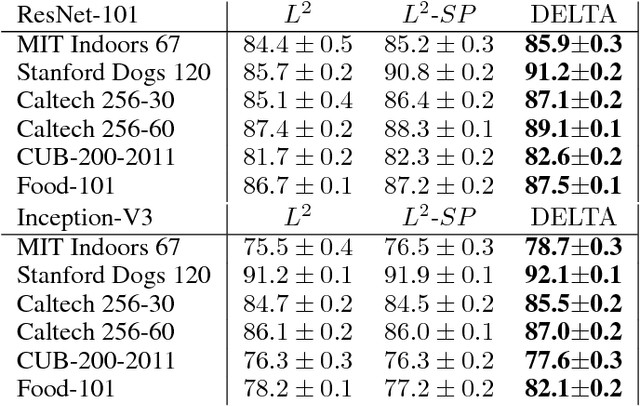
Transfer learning through fine-tuning a pre-trained neural network with an extremely large dataset, such as ImageNet, can significantly accelerate training while the accuracy is frequently bottlenecked by the limited dataset size of the new target task. To solve the problem, some regularization methods, constraining the outer layer weights of the target network using the starting point as references (SPAR), have been studied. In this paper, we propose a novel regularized transfer learning framework DELTA, namely DEep Learning Transfer using Feature Map with Attention. Instead of constraining the weights of neural network, DELTA aims to preserve the outer layer outputs of the target network. Specifically, in addition to minimizing the empirical loss, DELTA intends to align the outer layer outputs of two networks, through constraining a subset of feature maps that are precisely selected by attention that has been learned in an supervised learning manner. We evaluate DELTA with the state-of-the-art algorithms, including L2 and L2-SP. The experiment results show that our proposed method outperforms these baselines with higher accuracy for new tasks.