 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Generalization Gap of Cross-silo Federated Medical Image Segmentation
Mar 18, 2022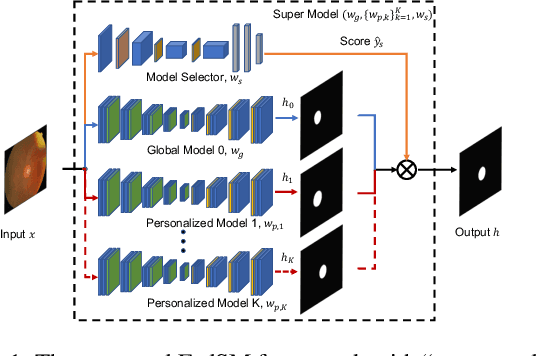
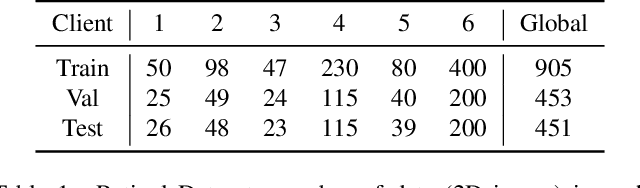
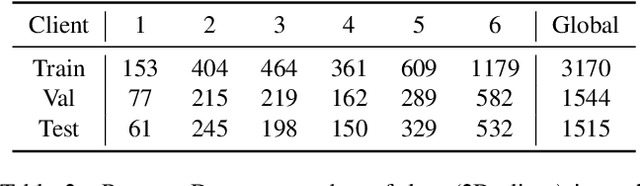
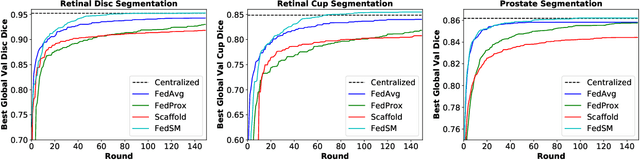
Cross-silo federated learning (FL) has attracted much attention in medical imaging analysis with deep learning in recent years as it can resolve the critical issues of insufficient data, data privacy, and training efficiency. However, there can be a generalization gap between the model trained from FL and the one from centralized training. This important issue comes from the non-iid data distribution of the local data in the participating clients and is well-known as client drift. In this work, we propose a novel training framework FedSM to avoid the client drift issue and successfully close the generalization gap compared with the centralized training for medical image segmentation tasks for the first time. We also propose a novel personalized FL objective formulation and a new method SoftPull to solve it in our proposed framework FedSM. We conduct rigorous theoretical analysis to guarantee its convergence for optimizing the non-convex smooth objective function. Real-world medical image segmentation experiments using deep FL validate the motivations and effectiveness of our proposed method.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022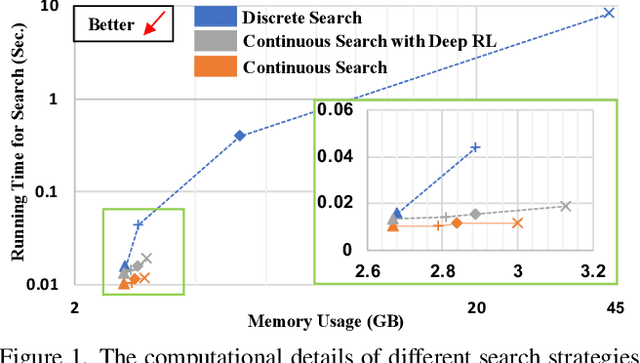

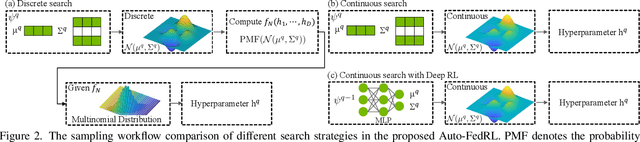

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Do Gradient Inversion Attacks Make Federated Learning Unsafe?
Feb 14, 2022Federated learning (FL) allows the collaborative training of AI models without needing to share raw data. This capability makes it especially interesting for healthcare applications where patient and data privacy is of utmost concern. However, recent works on the inversion of deep neural networks from model gradients raised concerns about the security of FL in preventing the leakage of training data. In this work, we show that these attacks presented in the literature are impractical in real FL use-cases and provide a new baseline attack that works for more realistic scenarios where the clients' training involves updating the Batch Normalization (BN) statistics. Furthermore, we present new ways to measure and visualize potential data leakage in FL. Our work is a step towards establishing reproducible methods of measuring data leakage in FL and could help determine the optimal tradeoffs between privacy-preserving techniques, such as differential privacy, and model accuracy based on quantifiable metrics.
Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis
Nov 29, 2021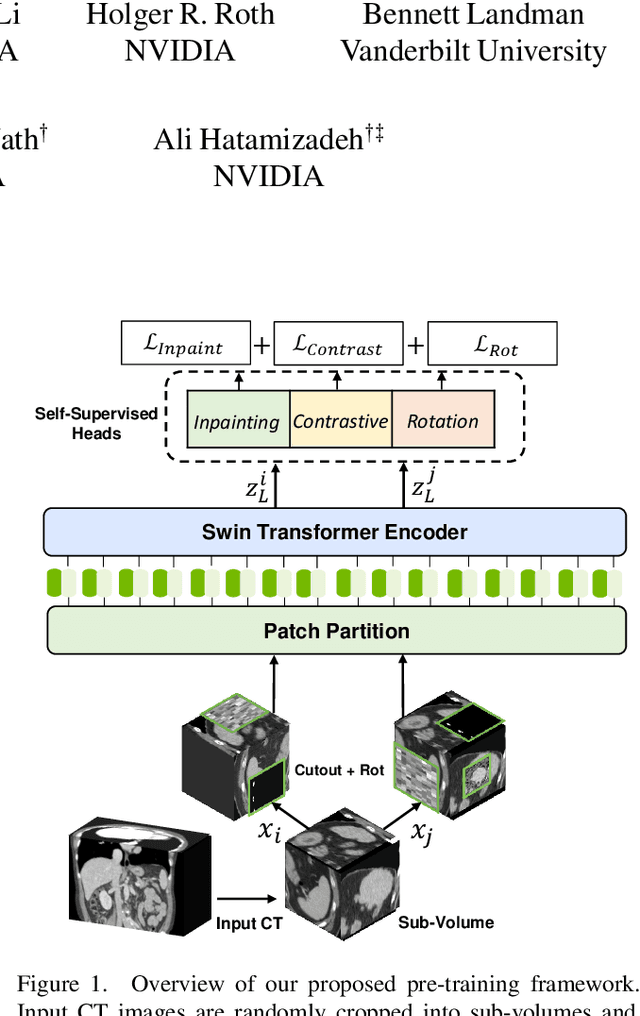
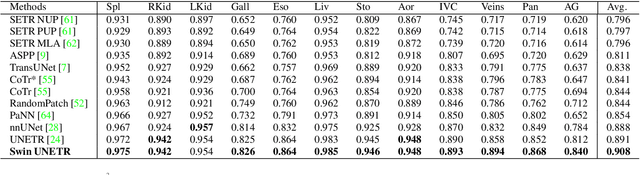
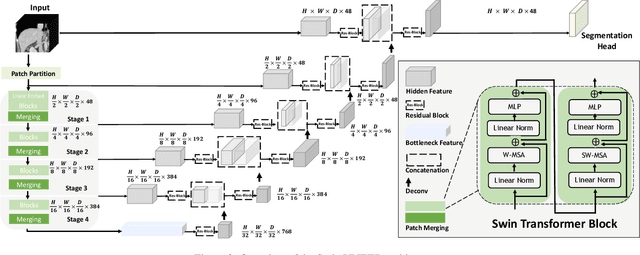
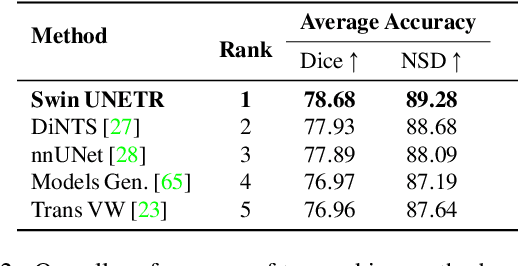
Vision Transformers (ViT)s have shown great performance in self-supervised learning of global and local representations that can be transferred to downstream applications. Inspired by these results, we introduce a novel self-supervised learning framework with tailored proxy tasks for medical image analysis. Specifically, we propose: (i) a new 3D transformer-based model, dubbed Swin UNEt TRansformers (Swin UNETR), with a hierarchical encoder for self-supervised pre-training; (ii) tailored proxy tasks for learning the underlying pattern of human anatomy. We demonstrate successful pre-training of the proposed model on 5,050 publicly available computed tomography (CT) images from various body organs. The effectiveness of our approach is validated by fine-tuning the pre-trained models on the Beyond the Cranial Vault (BTCV) Segmentation Challenge with 13 abdominal organs and segmentation tasks from the Medical Segmentation Decathlon (MSD) dataset. Our model is currently the state-of-the-art (i.e. ranked 1st) on the public test leaderboards of both MSD and BTCV datasets. Code: https://monai.io/research/swin-unetr
Federated Whole Prostate Segmentation in MRI with Personalized Neural Architectures
Jul 16, 2021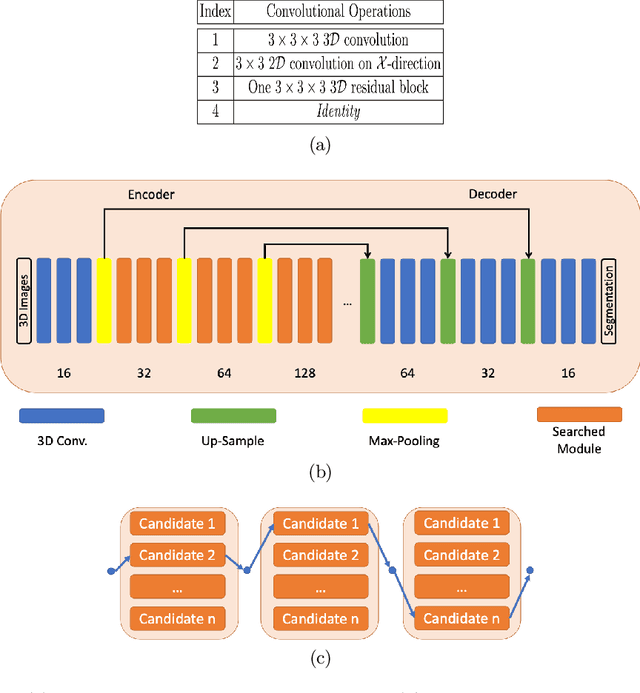
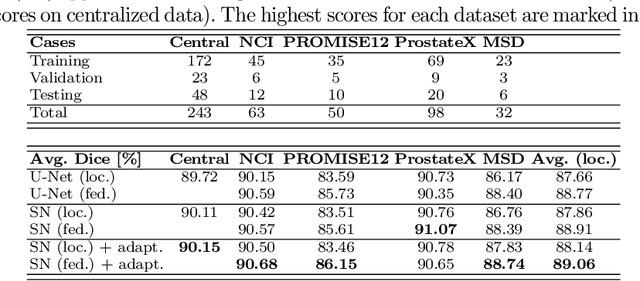
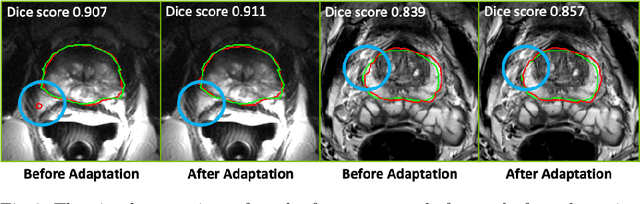
Building robust deep learning-based models requires diverse training data, ideally from several sources. However, these datasets cannot be combined easily because of patient privacy concerns or regulatory hurdles, especially if medical data is involved. Federated learning (FL) is a way to train machine learning models without the need for centralized datasets. Each FL client trains on their local data while only sharing model parameters with a global server that aggregates the parameters from all clients. At the same time, each client's data can exhibit differences and inconsistencies due to the local variation in the patient population, imaging equipment, and acquisition protocols. Hence, the federated learned models should be able to adapt to the local particularities of a client's data. In this work, we combine FL with an AutoML technique based on local neural architecture search by training a "supernet". Furthermore, we propose an adaptation scheme to allow for personalized model architectures at each FL client's site. The proposed method is evaluated on four different datasets from 3D prostate MRI and shown to improve the local models' performance after adaptation through selecting an optimal path through the AutoML supernet.
Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021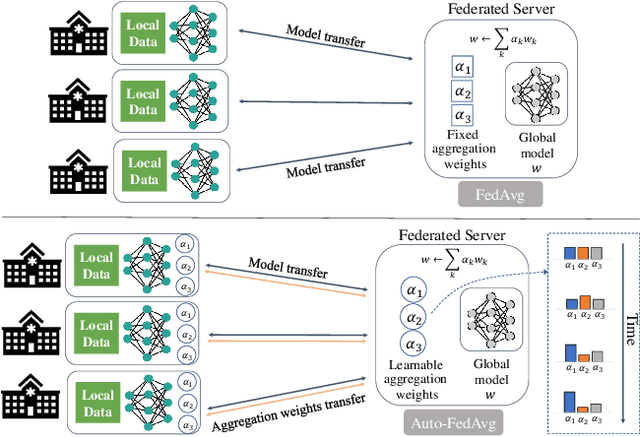
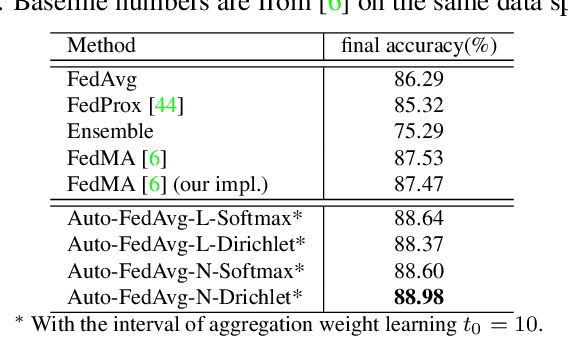
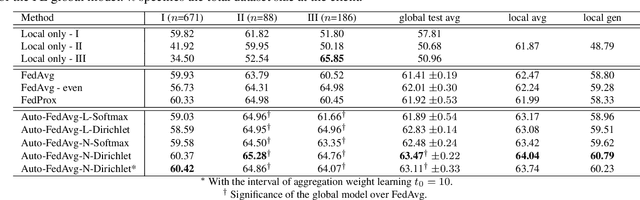
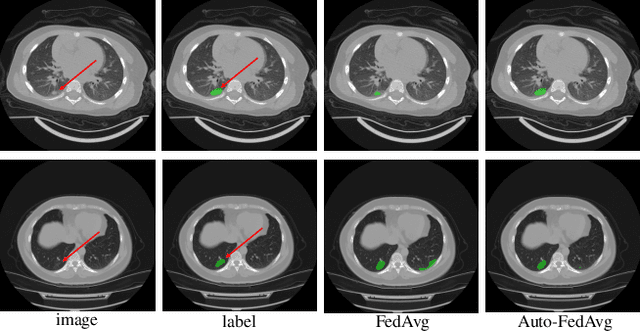
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Deep Class-Specific Affinity-Guided Convolutional Network for Multimodal Unpaired Image Segmentation
Jan 05, 2021
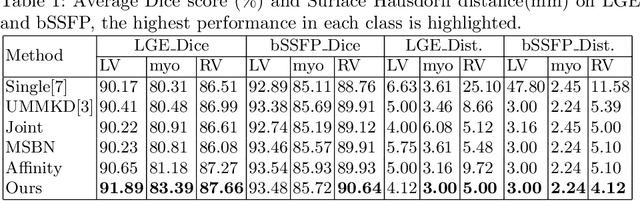
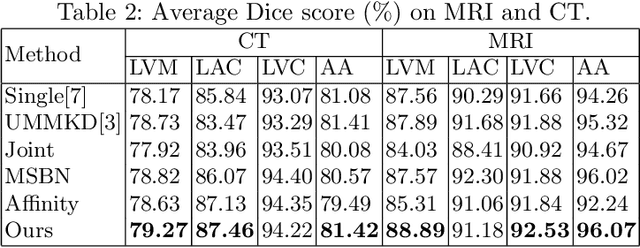
Multi-modal medical image segmentation plays an essential role in clinical diagnosis. It remains challenging as the input modalities are often not well-aligned spatially. Existing learning-based methods mainly consider sharing trainable layers across modalities and minimizing visual feature discrepancies. While the problem is often formulated as joint supervised feature learning, multiple-scale features and class-specific representation have not yet been explored. In this paper, we propose an affinity-guided fully convolutional network for multimodal image segmentation. To learn effective representations, we design class-specific affinity matrices to encode the knowledge of hierarchical feature reasoning, together with the shared convolutional layers to ensure the cross-modality generalization. Our affinity matrix does not depend on spatial alignments of the visual features and thus allows us to train with unpaired, multimodal inputs. We extensively evaluated our method on two public multimodal benchmark datasets and outperform state-of-the-art methods.
Federated Semi-Supervised Learning for COVID Region Segmentation in Chest CT using Multi-National Data from China, Italy, Japan
Nov 23, 2020
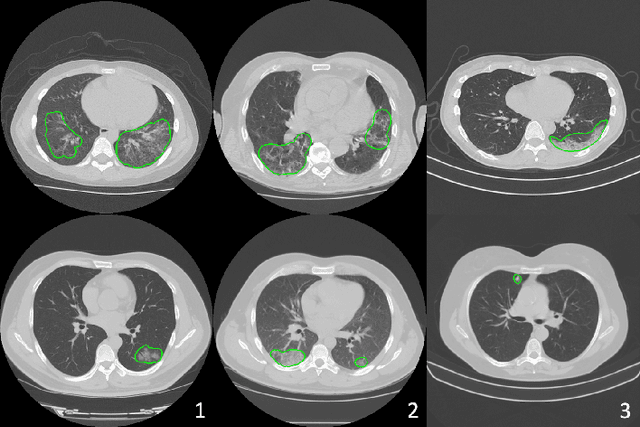
The recent outbreak of COVID-19 has led to urgent needs for reliable diagnosis and management of SARS-CoV-2 infection. As a complimentary tool, chest CT has been shown to be able to reveal visual patterns characteristic for COVID-19, which has definite value at several stages during the disease course. To facilitate CT analysis, recent efforts have focused on computer-aided characterization and diagnosis, which has shown promising results. However, domain shift of data across clinical data centers poses a serious challenge when deploying learning-based models. In this work, we attempt to find a solution for this challenge via federated and semi-supervised learning. A multi-national database consisting of 1704 scans from three countries is adopted to study the performance gap, when training a model with one dataset and applying it to another. Expert radiologists manually delineated 945 scans for COVID-19 findings. In handling the variability in both the data and annotations, a novel federated semi-supervised learning technique is proposed to fully utilize all available data (with or without annotations). Federated learning avoids the need for sensitive data-sharing, which makes it favorable for institutions and nations with strict regulatory policy on data privacy. Moreover, semi-supervision potentially reduces the annotation burden under a distributed setting. The proposed framework is shown to be effective compared to fully supervised scenarios with conventional data sharing instead of model weight sharing.
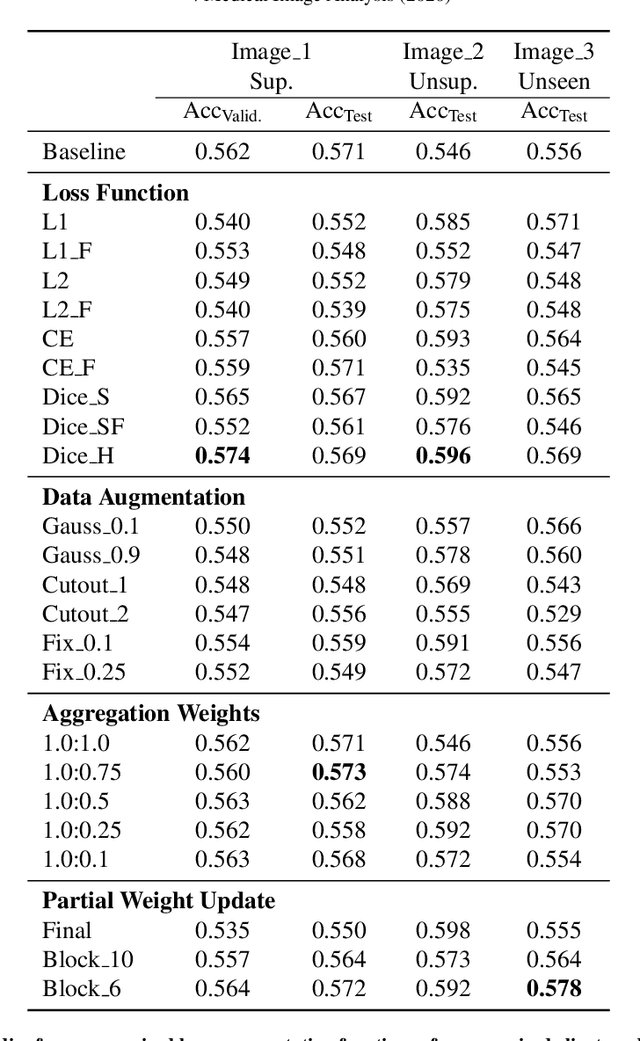
Federated Learning for Breast Density Classification: A Real-World Implementation
Sep 17, 2020

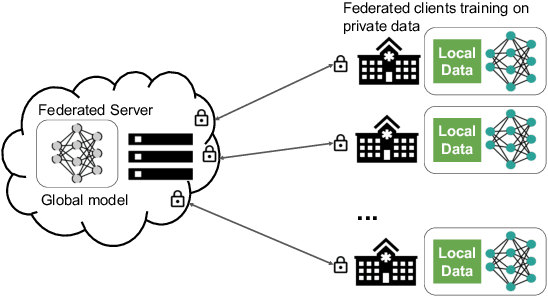
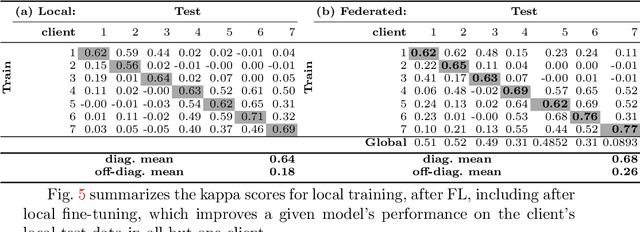
Building robust deep learning-based models requires large quantities of diverse training data. In this study, we investigate the use of federated learning (FL) to build medical imaging classification models in a real-world collaborative setting. Seven clinical institutions from across the world joined this FL effort to train a model for breast density classification based on Breast Imaging, Reporting & Data System (BI-RADS). We show that despite substantial differences among the datasets from all sites (mammography system, class distribution, and data set size) and without centralizing data, we can successfully train AI models in federation. The results show that models trained using FL perform 6.3% on average better than their counterparts trained on an institute's local data alone. Furthermore, we show a 45.8% relative improvement in the models' generalizability when evaluated on the other participating sites' testing data.
Learning joint segmentation of tissues and brain lesions from task-specific hetero-modal domain-shifted datasets
Sep 08, 2020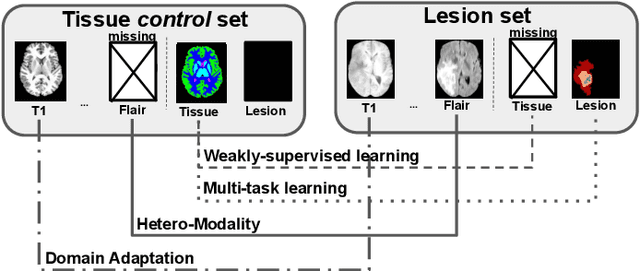

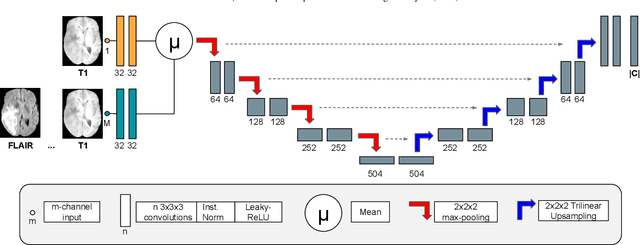
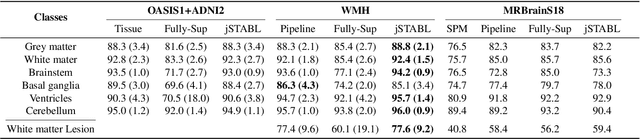
Brain tissue segmentation from multimodal MRI is a key building block of many neuroimaging analysis pipelines. Established tissue segmentation approaches have, however, not been developed to cope with large anatomical changes resulting from pathology, such as white matter lesions or tumours, and often fail in these cases. In the meantime, with the advent of deep neural networks (DNNs), segmentation of brain lesions has matured significantly. However, few existing approaches allow for the joint segmentation of normal tissue and brain lesions. Developing a DNN for such a joint task is currently hampered by the fact that annotated datasets typically address only one specific task and rely on task-specific imaging protocols including a task-specific set of imaging modalities. In this work, we propose a novel approach to build a joint tissue and lesion segmentation model from aggregated task-specific hetero-modal domain-shifted and partially-annotated datasets. Starting from a variational formulation of the joint problem, we show how the expected risk can be decomposed and optimised empirically. We exploit an upper bound of the risk to deal with heterogeneous imaging modalities across datasets. To deal with potential domain shift, we integrated and tested three conventional techniques based on data augmentation, adversarial learning and pseudo-healthy generation. For each individual task, our joint approach reaches comparable performance to task-specific and fully-supervised models. The proposed framework is assessed on two different types of brain lesions: White matter lesions and gliomas. In the latter case, lacking a joint ground-truth for quantitative assessment purposes, we propose and use a novel clinically-relevant qualitative assessment methodology.