 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Multi-Agent Advantage
Jun 11, 2026Prevailing wisdom posits that Multi-Agent Systems (MAS) are superior to Single-Agent Systems (SAS), citing advantages like context protection, parallel processing and distributed decision-making. However, empirical support for this claim relies primarily on comparisons with SAS baselines using benchmarks that prioritize isolated reasoning tasks, which do not adequately assess these advantages. Focusing on automatically generated MAS that are designed for enhanced generalizability over manually-designed counterparts, we perform a rigorous, systematic evaluation against SAS, specifically Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and tasks with interactive multi-step workflows (e.g., BrowseComp-Plus), we demonstrate that automatic MAS consistently underperform CoT-SC despite being up to 10x more expensive. To isolate these failures from limitations inherent to task structure, we introduce a diagnostic synthetic dataset tailored for MAS featuring explicit task decomposition, context separation and parallelization potential. We show that expert-architected MAS consistently outperforms automatically generated architectures in both raw performance and cost-efficiency on this dataset, demonstrating that existing evaluation frameworks mask critical architectural gaps and inefficiencies of complex MAS by failing to account for the marginal utility of increased computational cost. Critically, systematic deconstruction of the generated MAS architectures reveals that current automated design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
BeDiscovER: The Benchmark of Discourse Understanding in the Era of Reasoning Language Models
Nov 17, 2025



We introduce BeDiscovER (Benchmark of Discourse Understanding in the Era of Reasoning Language Models), an up-to-date, comprehensive suite for evaluating the discourse-level knowledge of modern LLMs. BeDiscovER compiles 5 publicly available discourse tasks across discourse lexicon, (multi-)sentential, and documental levels, with in total 52 individual datasets. It covers both extensively studied tasks such as discourse parsing and temporal relation extraction, as well as some novel challenges such as discourse particle disambiguation (e.g., ``just''), and also aggregates a shared task on Discourse Relation Parsing and Treebanking for multilingual and multi-framework discourse relation classification. We evaluate open-source LLMs: Qwen3 series, DeepSeek-R1, and frontier model such as GPT-5-mini on BeDiscovER, and find that state-of-the-art models exhibit strong performance in arithmetic aspect of temporal reasoning, but they struggle with full document reasoning and some subtle semantic and discourse phenomena, such as rhetorical relation recognition.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


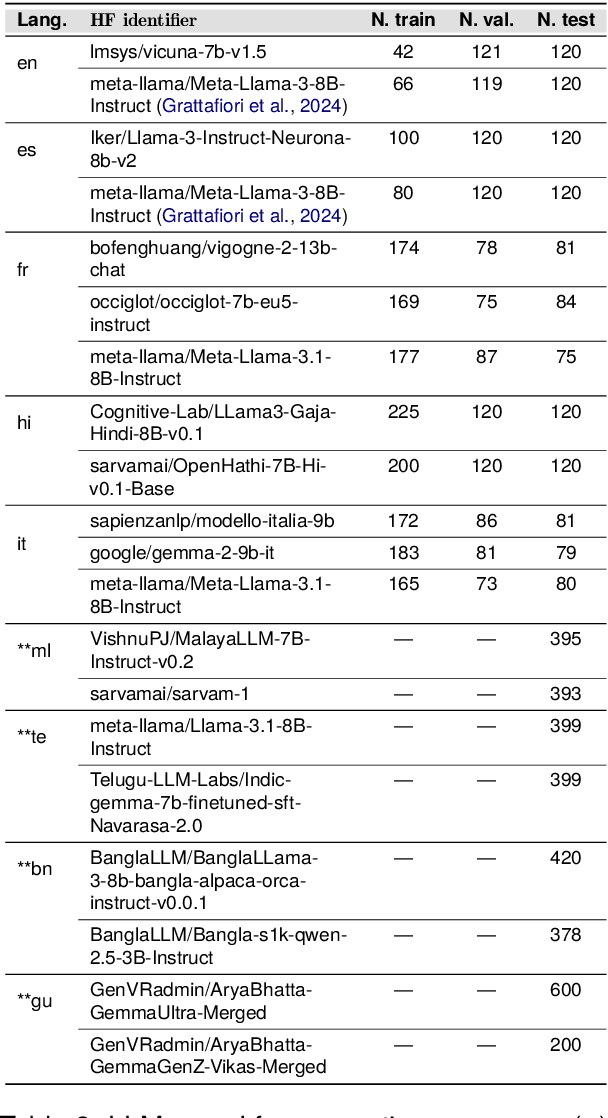
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
Multi$^2$: Multi-Agent Test-Time Scalable Framework for Multi-Document Processing
Feb 27, 2025



Recent advances in test-time scaling have shown promising results in improving Large Language Models (LLMs) performance through strategic computation allocation during inference. While this approach has demonstrated strong performance improvements in logical and mathematical reasoning tasks, its application to natural language generation (NLG), especially summarization, has yet to be explored. Multi-Document Summarization (MDS) is a challenging task that focuses on extracting and synthesizing useful information from multiple lengthy documents. Unlike reasoning tasks, MDS requires a more nuanced approach to prompt design and ensemble, as there is no "best" prompt to satisfy diverse summarization requirements. To address this, we propose a novel framework that leverages inference-time scaling for this task. Precisely, we take prompt ensemble approach by leveraging various prompt to first generate candidate summaries and then ensemble them with an aggregator to produce a refined summary. We also introduce two new evaluation metrics: Consistency-Aware Preference (CAP) score and LLM Atom-Content-Unit (ACU) score, to enhance LLM's contextual understanding while mitigating its positional bias. Extensive experiments demonstrate the effectiveness of our approach in improving summary quality while identifying and analyzing the scaling boundaries in summarization tasks.
Discourse Structure Extraction from Pre-Trained and Fine-Tuned Language Models in Dialogues
Feb 12, 2023



Discourse processing suffers from data sparsity, especially for dialogues. As a result, we explore approaches to build discourse structures for dialogues, based on attention matrices from Pre-trained Language Models (PLMs). We investigate multiple tasks for fine-tuning and show that the dialogue-tailored Sentence Ordering task performs best. To locate and exploit discourse information in PLMs, we propose an unsupervised and a semi-supervised method. Our proposals achieve encouraging results on the STAC corpus, with F1 scores of 57.2 and 59.3 for unsupervised and semi-supervised methods, respectively. When restricted to projective trees, our scores improved to 63.3 and 68.1.