 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Sources of Demographic Predictability in Brain MRI via Disentangling Anatomy and Contrast
Mar 04, 2026Demographic attributes such as age, sex, and race can be predicted from medical images, raising concerns about bias in clinical AI systems. In brain MRI, this signal may arise from anatomical variation, acquisition-dependent contrast differences, or both, yet these sources remain entangled in conventional analyses. Without disentangling them, mitigation strategies risk failing to address the underlying causes. We propose a controlled framework based on disentangled representation learning, decomposing brain MRI into anatomy-focused representations that suppress acquisition influence and contrast embeddings that capture acquisition-dependent characteristics. Training predictive models for age, sex, and race on full images, anatomical representations, and contrast-only embeddings allows us to quantify the relative contributions of structure and acquisition to the demographic signal. Across three datasets and multiple MRI sequences, we find that demographic predictability is primarily rooted in anatomical variation: anatomy-focused representations largely preserve the performance of models trained on raw images. Contrast-only embeddings retain a weaker but systematic signal that is dataset-specific and does not generalise across sites. These findings suggest that effective mitigation must explicitly account for the distinct anatomical and acquisition-dependent origins of the demographic signal, ensuring that any bias reduction generalizes robustly across domains.
DIST-CLIP: Arbitrary Metadata and Image Guided MRI Harmonization via Disentangled Anatomy-Contrast Representations
Dec 08, 2025Deep learning holds immense promise for transforming medical image analysis, yet its clinical generalization remains profoundly limited. A major barrier is data heterogeneity. This is particularly true in Magnetic Resonance Imaging, where scanner hardware differences, diverse acquisition protocols, and varying sequence parameters introduce substantial domain shifts that obscure underlying biological signals. Data harmonization methods aim to reduce these instrumental and acquisition variability, but existing approaches remain insufficient. When applied to imaging data, image-based harmonization approaches are often restricted by the need for target images, while existing text-guided methods rely on simplistic labels that fail to capture complex acquisition details or are typically restricted to datasets with limited variability, failing to capture the heterogeneity of real-world clinical environments. To address these limitations, we propose DIST-CLIP (Disentangled Style Transfer with CLIP Guidance), a unified framework for MRI harmonization that flexibly uses either target images or DICOM metadata for guidance. Our framework explicitly disentangles anatomical content from image contrast, with the contrast representations being extracted using pre-trained CLIP encoders. These contrast embeddings are then integrated into the anatomical content via a novel Adaptive Style Transfer module. We trained and evaluated DIST-CLIP on diverse real-world clinical datasets, and showed significant improvements in performance when compared against state-of-the-art methods in both style translation fidelity and anatomical preservation, offering a flexible solution for style transfer and standardizing MRI data. Our code and weights will be made publicly available upon publication.
Generalizable automated ischaemic stroke lesion segmentation with vision transformers
Feb 10, 2025



Ischaemic stroke, a leading cause of death and disability, critically relies on neuroimaging for characterising the anatomical pattern of injury. Diffusion-weighted imaging (DWI) provides the highest expressivity in ischemic stroke but poses substantial challenges for automated lesion segmentation: susceptibility artefacts, morphological heterogeneity, age-related comorbidities, time-dependent signal dynamics, instrumental variability, and limited labelled data. Current U-Net-based models therefore underperform, a problem accentuated by inadequate evaluation metrics that focus on mean performance, neglecting anatomical, subpopulation, and acquisition-dependent variability. Here, we present a high-performance DWI lesion segmentation tool addressing these challenges through optimized vision transformer-based architectures, integration of 3563 annotated lesions from multi-site data, and algorithmic enhancements, achieving state-of-the-art results. We further propose a novel evaluative framework assessing model fidelity, equity (across demographics and lesion subtypes), anatomical precision, and robustness to instrumental variability, promoting clinical and research utility. This work advances stroke imaging by reconciling model expressivity with domain-specific challenges and redefining performance benchmarks to prioritize equity and generalizability, critical for personalized medicine and mechanistic research.
Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
Dec 13, 2024



Previous studies have demonstrated that not each sample in a dataset is of equal importance during training. Data pruning aims to remove less important or informative samples while still achieving comparable results as training on the original (untruncated) dataset, thereby reducing storage and training costs. However, the majority of data pruning methods are applied to image classification tasks. To our knowledge, this work is the first to explore the feasibility of these pruning methods applied to object re-identification (ReID) tasks, while also presenting a more comprehensive data pruning approach. By fully leveraging the logit history during training, our approach offers a more accurate and comprehensive metric for quantifying sample importance, as well as correcting mislabeled samples and recognizing outliers. Furthermore, our approach is highly efficient, reducing the cost of importance score estimation by 10 times compared to existing methods. Our approach is a plug-and-play, architecture-agnostic framework that can eliminate/reduce 35%, 30%, and 5% of samples/training time on the VeRi, MSMT17 and Market1501 datasets, respectively, with negligible loss in accuracy (< 0.1%). The lists of important, mislabeled, and outlier samples from these ReID datasets are available at https://github.com/Zi-Y/data-pruning-reid.
Command-line Risk Classification using Transformer-based Neural Architectures
Dec 02, 2024



To protect large-scale computing environments necessary to meet increasing computing demand, cloud providers have implemented security measures to monitor Operations and Maintenance (O&M) activities and therefore prevent data loss and service interruption. Command interception systems are used to intercept, assess, and block dangerous Command-line Interface (CLI) commands before they can cause damage. Traditional solutions for command risk assessment include rule-based systems, which require expert knowledge and constant human revision to account for unseen commands. To overcome these limitations, several end-to-end learning systems have been proposed to classify CLI commands. These systems, however, have several other limitations, including the adoption of general-purpose text classifiers, which may not adapt to the language characteristics of scripting languages such as Bash or PowerShell, and may not recognize dangerous commands in the presence of an unbalanced class distribution. In this paper, we propose a transformer-based command risk classification system, which leverages the generalization power of Large Language Models (LLM) to provide accurate classification and the ability to identify rare dangerous commands effectively, by exploiting the power of transfer learning. We verify the effectiveness of our approach on a realistic dataset of production commands and show how to apply our model for other security-related tasks, such as dangerous command interception and auditing of existing rule-based systems.
Investigating Memory Failure Prediction Across CPU Architectures
Jun 08, 2024



Large-scale datacenters often experience memory failures, where Uncorrectable Errors (UEs) highlight critical malfunction in Dual Inline Memory Modules (DIMMs). Existing approaches primarily utilize Correctable Errors (CEs) to predict UEs, yet they typically neglect how these errors vary between different CPU architectures, especially in terms of Error Correction Code (ECC) applicability. In this paper, we investigate the correlation between CEs and UEs across different CPU architectures, including X86 and ARM. Our analysis identifies unique patterns of memory failure associated with each processor platform. Leveraging Machine Learning (ML) techniques on production datasets, we conduct the memory failure prediction in different processors' platforms, achieving up to 15% improvements in F1-score compared to the existing algorithm. Finally, an MLOps (Machine Learning Operations) framework is provided to consistently improve the failure prediction in the production environment.
Exploring Error Bits for Memory Failure Prediction: An In-Depth Correlative Study
Dec 18, 2023



In large-scale datacenters, memory failure is a common cause of server crashes, with Uncorrectable Errors (UEs) being a major indicator of Dual Inline Memory Module (DIMM) defects. Existing approaches primarily focus on predicting UEs using Correctable Errors (CEs), without fully considering the information provided by error bits. However, error bit patterns have a strong correlation with the occurrence of UEs. In this paper, we present a comprehensive study on the correlation between CEs and UEs, specifically emphasizing the importance of spatio-temporal error bit information. Our analysis reveals a strong correlation between spatio-temporal error bits and UE occurrence. Through evaluations using real-world datasets, we demonstrate that our approach significantly improves prediction performance by 15% in F1-score compared to the state-of-the-art algorithms. Overall, our approach effectively reduces the number of virtual machine interruptions caused by UEs by approximately 59%.
* Published at ICCAD 2023
Privacy Distillation: Reducing Re-identification Risk of Multimodal Diffusion Models
Jun 02, 2023



Knowledge distillation in neural networks refers to compressing a large model or dataset into a smaller version of itself. We introduce Privacy Distillation, a framework that allows a text-to-image generative model to teach another model without exposing it to identifiable data. Here, we are interested in the privacy issue faced by a data provider who wishes to share their data via a multimodal generative model. A question that immediately arises is ``How can a data provider ensure that the generative model is not leaking identifiable information about a patient?''. Our solution consists of (1) training a first diffusion model on real data (2) generating a synthetic dataset using this model and filtering it to exclude images with a re-identifiability risk (3) training a second diffusion model on the filtered synthetic data only. We showcase that datasets sampled from models trained with privacy distillation can effectively reduce re-identification risk whilst maintaining downstream performance.
Morphology-preserving Autoregressive 3D Generative Modelling of the Brain
Sep 07, 2022
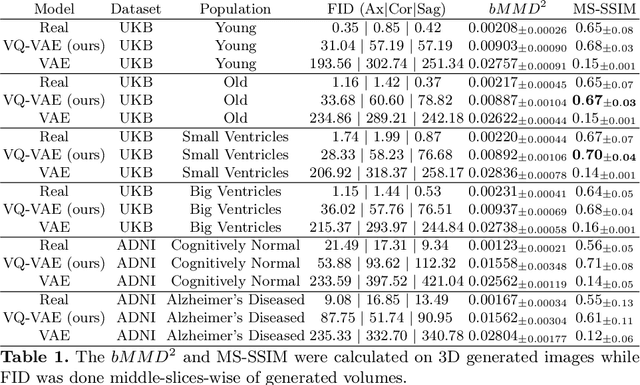
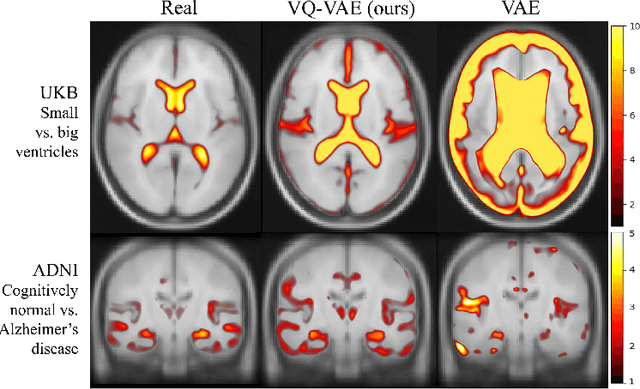
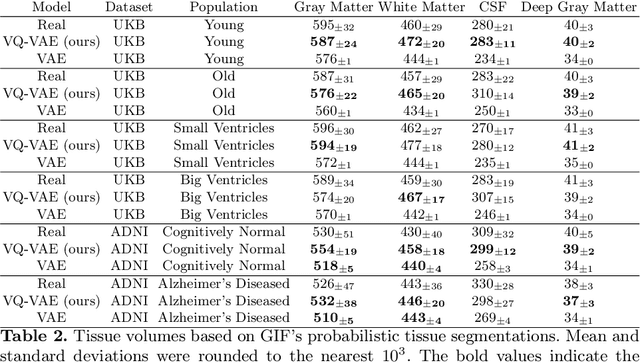
Human anatomy, morphology, and associated diseases can be studied using medical imaging data. However, access to medical imaging data is restricted by governance and privacy concerns, data ownership, and the cost of acquisition, thus limiting our ability to understand the human body. A possible solution to this issue is the creation of a model able to learn and then generate synthetic images of the human body conditioned on specific characteristics of relevance (e.g., age, sex, and disease status). Deep generative models, in the form of neural networks, have been recently used to create synthetic 2D images of natural scenes. Still, the ability to produce high-resolution 3D volumetric imaging data with correct anatomical morphology has been hampered by data scarcity and algorithmic and computational limitations. This work proposes a generative model that can be scaled to produce anatomically correct, high-resolution, and realistic images of the human brain, with the necessary quality to allow further downstream analyses. The ability to generate a potentially unlimited amount of data not only enables large-scale studies of human anatomy and pathology without jeopardizing patient privacy, but also significantly advances research in the field of anomaly detection, modality synthesis, learning under limited data, and fair and ethical AI. Code and trained models are available at: https://github.com/AmigoLab/SynthAnatomy.
Leveraging Log Instructions in Log-based Anomaly Detection
Jul 07, 2022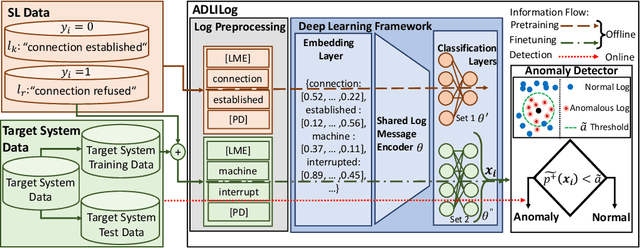
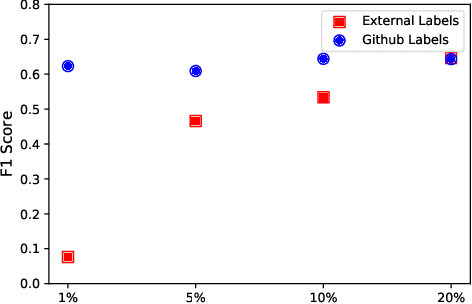
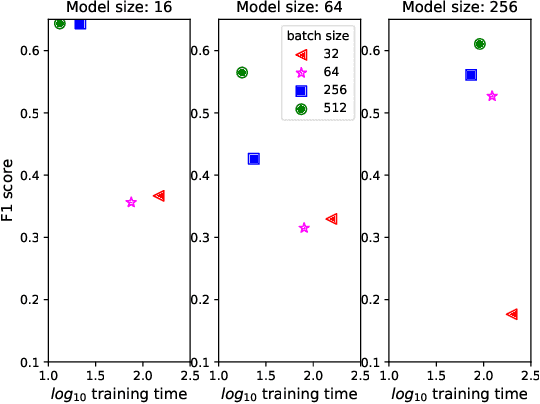

Artificial Intelligence for IT Operations (AIOps) describes the process of maintaining and operating large IT systems using diverse AI-enabled methods and tools for, e.g., anomaly detection and root cause analysis, to support the remediation, optimization, and automatic initiation of self-stabilizing IT activities. The core step of any AIOps workflow is anomaly detection, typically performed on high-volume heterogeneous data such as log messages (logs), metrics (e.g., CPU utilization), and distributed traces. In this paper, we propose a method for reliable and practical anomaly detection from system logs. It overcomes the common disadvantage of related works, i.e., the need for a large amount of manually labeled training data, by building an anomaly detection model with log instructions from the source code of 1000+ GitHub projects. The instructions from diverse systems contain rich and heterogenous information about many different normal and abnormal IT events and serve as a foundation for anomaly detection. The proposed method, named ADLILog, combines the log instructions and the data from the system of interest (target system) to learn a deep neural network model through a two-phase learning procedure. The experimental results show that ADLILog outperforms the related approaches by up to 60% on the F1 score while satisfying core non-functional requirements for industrial deployments such as unsupervised design, efficient model updates, and small model sizes.