 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Critics Help Catch Bugs in Mathematics: Towards a Better Mathematical Verifier with Natural Language Feedback
Jun 30, 2024



Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose \textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6\% (86.6\% $\rightarrow$ 88.2\%) on GSM8K and 0.8\% (37.8\% $\rightarrow$ 38.6\%) on MATH. We have released our code and data for further exploration.
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Jun 04, 2024



In this study, we investigate whether attention-based information flow inside large language models (LLMs) is aggregated through noticeable patterns for long context processing. Our observations reveal that LLMs aggregate information through Pyramidal Information Funneling where attention is scattering widely in lower layers, progressively consolidating within specific contexts, and ultimately focusin on critical tokens (a.k.a massive activation or attention sink) in higher layers. Motivated by these insights, we developed PyramidKV, a novel and effective KV cache compression method. This approach dynamically adjusts the KV cache size across different layers, allocating more cache in lower layers and less in higher ones, diverging from traditional methods that maintain a uniform KV cache size. Our experimental evaluations, utilizing the LongBench benchmark, show that PyramidKV matches the performance of models with a full KV cache while retaining only 12% of the KV cache, thus significantly reducing memory usage. In scenarios emphasizing memory efficiency, where only 0.7% of the KV cache is maintained, PyramidKV surpasses other KV cache compression techniques achieving up to a 20.5 absolute accuracy improvement on TREC.
Cross-Task Defense: Instruction-Tuning LLMs for Content Safety
May 24, 2024



Recent studies reveal that Large Language Models (LLMs) face challenges in balancing safety with utility, particularly when processing long texts for NLP tasks like summarization and translation. Despite defenses against malicious short questions, the ability of LLMs to safely handle dangerous long content, such as manuals teaching illicit activities, remains unclear. Our work aims to develop robust defenses for LLMs in processing malicious documents alongside benign NLP task queries. We introduce a defense dataset comprised of safety-related examples and propose single-task and mixed-task losses for instruction tuning. Our empirical results demonstrate that LLMs can significantly enhance their capacity to safely manage dangerous content with appropriate instruction tuning. Additionally, strengthening the defenses of tasks most susceptible to misuse is effective in protecting LLMs against processing harmful information. We also observe that trade-offs between utility and safety exist in defense strategies, where Llama2, utilizing our proposed approach, displays a significantly better balance compared to Llama1.
Safety Alignment in NLP Tasks: Weakly Aligned Summarization as an In-Context Attack
Dec 12, 2023



Recent developments in balancing the usefulness and safety of Large Language Models (LLMs) have raised a critical question: Are mainstream NLP tasks adequately aligned with safety consideration? Our study, focusing on safety-sensitive documents obtained through adversarial attacks, reveals significant disparities in the safety alignment of various NLP tasks. For instance, LLMs can effectively summarize malicious long documents but often refuse to translate them. This discrepancy highlights a previously unidentified vulnerability: attacks exploiting tasks with weaker safety alignment, like summarization, can potentially compromise the integraty of tasks traditionally deemed more robust, such as translation and question-answering (QA). Moreover, the concurrent use of multiple NLP tasks with lesser safety alignment increases the risk of LLMs inadvertently processing harmful content. We demonstrate these vulnerabilities in various safety-aligned LLMs, particularly Llama2 models and GPT-4, indicating an urgent need for strengthening safety alignments across a broad spectrum of NLP tasks.
Visual Analytics for Generative Transformer Models
Nov 21, 2023



While transformer-based models have achieved state-of-the-art results in a variety of classification and generation tasks, their black-box nature makes them challenging for interpretability. In this work, we present a novel visual analytical framework to support the analysis of transformer-based generative networks. In contrast to previous work, which has mainly focused on encoder-based models, our framework is one of the first dedicated to supporting the analysis of transformer-based encoder-decoder models and decoder-only models for generative and classification tasks. Hence, we offer an intuitive overview that allows the user to explore different facets of the model through interactive visualization. To demonstrate the feasibility and usefulness of our framework, we present three detailed case studies based on real-world NLP research problems.
ChatGPT-steered Editing Instructor for Customization of Abstractive Summarization
May 04, 2023Tailoring outputs of large language models, such as ChatGPT, to specific user needs remains a challenge despite their impressive generation quality. In this paper, we propose a tri-agent generation pipeline consisting of a generator, an instructor, and an editor to enhance the customization of generated outputs. The generator produces an initial output, the user-specific instructor generates editing instructions, and the editor generates a revised output aligned with user preferences. The inference-only large language model (ChatGPT) serves as both the generator and the editor, while a smaller model acts as the user-specific instructor to guide the generation process toward user needs. The instructor is trained using editor-steered reinforcement learning, leveraging feedback from the large-scale editor model to optimize instruction generation. Experimental results on two abstractive summarization datasets demonstrate the effectiveness of our approach in generating outputs that better fulfill user expectations.
Discourse Structure Extraction from Pre-Trained and Fine-Tuned Language Models in Dialogues
Feb 12, 2023



Discourse processing suffers from data sparsity, especially for dialogues. As a result, we explore approaches to build discourse structures for dialogues, based on attention matrices from Pre-trained Language Models (PLMs). We investigate multiple tasks for fine-tuning and show that the dialogue-tailored Sentence Ordering task performs best. To locate and exploit discourse information in PLMs, we propose an unsupervised and a semi-supervised method. Our proposals achieve encouraging results on the STAC corpus, with F1 scores of 57.2 and 59.3 for unsupervised and semi-supervised methods, respectively. When restricted to projective trees, our scores improved to 63.3 and 68.1.
Attend to the Right Context: A Plug-and-Play Module for Content-Controllable Summarization
Dec 21, 2022



Content-Controllable Summarization generates summaries focused on the given controlling signals. Due to the lack of large-scale training corpora for the task, we propose a plug-and-play module RelAttn to adapt any general summarizers to the content-controllable summarization task. RelAttn first identifies the relevant content in the source documents, and then makes the model attend to the right context by directly steering the attention weight. We further apply an unsupervised online adaptive parameter searching algorithm to determine the degree of control in the zero-shot setting, while such parameters are learned in the few-shot setting. By applying the module to three backbone summarization models, experiments show that our method effectively improves all the summarizers, and outperforms the prefix-based method and a widely used plug-and-play model in both zero- and few-shot settings. Tellingly, more benefit is observed in the scenarios when more control is needed.
Entity-based SpanCopy for Abstractive Summarization to Improve the Factual Consistency
Sep 07, 2022
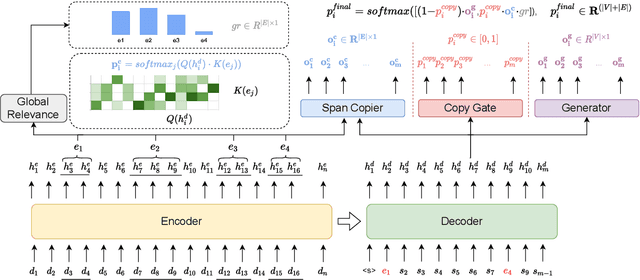
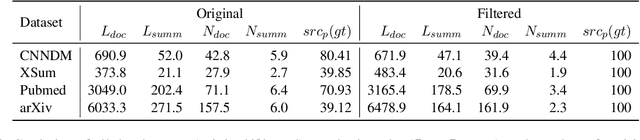
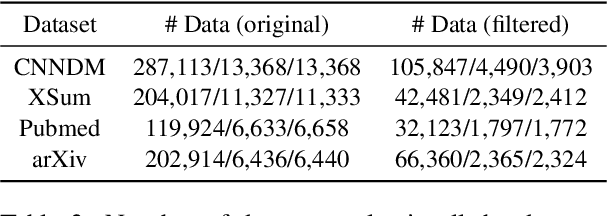
Despite the success of recent abstractive summarizers on automatic evaluation metrics, the generated summaries still present factual inconsistencies with the source document. In this paper, we focus on entity-level factual inconsistency, i.e. reducing the mismatched entities between the generated summaries and the source documents. We therefore propose a novel entity-based SpanCopy mechanism, and explore its extension with a Global Relevance component. Experiment results on four summarization datasets show that SpanCopy can effectively improve the entity-level factual consistency with essentially no change in the word-level and entity-level saliency. The code is available at https://github.com/Wendy-Xiao/Entity-based-SpanCopy
SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
Jan 12, 2022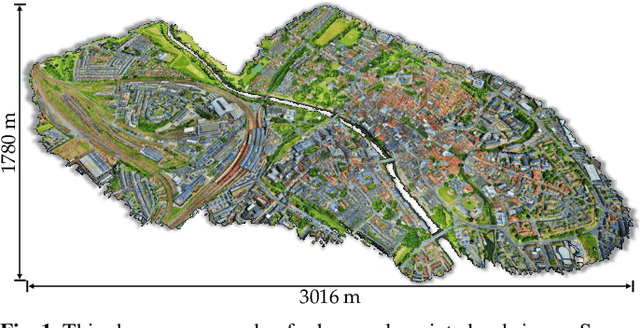
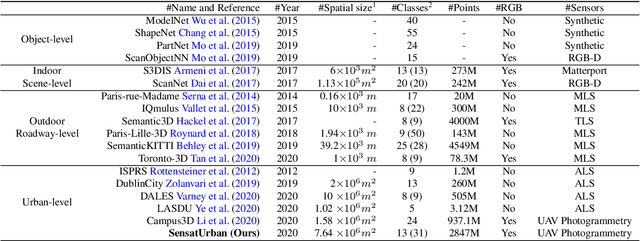

With the recent availability and affordability of commercial depth sensors and 3D scanners, an increasing number of 3D (i.e., RGBD, point cloud) datasets have been publicized to facilitate research in 3D computer vision. However, existing datasets either cover relatively small areas or have limited semantic annotations. Fine-grained understanding of urban-scale 3D scenes is still in its infancy. In this paper, we introduce SensatUrban, an urban-scale UAV photogrammetry point cloud dataset consisting of nearly three billion points collected from three UK cities, covering 7.6 km^2. Each point in the dataset has been labelled with fine-grained semantic annotations, resulting in a dataset that is three times the size of the previous existing largest photogrammetric point cloud dataset. In addition to the more commonly encountered categories such as road and vegetation, urban-level categories including rail, bridge, and river are also included in our dataset. Based on this dataset, we further build a benchmark to evaluate the performance of state-of-the-art segmentation algorithms. In particular, we provide a comprehensive analysis and identify several key challenges limiting urban-scale point cloud understanding. The dataset is available at http://point-cloud-analysis.cs.ox.ac.uk.